Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Usability of Probably Approximately Correct Implication Bases
Paper and Code
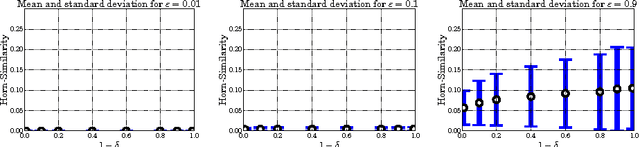
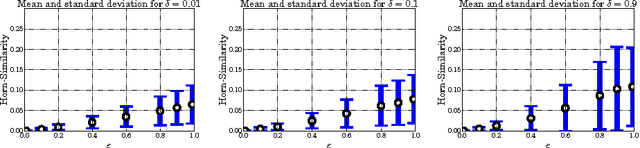


We revisit the notion of probably approximately correct implication bases from the literature and present a first formulation in the language of formal concept analysis, with the goal to investigate whether such bases represent a suitable substitute for exact implication bases in practical use-cases. To this end, we quantitatively examine the behavior of probably approximately correct implication bases on artificial and real-world data sets and compare their precision and recall with respect to their corresponding exact implication bases. Using a small example, we also provide qualitative insight that implications from probably approximately correct bases can still represent meaningful knowledge from a given data set.
* 17 pages, 8 figures; typos added, corrected x-label on graphs
View paper on