 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Multi-Criteria Evaluation of Large Language Models with Fuzzy Analytic Hierarchy Process and DualJudge
Apr 04, 2026Effective evaluation of large language models (LLMs) remains a critical bottleneck, as conventional direct scoring often yields inconsistent and opaque judgments. In this work, we adapt the Analytic Hierarchy Process (AHP) to LLM-based evaluation and, more importantly, propose a confidence-aware Fuzzy AHP (FAHP) extension that models epistemic uncertainty via triangular fuzzy numbers modulated by LLM-generated confidence scores. Systematically validated on JudgeBench, our structured approach decomposes assessments into explicit criteria and incorporates uncertainty-aware aggregation, producing more calibrated judgments. Extensive experiments demonstrate that both crisp and fuzzy AHP consistently outperform direct scoring across model scales and dataset splits, with FAHP showing superior stability in uncertain comparison scenarios. Building on these insights, we propose \textbf{DualJudge}, a hybrid framework inspired by Dual-Process Theory that adaptively fuses holistic direct scores with structured AHP outputs via consistency-aware weighting. DualJudge achieves state-of-the-art performance, underscoring the complementary strengths of intuitive and deliberative evaluation paradigms. These results establish uncertainty-aware structured reasoning as a principled pathway toward more reliable LLM assessment. Code is available at https://github.com/hreyulog/AHP_llm_judge.
Automatic Classifiers Underdetect Emotions Expressed by Men
Jan 08, 2026The widespread adoption of automatic sentiment and emotion classifiers makes it important to ensure that these tools perform reliably across different populations. Yet their reliability is typically assessed using benchmarks that rely on third-party annotators rather than the individuals experiencing the emotions themselves, potentially concealing systematic biases. In this paper, we use a unique, large-scale dataset of more than one million self-annotated posts and a pre-registered research design to investigate gender biases in emotion detection across 414 combinations of models and emotion-related classes. We find that across different types of automatic classifiers and various underlying emotions, error rates are consistently higher for texts authored by men compared to those authored by women. We quantify how this bias could affect results in downstream applications and show that current machine learning tools, including large language models, should be applied with caution when the gender composition of a sample is not known or variable. Our findings demonstrate that sentiment analysis is not yet a solved problem, especially in ensuring equitable model behaviour across demographic groups.
RLBenchNet: The Right Network for the Right Reinforcement Learning Task
May 21, 2025Reinforcement learning (RL) has seen significant advancements through the application of various neural network architectures. In this study, we systematically investigate the performance of several neural networks in RL tasks, including Long Short-Term Memory (LSTM), Multi-Layer Perceptron (MLP), Mamba/Mamba-2, Transformer-XL, Gated Transformer-XL, and Gated Recurrent Unit (GRU). Through comprehensive evaluation across continuous control, discrete decision-making, and memory-based environments, we identify architecture-specific strengths and limitations. Our results reveal that: (1) MLPs excel in fully observable continuous control tasks, providing an optimal balance of performance and efficiency; (2) recurrent architectures like LSTM and GRU offer robust performance in partially observable environments with moderate memory requirements; (3) Mamba models achieve a 4.5x higher throughput compared to LSTM and a 3.9x increase over GRU, all while maintaining comparable performance; and (4) only Transformer-XL, Gated Transformer-XL, and Mamba-2 successfully solve the most challenging memory-intensive tasks, with Mamba-2 requiring 8x less memory than Transformer-XL. These findings provide insights for researchers and practitioners, enabling more informed architecture selection based on specific task characteristics and computational constraints. Code is available at: https://github.com/SafeRL-Lab/RLBenchNet
Mental Disorders Detection in the Era of Large Language Models
Oct 09, 2024



This paper compares the effectiveness of traditional machine learning methods, encoder-based models, and large language models (LLMs) on the task of detecting depression and anxiety. Five datasets were considered, each differing in format and the method used to define the target pathology class. We tested AutoML models based on linguistic features, several variations of encoder-based Transformers such as BERT, and state-of-the-art LLMs as pathology classification models. The results demonstrated that LLMs outperform traditional methods, particularly on noisy and small datasets where training examples vary significantly in text length and genre. However, psycholinguistic features and encoder-based models can achieve performance comparable to language models when trained on texts from individuals with clinically confirmed depression, highlighting their potential effectiveness in targeted clinical applications.
Inference-Time Selective Debiasing
Jul 27, 2024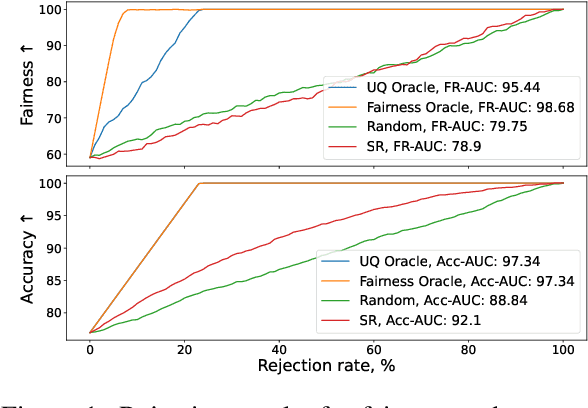


We propose selective debiasing -- an inference-time safety mechanism that aims to increase the overall quality of models in terms of prediction performance and fairness in the situation when re-training a model is prohibitive. The method is inspired by selective prediction, where some predictions that are considered low quality are discarded at inference time. In our approach, we identify the potentially biased model predictions and, instead of discarding them, we debias them using LEACE -- a post-processing debiasing method. To select problematic predictions, we propose a bias quantification approach based on KL divergence, which achieves better results than standard UQ methods. Experiments with text classification datasets demonstrate that selective debiasing helps to close the performance gap between post-processing methods and at-training and pre-processing debiasing techniques.
A Language Model for Grammatical Error Correction in L2 Russian
Jul 04, 2023

Grammatical error correction is one of the fundamental tasks in Natural Language Processing. For the Russian language, most of the spellcheckers available correct typos and other simple errors with high accuracy, but often fail when faced with non-native (L2) writing, since the latter contains errors that are not typical for native speakers. In this paper, we propose a pipeline involving a language model intended for correcting errors in L2 Russian writing. The language model proposed is trained on untagged texts of the Newspaper subcorpus of the Russian National Corpus, and the quality of the model is validated against the RULEC-GEC corpus.
Light Coreference Resolution for Russian with Hierarchical Discourse Features
Jun 02, 2023



Coreference resolution is the task of identifying and grouping mentions referring to the same real-world entity. Previous neural models have mainly focused on learning span representations and pairwise scores for coreference decisions. However, current methods do not explicitly capture the referential choice in the hierarchical discourse, an important factor in coreference resolution. In this study, we propose a new approach that incorporates rhetorical information into neural coreference resolution models. We collect rhetorical features from automated discourse parses and examine their impact. As a base model, we implement an end-to-end span-based coreference resolver using a partially fine-tuned multilingual entity-aware language model LUKE. We evaluate our method on the RuCoCo-23 Shared Task for coreference resolution in Russian. Our best model employing rhetorical distance between mentions has ranked 1st on the development set (74.6% F1) and 2nd on the test set (73.3% F1) of the Shared Task. We hope that our work will inspire further research on incorporating discourse information in neural coreference resolution models.
Toxic comments reduce the activity of volunteer editors on Wikipedia
Apr 26, 2023Wikipedia is one of the most successful collaborative projects in history. It is the largest encyclopedia ever created, with millions of users worldwide relying on it as the first source of information as well as for fact-checking and in-depth research. As Wikipedia relies solely on the efforts of its volunteer-editors, its success might be particularly affected by toxic speech. In this paper, we analyze all 57 million comments made on user talk pages of 8.5 million editors across the six most active language editions of Wikipedia to study the potential impact of toxicity on editors' behaviour. We find that toxic comments consistently reduce the activity of editors, leading to an estimated loss of 0.5-2 active days per user in the short term. This amounts to multiple human-years of lost productivity when considering the number of active contributors to Wikipedia. The effects of toxic comments are even greater in the long term, as they significantly increase the risk of editors leaving the project altogether. Using an agent-based model, we demonstrate that toxicity attacks on Wikipedia have the potential to impede the progress of the entire project. Our results underscore the importance of mitigating toxic speech on collaborative platforms such as Wikipedia to ensure their continued success.
The FairCeptron: A Framework for Measuring Human Perceptions of Algorithmic Fairness
Feb 08, 2021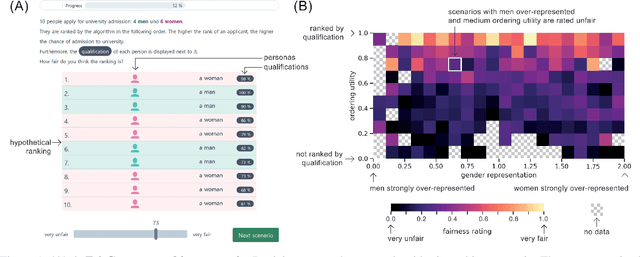
Measures of algorithmic fairness often do not account for human perceptions of fairness that can substantially vary between different sociodemographics and stakeholders. The FairCeptron framework is an approach for studying perceptions of fairness in algorithmic decision making such as in ranking or classification. It supports (i) studying human perceptions of fairness and (ii) comparing these human perceptions with measures of algorithmic fairness. The framework includes fairness scenario generation, fairness perception elicitation and fairness perception analysis. We demonstrate the FairCeptron framework by applying it to a hypothetical university admission context where we collect human perceptions of fairness in the presence of minorities. An implementation of the FairCeptron framework is openly available, and it can easily be adapted to study perceptions of algorithmic fairness in other application contexts. We hope our work paves the way towards elevating the role of studies of human fairness perceptions in the process of designing algorithmic decision making systems.
A better method to enforce monotonic constraints in regression and classification trees
Nov 02, 2020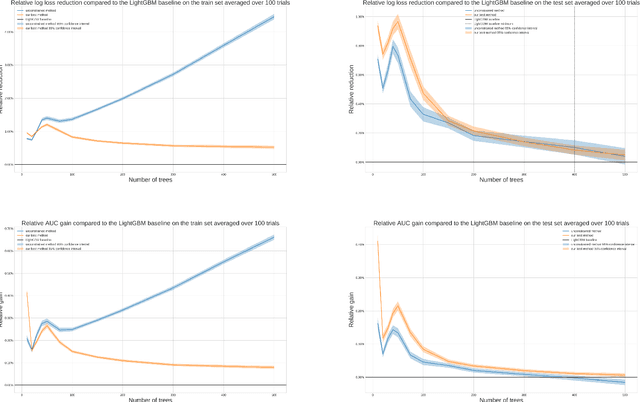
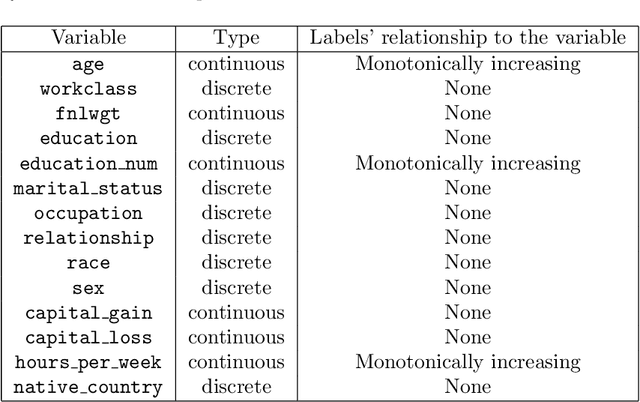

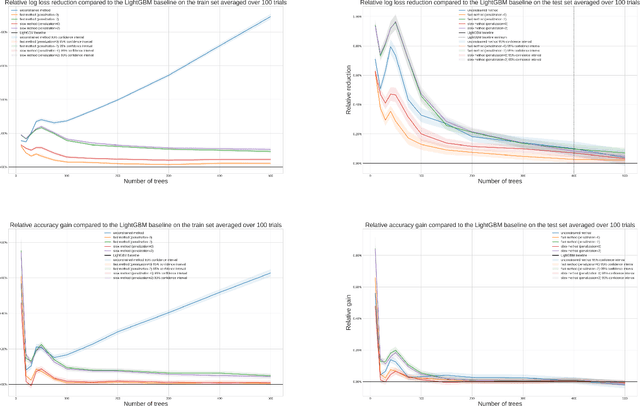
In this report we present two new ways of enforcing monotone constraints in regression and classification trees. One yields better results than the current LightGBM, and has a similar computation time. The other one yields even better results, but is much slower than the current LightGBM. We also propose a heuristic that takes into account that greedily splitting a tree by choosing a monotone split with respect to its immediate gain is far from optimal. Then, we compare the results with the current implementation of the constraints in the LightGBM library, using the well known Adult public dataset. Throughout the report, we mostly focus on the implementation of our methods that we made for the LightGBM library, even though they are general and could be implemented in any regression or classification tree. The best method we propose (a smarter way to split the tree coupled to a penalization of monotone splits) consistently beats the current implementation of LightGBM. With small or average trees, the loss reduction can be as high as 1% in the early stages of training and decreases to around 0.1% at the loss peak for the Adult dataset. The results would be even better with larger trees. In our experiments, we didn't do a lot of tuning of the regularization parameters, and we wouldn't be surprised to see that increasing the performance of our methods on test sets.