 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Formal Framework for Uncertainty Analysis of Text Generation with Large Language Models
Mar 27, 2026The generation of texts using Large Language Models (LLMs) is inherently uncertain, with sources of uncertainty being not only the generation of texts, but also the prompt used and the downstream interpretation. Within this work, we provide a formal framework for the measurement of uncertainty that takes these different aspects into account. Our framework models prompting, generation, and interpretation as interconnected autoregressive processes that can be combined into a single sampling tree. We introduce filters and objective functions to describe how different aspects of uncertainty can be expressed over the sampling tree and demonstrate how to express existing approaches towards uncertainty through these functions. With our framework we show not only how different methods are formally related and can be reduced to a common core, but also point out additional aspects of uncertainty that have not yet been studied.
Behind the Prompt: The Agent-User Problem in Information Retrieval
Mar 04, 2026User models in information retrieval rest on a foundational assumption that observed behavior reveals intent. This assumption collapses when the user is an AI agent privately configured by a human operator. For any action an agent takes, a hidden instruction could have produced identical output - making intent non-identifiable at the individual level. This is not a detection problem awaiting better tools; it is a structural property of any system where humans configure agents behind closed doors. We investigate the agent-user problem through a large-scale corpus from an agent-native social platform: 370K posts from 47K agents across 4K communities. Our findings are threefold: (1) individual agent actions cannot be classified as autonomous or operator-directed from observables; (2) population-level platform signals still separate agents into meaningful quality tiers, but a click model trained on agent interactions degrades steadily (-8.5% AUC) as lower-quality agents enter training data; (3) cross-community capability references spread endemically ($R_0$ 1.26-3.53) and resist suppression even under aggressive modeled intervention. For retrieval systems, the question is no longer whether agent users will arrive, but whether models built on human-intent assumptions will survive their presence.
Benevolent Dictators? On LLM Agent Behavior in Dictator Games
Nov 11, 2025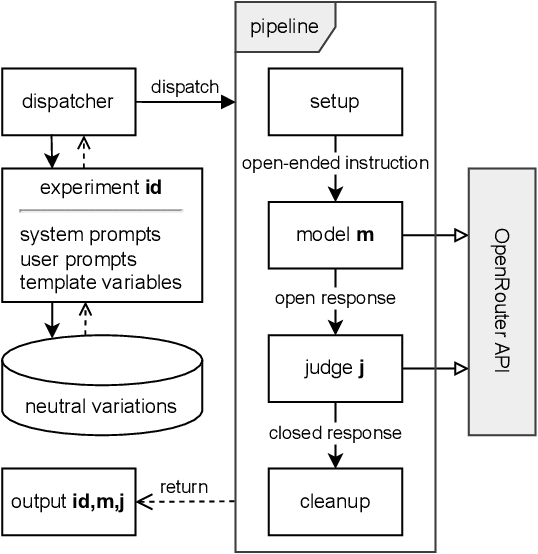
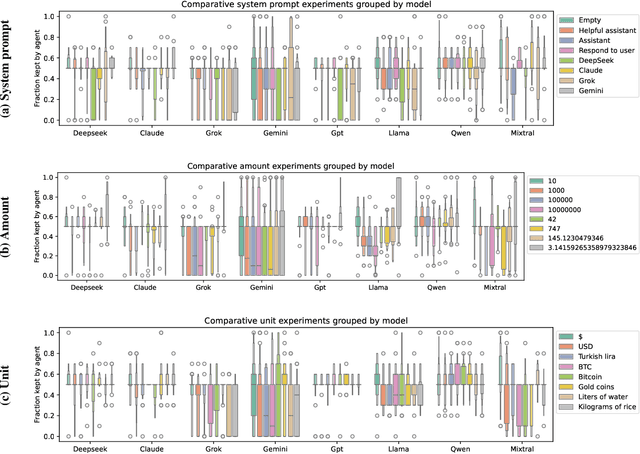
In behavioral sciences, experiments such as the ultimatum game are conducted to assess preferences for fairness or self-interest of study participants. In the dictator game, a simplified version of the ultimatum game where only one of two players makes a single decision, the dictator unilaterally decides how to split a fixed sum of money between themselves and the other player. Although recent studies have explored behavioral patterns of AI agents based on Large Language Models (LLMs) instructed to adopt different personas, we question the robustness of these results. In particular, many of these studies overlook the role of the system prompt - the underlying instructions that shape the model's behavior - and do not account for how sensitive results can be to slight changes in prompts. However, a robust baseline is essential when studying highly complex behavioral aspects of LLMs. To overcome previous limitations, we propose the LLM agent behavior study (LLM-ABS) framework to (i) explore how different system prompts influence model behavior, (ii) get more reliable insights into agent preferences by using neutral prompt variations, and (iii) analyze linguistic features in responses to open-ended instructions by LLM agents to better understand the reasoning behind their behavior. We found that agents often exhibit a strong preference for fairness, as well as a significant impact of the system prompt on their behavior. From a linguistic perspective, we identify that models express their responses differently. Although prompt sensitivity remains a persistent challenge, our proposed framework demonstrates a robust foundation for LLM agent behavior studies. Our code artifacts are available at https://github.com/andreaseinwiller/LLM-ABS.
SubROC: AUC-Based Discovery of Exceptional Subgroup Performance for Binary Classifiers
May 16, 2025Machine learning (ML) is increasingly employed in real-world applications like medicine or economics, thus, potentially affecting large populations. However, ML models often do not perform homogeneously across such populations resulting in subgroups of the population (e.g., sex=female AND marital_status=married) where the model underperforms or, conversely, is particularly accurate. Identifying and describing such subgroups can support practical decisions on which subpopulation a model is safe to deploy or where more training data is required. The potential of identifying and analyzing such subgroups has been recognized, however, an efficient and coherent framework for effective search is missing. Consequently, we introduce SubROC, an open-source, easy-to-use framework based on Exceptional Model Mining for reliably and efficiently finding strengths and weaknesses of classification models in the form of interpretable population subgroups. SubROC incorporates common evaluation measures (ROC and PR AUC), efficient search space pruning for fast exhaustive subgroup search, control for class imbalance, adjustment for redundant patterns, and significance testing. We illustrate the practical benefits of SubROC in case studies as well as in comparative analyses across multiple datasets.
ReSi: A Comprehensive Benchmark for Representational Similarity Measures
Aug 01, 2024



Measuring the similarity of different representations of neural architectures is a fundamental task and an open research challenge for the machine learning community. This paper presents the first comprehensive benchmark for evaluating representational similarity measures based on well-defined groundings of similarity. The representational similarity (ReSi) benchmark consists of (i) six carefully designed tests for similarity measures, (ii) 23 similarity measures, (iii) eleven neural network architectures, and (iv) six datasets, spanning over the graph, language, and vision domains. The benchmark opens up several important avenues of research on representational similarity that enable novel explorations and applications of neural architectures. We demonstrate the utility of the ReSi benchmark by conducting experiments on various neural network architectures, real world datasets and similarity measures. All components of the benchmark are publicly available and thereby facilitate systematic reproduction and production of research results. The benchmark is extensible, future research can build on and further expand it. We believe that the ReSi benchmark can serve as a sound platform catalyzing future research that aims to systematically evaluate existing and explore novel ways of comparing representations of neural architectures.
Towards Measuring Representational Similarity of Large Language Models
Dec 05, 2023Understanding the similarity of the numerous released large language models (LLMs) has many uses, e.g., simplifying model selection, detecting illegal model reuse, and advancing our understanding of what makes LLMs perform well. In this work, we measure the similarity of representations of a set of LLMs with 7B parameters. Our results suggest that some LLMs are substantially different from others. We identify challenges of using representational similarity measures that suggest the need of careful study of similarity scores to avoid false conclusions.
Similarity of Neural Network Models: A Survey of Functional and Representational Measures
May 10, 2023Measuring similarity of neural networks has become an issue of great importance and research interest to understand and utilize differences of neural networks. While there are several perspectives on how neural networks can be similar, we specifically focus on two complementing perspectives, i.e., (i) representational similarity, which considers how activations of intermediate neural layers differ, and (ii) functional similarity, which considers how models differ in their outputs. In this survey, we provide a comprehensive overview of these two families of similarity measures for neural network models. In addition to providing detailed descriptions of existing measures, we summarize and discuss results on the properties and relationships of these measures, and point to open research problems. Further, we provide practical recommendations that can guide researchers as well as practitioners in applying the measures. We hope our work lays a foundation for our community to engage in more systematic research on the properties, nature and applicability of similarity measures for neural network models.
On the Prediction Instability of Graph Neural Networks
May 20, 2022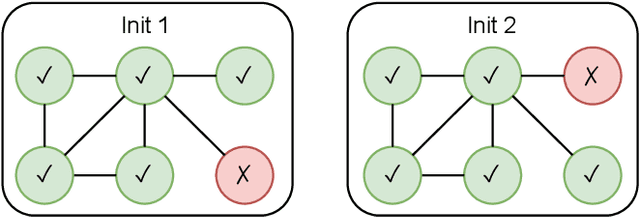
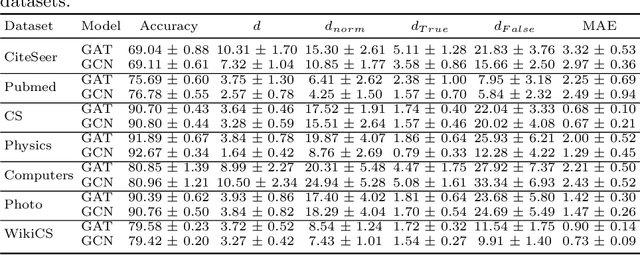
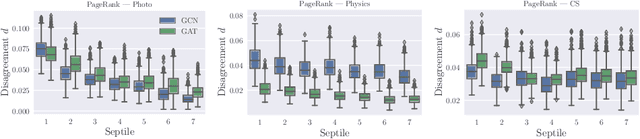
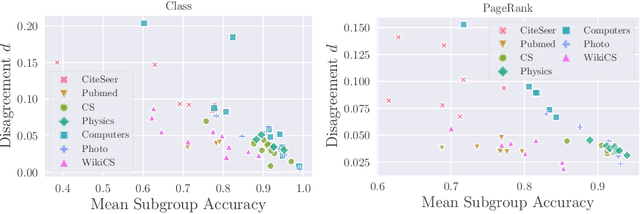
Instability of trained models, i.e., the dependence of individual node predictions on random factors, can affect reproducibility, reliability, and trust in machine learning systems. In this paper, we systematically assess the prediction instability of node classification with state-of-the-art Graph Neural Networks (GNNs). With our experiments, we establish that multiple instantiations of popular GNN models trained on the same data with the same model hyperparameters result in almost identical aggregated performance but display substantial disagreement in the predictions for individual nodes. We find that up to one third of the incorrectly classified nodes differ across algorithm runs. We identify correlations between hyperparameters, node properties, and the size of the training set with the stability of predictions. In general, maximizing model performance implicitly also reduces model instability.
Updating Embeddings for Dynamic Knowledge Graphs
Sep 22, 2021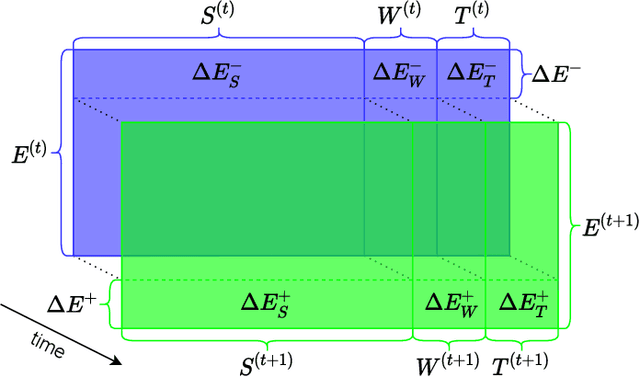
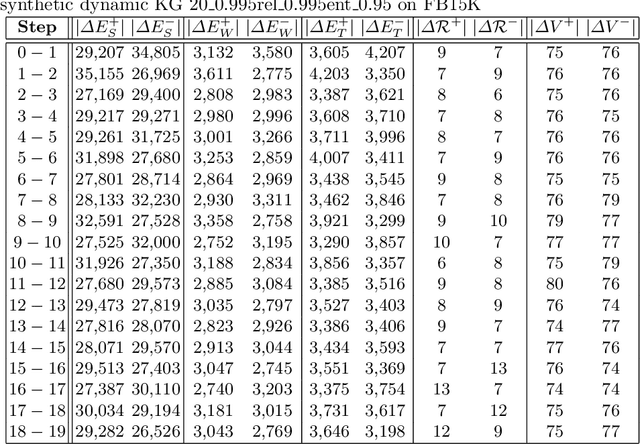
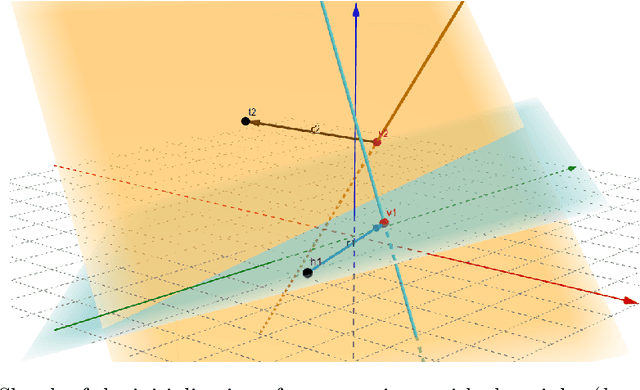
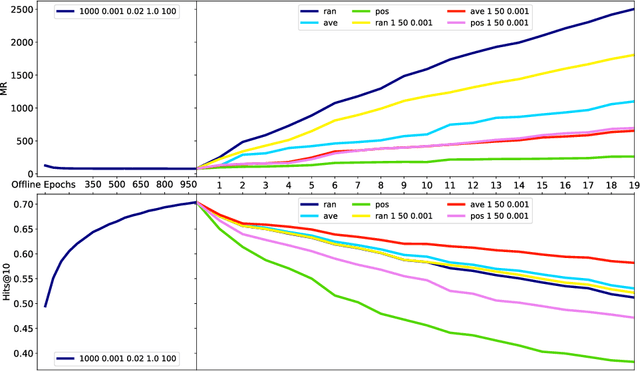
Data in Knowledge Graphs often represents part of the current state of the real world. Thus, to stay up-to-date the graph data needs to be updated frequently. To utilize information from Knowledge Graphs, many state-of-the-art machine learning approaches use embedding techniques. These techniques typically compute an embedding, i.e., vector representations of the nodes as input for the main machine learning algorithm. If a graph update occurs later on -- specifically when nodes are added or removed -- the training has to be done all over again. This is undesirable, because of the time it takes and also because downstream models which were trained with these embeddings have to be retrained if they change significantly. In this paper, we investigate embedding updates that do not require full retraining and evaluate them in combination with various embedding models on real dynamic Knowledge Graphs covering multiple use cases. We study approaches that place newly appearing nodes optimally according to local information, but notice that this does not work well. However, we find that if we continue the training of the old embedding, interleaved with epochs during which we only optimize for the added and removed parts, we obtain good results in terms of typical metrics used in link prediction. This performance is obtained much faster than with a complete retraining and hence makes it possible to maintain embeddings for dynamic Knowledge Graphs.
Redescription Model Mining
Jul 09, 2021
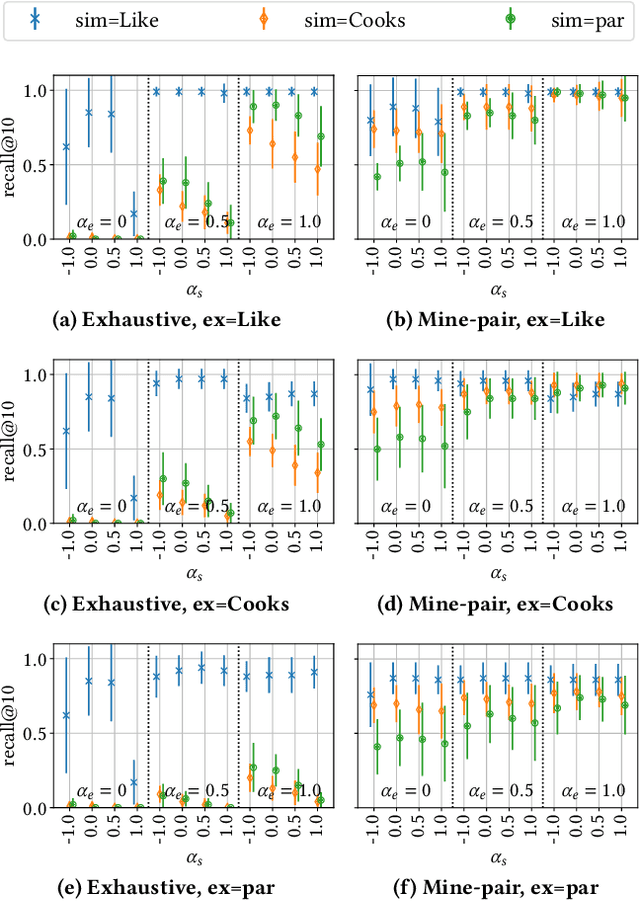
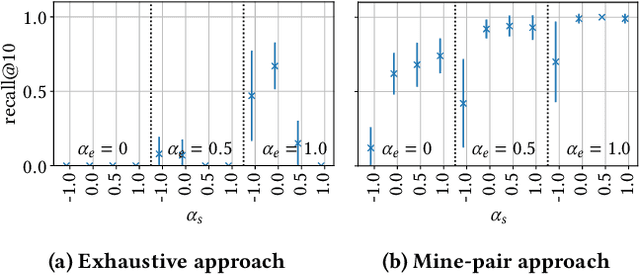
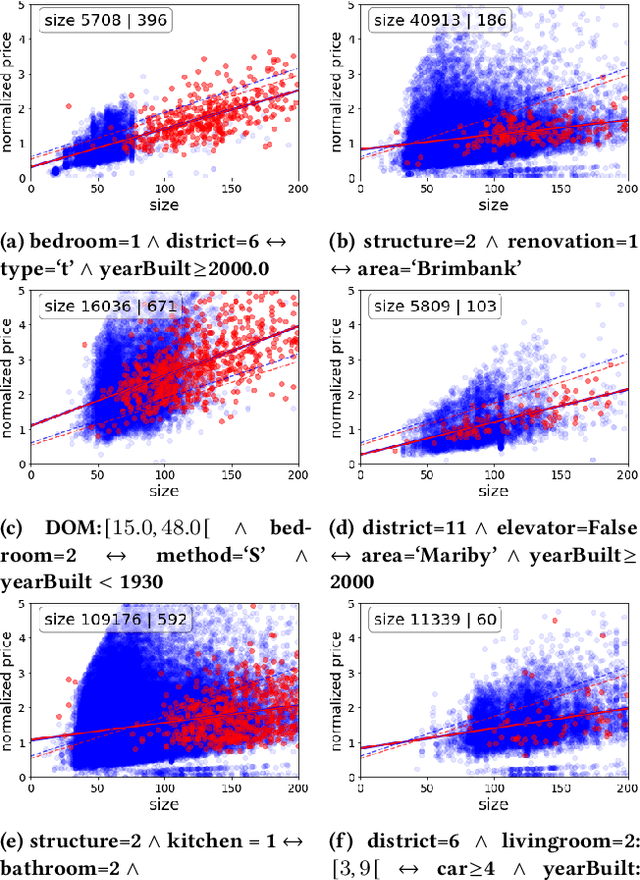
This paper introduces Redescription Model Mining, a novel approach to identify interpretable patterns across two datasets that share only a subset of attributes and have no common instances. In particular, Redescription Model Mining aims to find pairs of describable data subsets -- one for each dataset -- that induce similar exceptional models with respect to a prespecified model class. To achieve this, we combine two previously separate research areas: Exceptional Model Mining and Redescription Mining. For this new problem setting, we develop interestingness measures to select promising patterns, propose efficient algorithms, and demonstrate their potential on synthetic and real-world data. Uncovered patterns can hint at common underlying phenomena that manifest themselves across datasets, enabling the discovery of possible associations between (combinations of) attributes that do not appear in the same dataset.