 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhose Name Comes Up? III: Persona Prompting Effects in LLM-Based Scholar Recommendation
May 27, 2026Large language models (LLMs) are increasingly used as scholar recommenders, shaping who is seen as an expert in academia. Existing audits remain English-centric, single discipline, and persona-agnostic, leaving the source of output variability poorly understood. To this end, we propose a benchmark that disentangles the effects of model choice and prompt design on recommendations. We audit 43 LLMs by varying persona prompts (language, location, role-and-task) and context (field, seniority, k). Recommended scholars are compared against Semantic Scholar over six scientific disciplines to measure technical quality (factuality, coverage) and social representativeness (diversity, parity). Basic technical quality is driven by model choice, factuality and parity by context, and diversity by location. South Africa prompts yield less factual lists, while Japan prompts yield highly factual but homogeneous lists skewed toward highly productive scholars. Prompt design is thus a non-trivial axis of LLM-based scholar discovery and should be systematically audited alongside model choice.
Fair Agents: Balancing Multistakeholder Alignment in Multi-Agent Personalization Systems
May 04, 2026LLM agents are increasingly used for personalization due to their ability to communicate directly with users in natural language, integrate external knowledge bases, and negotiate with other (possibly human) agents. Especially in multistakeholder AI systems with multiple distinct objectives, LLM agents are used to independently optimize for each stakeholder's goals. Here, stakeholder alignment is essential to identify and map these goals to provide LLM agents with quantifiable objectives. Plus, the way in which the outputs of the LLM agents are aggregated is fundamental to ensuring fair outcomes for all agents and, therefore, stakeholders. In this work, we identify open research challenges and propose a conceptual framework for designing fair multi-agent multistakeholder personalization systems that balance competing stakeholder objectives. Our framework integrates (i) methods to align stakeholder objectives and LLM agents, (ii) aggregation strategies, e.g., based on social choice theory, to form fair collective decisions, and (iii) stakeholder-centric evaluation procedures for both individual and collective agent behavior. We showcase our framework through a tourism use case and discuss possible applications in other domains, such as education and healthcare. Finally, we discuss domain-specific fairness tensions and review datasets for evaluating multistakeholder fairness and multi-agent personalization systems.
Large Language Models as Narrative-Driven Recommenders
Oct 17, 2024Narrative-driven recommenders aim to provide personalized suggestions for user requests expressed in free-form text such as "I want to watch a thriller with a mind-bending story, like Shutter Island." Although large language models (LLMs) have been shown to excel in processing general natural language queries, their effectiveness for handling such recommendation requests remains relatively unexplored. To close this gap, we compare the performance of 38 open- and closed-source LLMs of various sizes, such as LLama 3.2 and GPT-4o, in a movie recommendation setting. For this, we utilize a gold-standard, crowdworker-annotated dataset of posts from reddit's movie suggestion community and employ various prompting strategies, including zero-shot, identity, and few-shot prompting. Our findings demonstrate the ability of LLMs to generate contextually relevant movie recommendations, significantly outperforming other state-of-the-art approaches, such as doc2vec. While we find that closed-source and large-parameterized models generally perform best, medium-sized open-source models remain competitive, being only slightly outperformed by their more computationally expensive counterparts. Furthermore, we observe no significant differences across prompting strategies for most models, underscoring the effectiveness of simple approaches such as zero-shot prompting for narrative-driven recommendations. Overall, this work offers valuable insights for recommender system researchers as well as practitioners aiming to integrate LLMs into real-world recommendation tools.
Recommendation Fairness in Social Networks Over Time
Feb 05, 2024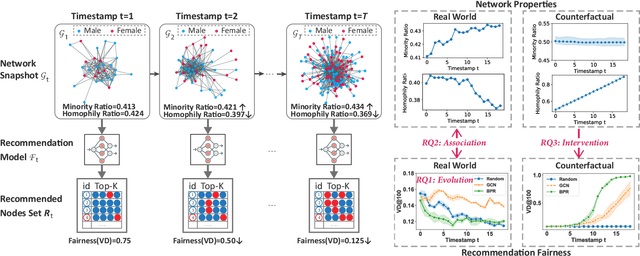
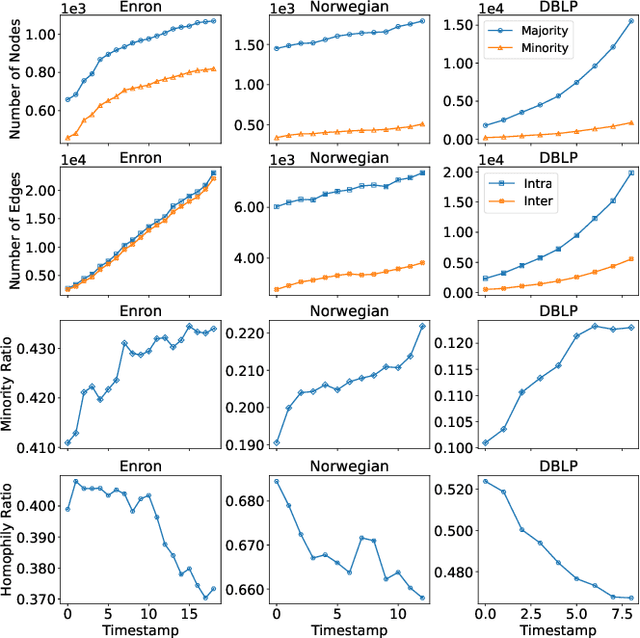
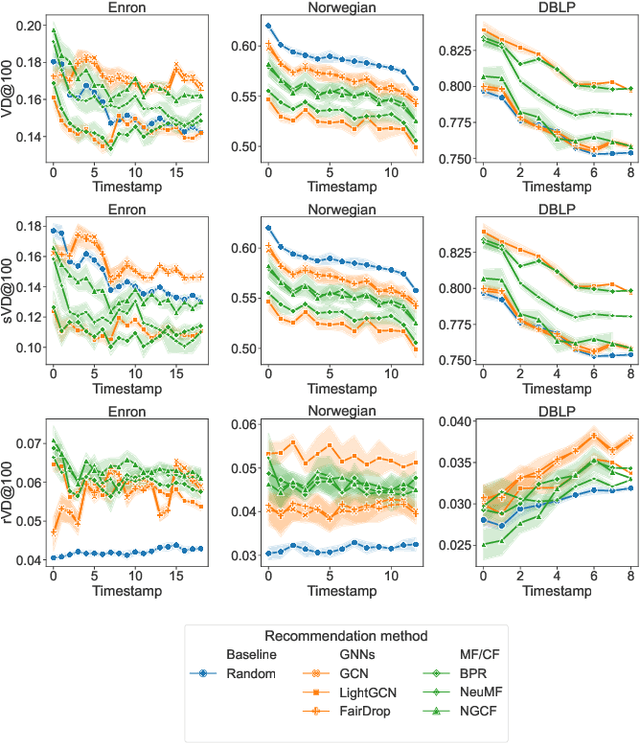
In social recommender systems, it is crucial that the recommendation models provide equitable visibility for different demographic groups, such as gender or race. Most existing research has addressed this problem by only studying individual static snapshots of networks that typically change over time. To address this gap, we study the evolution of recommendation fairness over time and its relation to dynamic network properties. We examine three real-world dynamic networks by evaluating the fairness of six recommendation algorithms and analyzing the association between fairness and network properties over time. We further study how interventions on network properties influence fairness by examining counterfactual scenarios with alternative evolution outcomes and differing network properties. Our results on empirical datasets suggest that recommendation fairness improves over time, regardless of the recommendation method. We also find that two network properties, minority ratio, and homophily ratio, exhibit stable correlations with fairness over time. Our counterfactual study further suggests that an extreme homophily ratio potentially contributes to unfair recommendations even with a balanced minority ratio. Our work provides insights into the evolution of fairness within dynamic networks in social science. We believe that our findings will help system operators and policymakers to better comprehend the implications of temporal changes and interventions targeting fairness in social networks.
Adversarial Inter-Group Link Injection Degrades the Fairness of Graph Neural Networks
Sep 13, 2022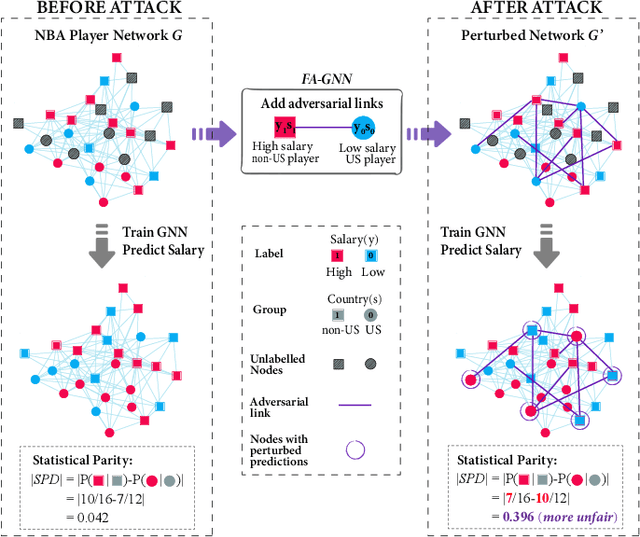
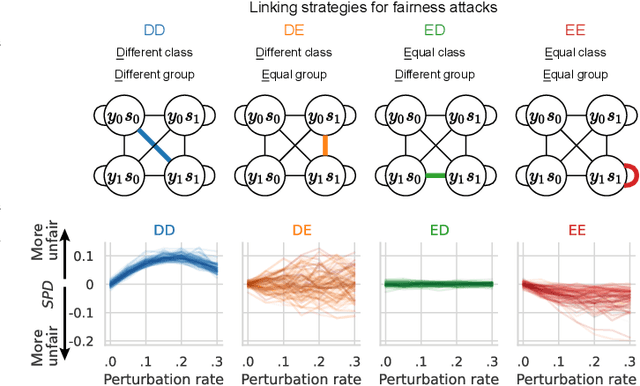
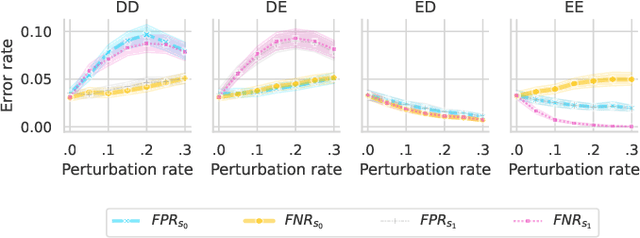
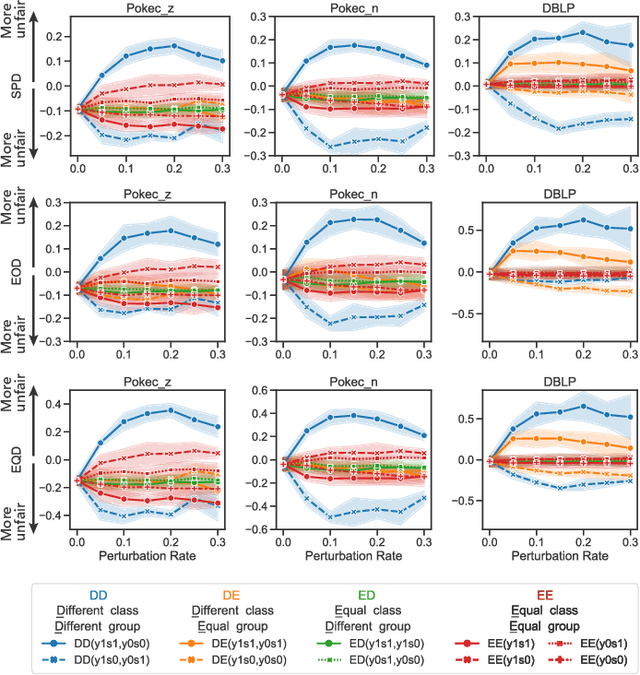
We present evidence for the existence and effectiveness of adversarial attacks on graph neural networks (GNNs) that aim to degrade fairness. These attacks can disadvantage a particular subgroup of nodes in GNN-based node classification, where nodes of the underlying network have sensitive attributes, such as race or gender. We conduct qualitative and experimental analyses explaining how adversarial link injection impairs the fairness of GNN predictions. For example, an attacker can compromise the fairness of GNN-based node classification by injecting adversarial links between nodes belonging to opposite subgroups and opposite class labels. Our experiments on empirical datasets demonstrate that adversarial fairness attacks can significantly degrade the fairness of GNN predictions (attacks are effective) with a low perturbation rate (attacks are efficient) and without a significant drop in accuracy (attacks are deceptive). This work demonstrates the vulnerability of GNN models to adversarial fairness attacks. We hope our findings raise awareness about this issue in our community and lay a foundation for the future development of GNN models that are more robust to such attacks.
Structack: Structure-based Adversarial Attacks on Graph Neural Networks
Jul 28, 2021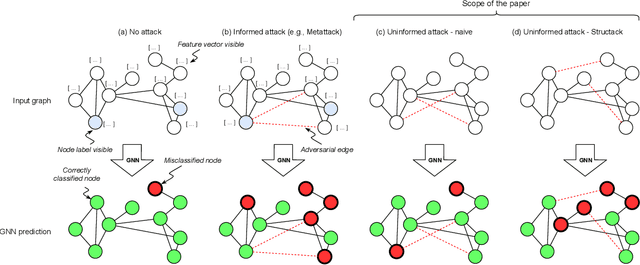
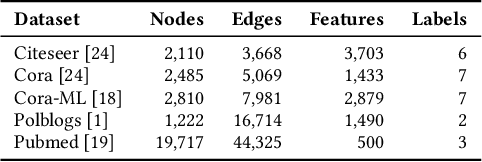
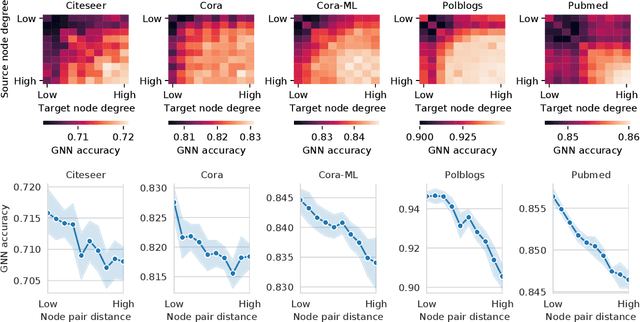

Recent work has shown that graph neural networks (GNNs) are vulnerable to adversarial attacks on graph data. Common attack approaches are typically informed, i.e. they have access to information about node attributes such as labels and feature vectors. In this work, we study adversarial attacks that are uninformed, where an attacker only has access to the graph structure, but no information about node attributes. Here the attacker aims to exploit structural knowledge and assumptions, which GNN models make about graph data. In particular, literature has shown that structural node centrality and similarity have a strong influence on learning with GNNs. Therefore, we study the impact of centrality and similarity on adversarial attacks on GNNs. We demonstrate that attackers can exploit this information to decrease the performance of GNNs by focusing on injecting links between nodes of low similarity and, surprisingly, low centrality. We show that structure-based uninformed attacks can approach the performance of informed attacks, while being computationally more efficient. With our paper, we present a new attack strategy on GNNs that we refer to as Structack. Structack can successfully manipulate the performance of GNNs with very limited information while operating under tight computational constraints. Our work contributes towards building more robust machine learning approaches on graphs.
RFID-based Article-to-Fixture Predictions in Real-World Fashion Stores
May 21, 2021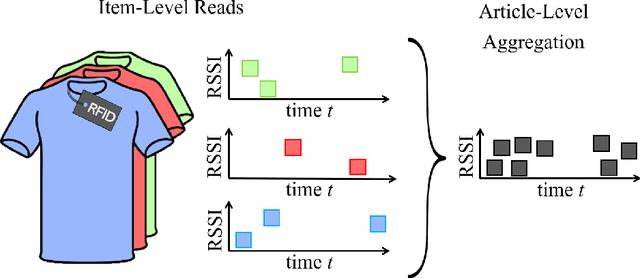

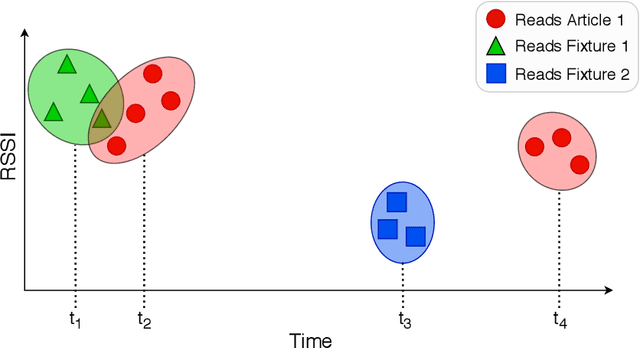

In recent years, Radio Frequency Identification (RFID) technology has been applied to improve numerous processes, such as inventory management in retail stores. However, automatic localization of RFID-tagged goods in stores is still a challenging problem. To address this issue, we equip fixtures (e.g., shelves) with reference tags and use data we collect during RFID-based stocktakes to map articles to fixtures. Knowing the location of goods enables the implementation of several practical applications, such as automated Money Mapping (i.e., a heat map of sales across fixtures). Specifically, we conduct controlled lab experiments and a case-study in two fashion retail stores to evaluate our article-to-fixture prediction approaches. The approaches are based on calculating distances between read event time series using DTW, and clustering of read events using DBSCAN. We find that, read events collected during RFID-based stocktakes can be used to assign articles to fixtures with an accuracy of more than 90%. Additionally, we conduct a pilot to investigate the challenges related to the integration of such a localization system in the day-to-day business of retail stores. Hence, in this paper we present an exploratory venture into novel and practical RFID-based applications in fashion retails stores, beyond the scope of stock management.
Surfacing Estimation Uncertainty in the Decay Parameters of Hawkes Processes with Exponential Kernels
Apr 02, 2021
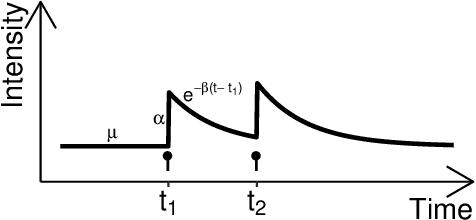
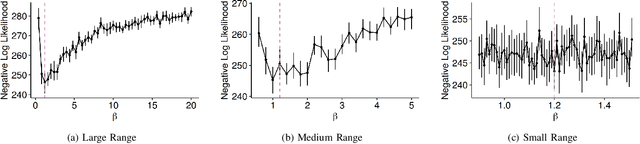
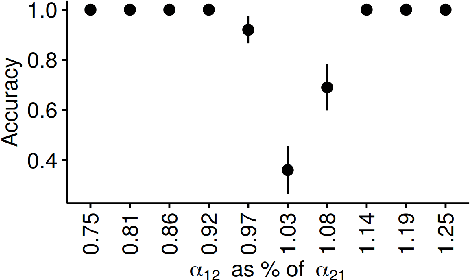
As a tool for capturing irregular temporal dependencies (rather than resorting to binning temporal observations to construct time series), Hawkes processes with exponential decay have seen widespread adoption across many application domains, such as predicting the occurrence time of the next earthquake or stock market spike. However, practical applications of Hawkes processes face a noteworthy challenge: There is substantial and often unquantified variance in decay parameter estimations, especially in the case of a small number of observations or when the dynamics behind the observed data suddenly change. We empirically study the cause of these practical challenges and we develop an approach to surface and thereby mitigate them. In particular, our inspections of the Hawkes process likelihood function uncover the properties of the uncertainty when fitting the decay parameter. We thus propose to explicitly capture this uncertainty within a Bayesian framework. With a series of experiments with synthetic and real-world data from domains such as "classical" earthquake modeling or the manifestation of collective emotions on Twitter, we demonstrate that our proposed approach helps to quantify uncertainty and thereby to understand and fit Hawkes processes in practice.
Synwalk -- Community Detection via Random Walk Modelling
Jan 21, 2021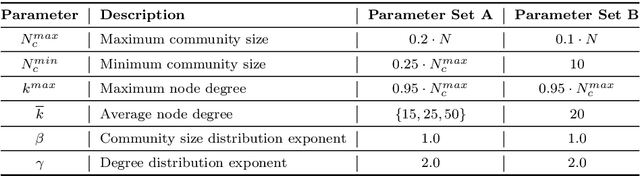


Complex systems, abstractly represented as networks, are ubiquitous in everyday life. Analyzing and understanding these systems requires, among others, tools for community detection. As no single best community detection algorithm can exist, robustness across a wide variety of problem settings is desirable. In this work, we present Synwalk, a random walk-based community detection method. Synwalk builds upon a solid theoretical basis and detects communities by synthesizing the random walk induced by the given network from a class of candidate random walks. We thoroughly validate the effectiveness of our approach on synthetic and empirical networks, respectively, and compare Synwalk's performance with the performance of Infomap and Walktrap. Our results indicate that Synwalk performs robustly on networks with varying mixing parameters and degree distributions. We outperform Infomap on networks with high mixing parameter, and Infomap and Walktrap on networks with many small communities and low average degree. Our work has a potential to inspire further development of community detection via synthesis of random walks and we provide concrete ideas for future research.
On the Impact of Communities on Semi-supervised Classification Using Graph Neural Networks
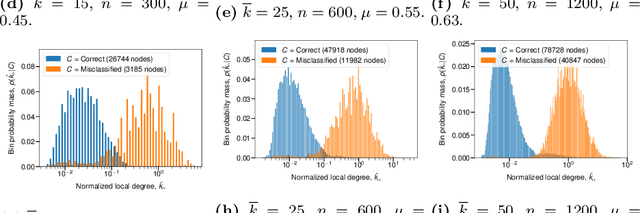
Oct 30, 2020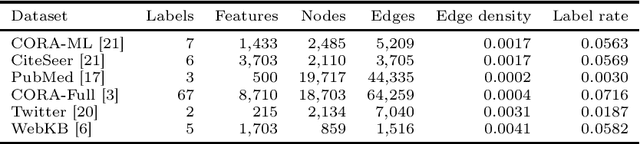
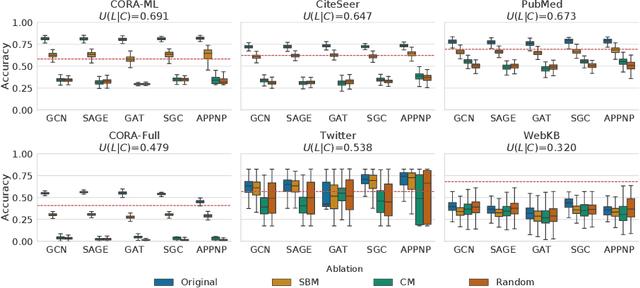
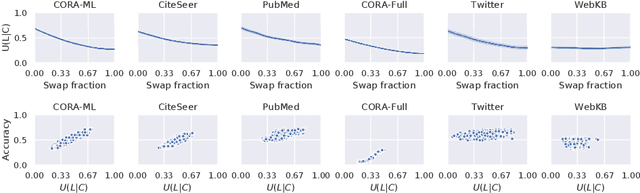
Graph Neural Networks (GNNs) are effective in many applications. Still, there is a limited understanding of the effect of common graph structures on the learning process of GNNs. In this work, we systematically study the impact of community structure on the performance of GNNs in semi-supervised node classification on graphs. Following an ablation study on six datasets, we measure the performance of GNNs on the original graphs, and the change in performance in the presence and the absence of community structure. Our results suggest that communities typically have a major impact on the learning process and classification performance. For example, in cases where the majority of nodes from one community share a single classification label, breaking up community structure results in a significant performance drop. On the other hand, for cases where labels show low correlation with communities, we find that the graph structure is rather irrelevant to the learning process, and a feature-only baseline becomes hard to beat. With our work, we provide deeper insights in the abilities and limitations of GNNs, including a set of general guidelines for model selection based on the graph structure.