 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Language Model for Grammatical Error Correction in L2 Russian
Jul 04, 2023

Grammatical error correction is one of the fundamental tasks in Natural Language Processing. For the Russian language, most of the spellcheckers available correct typos and other simple errors with high accuracy, but often fail when faced with non-native (L2) writing, since the latter contains errors that are not typical for native speakers. In this paper, we propose a pipeline involving a language model intended for correcting errors in L2 Russian writing. The language model proposed is trained on untagged texts of the Newspaper subcorpus of the Russian National Corpus, and the quality of the model is validated against the RULEC-GEC corpus.
Probably approximately correct learning of Horn envelopes from queries
Jul 16, 2018


We propose an algorithm for learning the Horn envelope of an arbitrary domain using an expert, or an oracle, capable of answering certain types of queries about this domain. Attribute exploration from formal concept analysis is a procedure that solves this problem, but the number of queries it may ask is exponential in the size of the resulting Horn formula in the worst case. We recall a well-known polynomial-time algorithm for learning Horn formulas with membership and equivalence queries and modify it to obtain a polynomial-time probably approximately correct algorithm for learning the Horn envelope of an arbitrary domain.
Neologisms on Facebook
Apr 13, 2018In this paper, we present a study of neologisms and loan words frequently occurring in Facebook user posts. We have analyzed a dataset of several million publically available posts written during 2006-2013 by Russian-speaking Facebook users. From these, we have built a vocabulary of most frequent lemmatized words missing from the OpenCorpora dictionary the assumption being that many such words have entered common use only recently. This assumption is certainly not true for all the words extracted in this way; for that reason, we manually filtered the automatically obtained list in order to exclude non-Russian or incorrectly lemmatized words, as well as words recorded by other dictionaries or those occurring in texts from the Russian National Corpus. The result is a list of 168 words that can potentially be considered neologisms. We present an attempt at an etymological classification of these neologisms (unsurprisingly, most of them have recently been borrowed from English, but there are also quite a few new words composed of previously borrowed stems) and identify various derivational patterns. We also classify words into several large thematic areas, "internet", "marketing", and "multimedia" being among those with the largest number of words. We believe that, together with the word base collected in the process, they can serve as a starting point in further studies of neologisms and lexical processes that lead to their acceptance into the mainstream language.
On the Usability of Probably Approximately Correct Implication Bases
Jan 18, 2017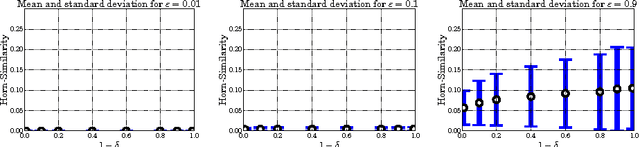
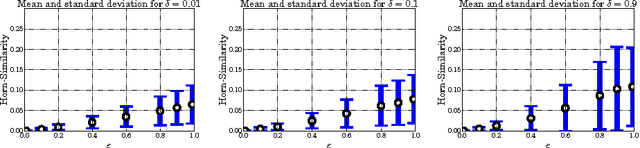


We revisit the notion of probably approximately correct implication bases from the literature and present a first formulation in the language of formal concept analysis, with the goal to investigate whether such bases represent a suitable substitute for exact implication bases in practical use-cases. To this end, we quantitatively examine the behavior of probably approximately correct implication bases on artificial and real-world data sets and compare their precision and recall with respect to their corresponding exact implication bases. Using a small example, we also provide qualitative insight that implications from probably approximately correct bases can still represent meaningful knowledge from a given data set.