 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracing the Data Trail: A Survey of Data Provenance, Transparency and Traceability in LLMs
Jan 19, 2026Large language models (LLMs) are deployed at scale, yet their training data life cycle remains opaque. This survey synthesizes research from the past ten years on three tightly coupled axes: (1) data provenance, (2) transparency, and (3) traceability, and three supporting pillars: (4) bias \& uncertainty, (5) data privacy, and (6) tools and techniques that operationalize them. A central contribution is a proposed taxonomy defining the field's domains and listing corresponding artifacts. Through analysis of 95 publications, this work identifies key methodologies concerning data generation, watermarking, bias measurement, data curation, data privacy, and the inherent trade-off between transparency and opacity.
Private and Fair Machine Learning: Revisiting the Disparate Impact of Differentially Private SGD
Oct 02, 2025Differential privacy (DP) is a prominent method for protecting information about individuals during data analysis. Training neural networks with differentially private stochastic gradient descent (DPSGD) influences the model's learning dynamics and, consequently, its output. This can affect the model's performance and fairness. While the majority of studies on the topic report a negative impact on fairness, it has recently been suggested that fairness levels comparable to non-private models can be achieved by optimizing hyperparameters for performance directly on differentially private models (rather than re-using hyperparameters from non-private models, as is common practice). In this work, we analyze the generalizability of this claim by 1) comparing the disparate impact of DPSGD on different performance metrics, and 2) analyzing it over a wide range of hyperparameter settings. We highlight that a disparate impact on one metric does not necessarily imply a disparate impact on another. Most importantly, we show that while optimizing hyperparameters directly on differentially private models does not mitigate the disparate impact of DPSGD reliably, it can still lead to improved utility-fairness trade-offs compared to re-using hyperparameters from non-private models. We stress, however, that any form of hyperparameter tuning entails additional privacy leakage, calling for careful considerations of how to balance privacy, utility and fairness. Finally, we extend our analyses to DPSGD-Global-Adapt, a variant of DPSGD designed to mitigate the disparate impact on accuracy, and conclude that this alternative may not be a robust solution with respect to hyperparameter choice.
On the Role of Priors in Bayesian Causal Learning
Apr 02, 2025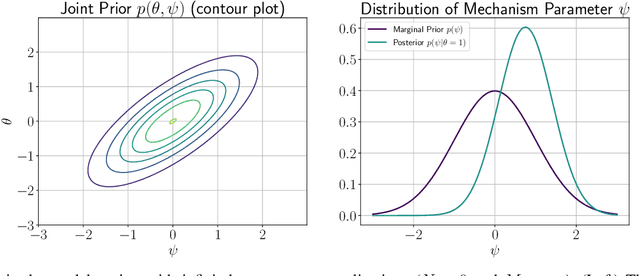
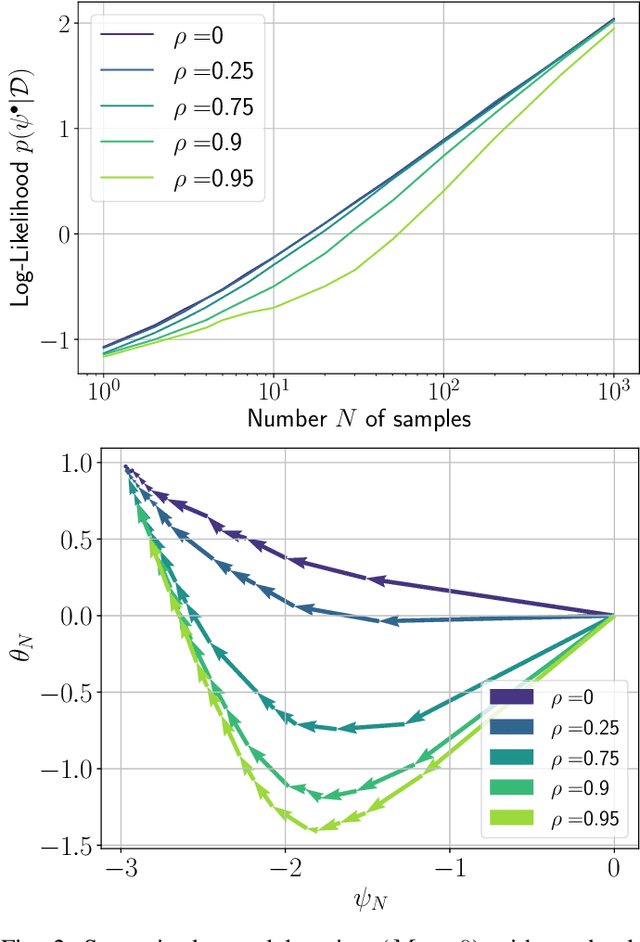
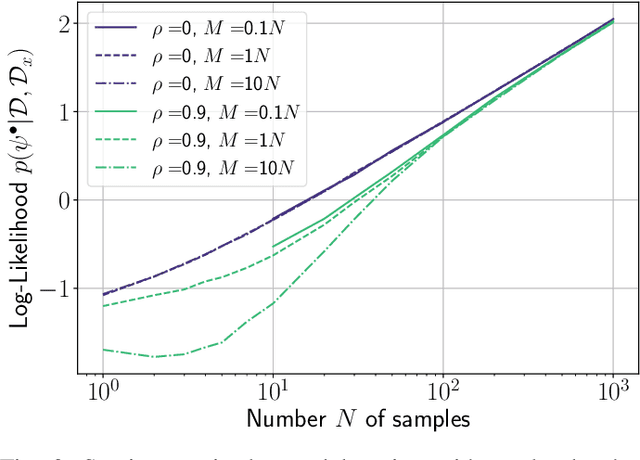
In this work, we investigate causal learning of independent causal mechanisms from a Bayesian perspective. Confirming previous claims from the literature, we show in a didactically accessible manner that unlabeled data (i.e., cause realizations) do not improve the estimation of the parameters defining the mechanism. Furthermore, we observe the importance of choosing an appropriate prior for the cause and mechanism parameters, respectively. Specifically, we show that a factorized prior results in a factorized posterior, which resonates with Janzing and Sch\"olkopf's definition of independent causal mechanisms via the Kolmogorov complexity of the involved distributions and with the concept of parameter independence of Heckerman et al.
Four Guiding Principles for Modeling Causal Domain Knowledge: A Case Study on Brainstorming Approaches for Urban Blight Analysis
Dec 03, 2024Urban blight is a problem of high interest for planning and policy making. Researchers frequently propose theories about the relationships between urban blight indicators, focusing on relationships reflecting causality. In this paper, we improve on the integration of domain knowledge in the analysis of urban blight by introducing four rules for effective modeling of causal domain knowledge. The findings of this study reveal significant deviation from causal modeling guidelines by investigating cognitive maps developed for urban blight analysis. These findings provide valuable insights that will inform future work on urban blight, ultimately enhancing our understanding of urban blight complex interactions.
Ensemble Watermarks for Large Language Models
Nov 29, 2024The rapid advancement of large language models (LLMs) has made it increasingly difficult to distinguish between text written by humans and machines. While watermarks already exist for LLMs, they often lack flexibility, and struggle with attacks such as paraphrasing. To address these issues, we propose a multi-feature method for generating watermarks that combines multiple distinct watermark features into an ensemble watermark. Concretely, we combine acrostica and sensorimotor norms with the established red-green watermark to achieve a 98% detection rate. After a paraphrasing attack the performance remains high with 95% detection rate. The red-green feature alone as baseline achieves a detection rate of 49%. The evaluation of all feature combinations reveals that the ensemble of all three consistently has the highest detection rate across several LLMs and watermark strength settings. Due to the flexibility of combining features in the ensemble, various requirements and trade-offs can be addressed. Additionally, for all ensemble configurations the same detection function can be used without adaptations. This method is particularly of interest to facilitate accountability and prevent societal harm.
Evaluating Large Language Models for Causal Modeling
Nov 24, 2024
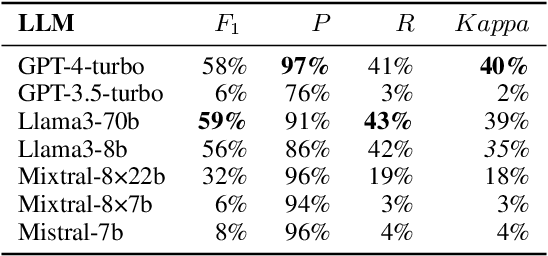

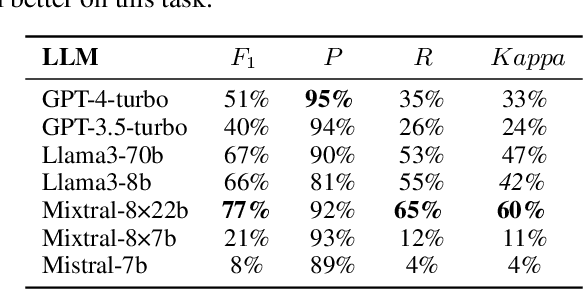
In this paper, we consider the process of transforming causal domain knowledge into a representation that aligns more closely with guidelines from causal data science. To this end, we introduce two novel tasks related to distilling causal domain knowledge into causal variables and detecting interaction entities using LLMs. We have determined that contemporary LLMs are helpful tools for conducting causal modeling tasks in collaboration with human experts, as they can provide a wider perspective. Specifically, LLMs, such as GPT-4-turbo and Llama3-70b, perform better in distilling causal domain knowledge into causal variables compared to sparse expert models, such as Mixtral-8x22b. On the contrary, sparse expert models such as Mixtral-8x22b stand out as the most effective in identifying interaction entities. Finally, we highlight the dependency between the domain where the entities are generated and the performance of the chosen LLM for causal modeling.
Increasing the Accessibility of Causal Domain Knowledge via Causal Information Extraction Methods: A Case Study in the Semiconductor Manufacturing Industry
Nov 15, 2024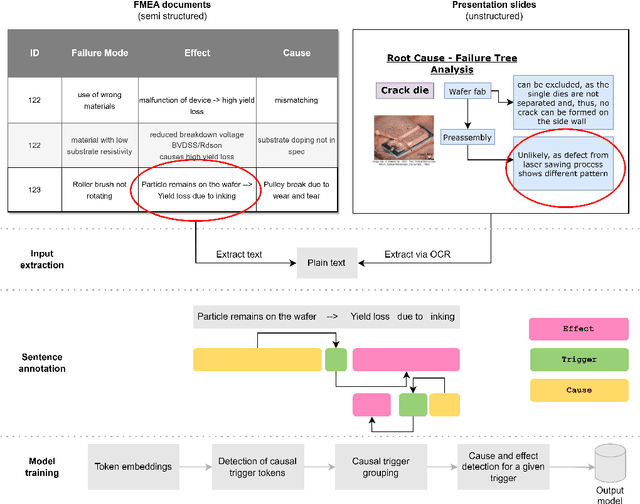
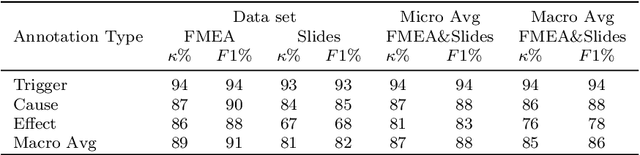
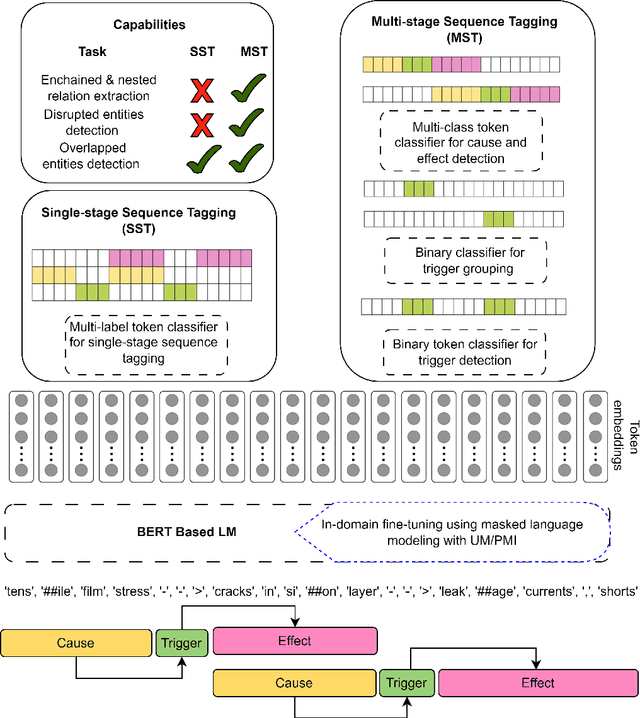
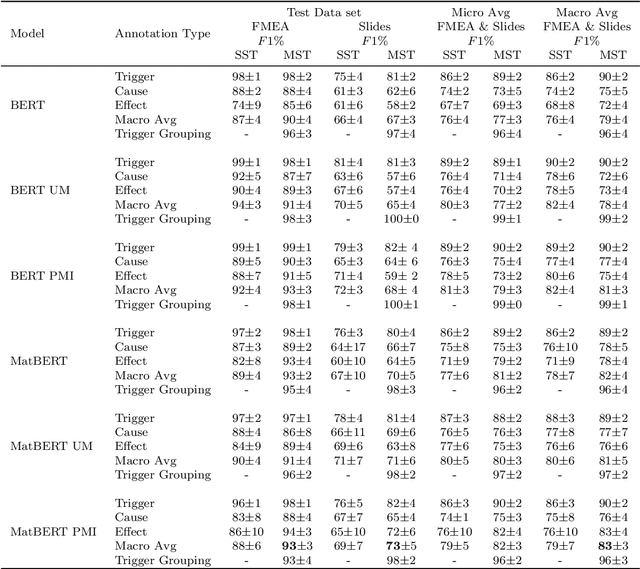
The extraction of causal information from textual data is crucial in the industry for identifying and mitigating potential failures, enhancing process efficiency, prompting quality improvements, and addressing various operational challenges. This paper presents a study on the development of automated methods for causal information extraction from actual industrial documents in the semiconductor manufacturing industry. The study proposes two types of causal information extraction methods, single-stage sequence tagging (SST) and multi-stage sequence tagging (MST), and evaluates their performance using existing documents from a semiconductor manufacturing company, including presentation slides and FMEA (Failure Mode and Effects Analysis) documents. The study also investigates the effect of representation learning on downstream tasks. The presented case study showcases that the proposed MST methods for extracting causal information from industrial documents are suitable for practical applications, especially for semi structured documents such as FMEAs, with a 93\% F1 score. Additionally, MST achieves a 73\% F1 score on texts extracted from presentation slides. Finally, the study highlights the importance of choosing a language model that is more aligned with the domain and in-domain fine-tuning.
Establishing and Evaluating Trustworthy AI: Overview and Research Challenges
Nov 15, 2024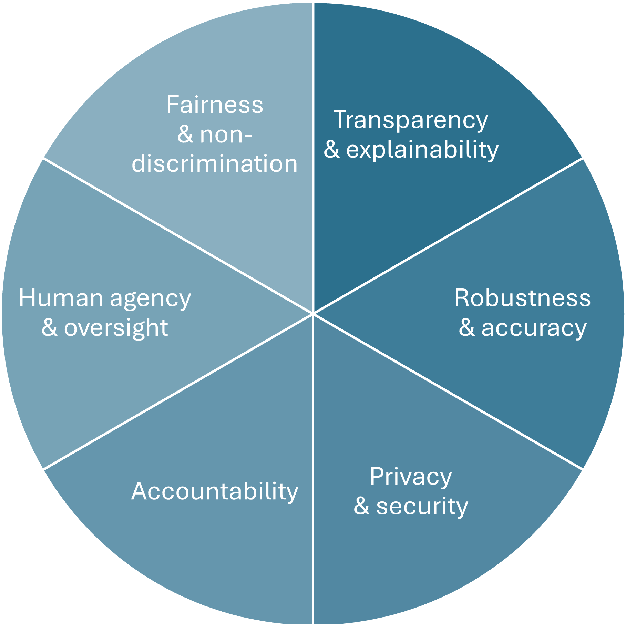


Artificial intelligence (AI) technologies (re-)shape modern life, driving innovation in a wide range of sectors. However, some AI systems have yielded unexpected or undesirable outcomes or have been used in questionable manners. As a result, there has been a surge in public and academic discussions about aspects that AI systems must fulfill to be considered trustworthy. In this paper, we synthesize existing conceptualizations of trustworthy AI along six requirements: 1) human agency and oversight, 2) fairness and non-discrimination, 3) transparency and explainability, 4) robustness and accuracy, 5) privacy and security, and 6) accountability. For each one, we provide a definition, describe how it can be established and evaluated, and discuss requirement-specific research challenges. Finally, we conclude this analysis by identifying overarching research challenges across the requirements with respect to 1) interdisciplinary research, 2) conceptual clarity, 3) context-dependency, 4) dynamics in evolving systems, and 5) investigations in real-world contexts. Thus, this paper synthesizes and consolidates a wide-ranging and active discussion currently taking place in various academic sub-communities and public forums. It aims to serve as a reference for a broad audience and as a basis for future research directions.
Constraining Anomaly Detection with Anomaly-Free Regions
Sep 30, 2024



We propose the novel concept of anomaly-free regions (AFR) to improve anomaly detection. An AFR is a region in the data space for which it is known that there are no anomalies inside it, e.g., via domain knowledge. This region can contain any number of normal data points and can be anywhere in the data space. AFRs have the key advantage that they constrain the estimation of the distribution of non-anomalies: The estimated probability mass inside the AFR must be consistent with the number of normal data points inside the AFR. Based on this insight, we provide a solid theoretical foundation and a reference implementation of anomaly detection using AFRs. Our empirical results confirm that anomaly detection constrained via AFRs improves upon unconstrained anomaly detection. Specifically, we show that, when equipped with an estimated AFR, an efficient algorithm based on random guessing becomes a strong baseline that several widely-used methods struggle to overcome. On a dataset with a ground-truth AFR available, the current state of the art is outperformed.
Stylometric Watermarks for Large Language Models
May 14, 2024The rapid advancement of large language models (LLMs) has made it increasingly difficult to distinguish between text written by humans and machines. Addressing this, we propose a novel method for generating watermarks that strategically alters token probabilities during generation. Unlike previous works, this method uniquely employs linguistic features such as stylometry. Concretely, we introduce acrostica and sensorimotor norms to LLMs. Further, these features are parameterized by a key, which is updated every sentence. To compute this key, we use semantic zero shot classification, which enhances resilience. In our evaluation, we find that for three or more sentences, our method achieves a false positive and false negative rate of 0.02. For the case of a cyclic translation attack, we observe similar results for seven or more sentences. This research is of particular of interest for proprietary LLMs to facilitate accountability and prevent societal harm.