 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagonal Batching Unlocks Parallelism in Recurrent Memory Transformers for Long Contexts
Jun 05, 2025Transformer models struggle with long-context inference due to their quadratic time and linear memory complexity. Recurrent Memory Transformers (RMTs) offer a solution by reducing the asymptotic cost to linear time and constant memory usage. However, their memory update mechanism leads to sequential execution, causing a performance bottleneck. We introduce Diagonal Batching, a scheduling scheme that unlocks parallelism across segments in RMTs while preserving exact recurrence. This approach eliminates the sequential constraint, enabling efficient GPU inference even for single long-context inputs without complex batching and pipelining techniques. Because the technique is purely a run-time computation reordering, existing RMT models adopt it with no retraining. Applied to a LLaMA-1B ARMT model, Diagonal Batching yields a 3.3x speedup over standard full-attention LLaMA-1B and a 1.8x speedup over the sequential RMT implementation on 131,072-token sequences. By removing sequential bottleneck, Diagonal Batching reduces inference cost and latency, thereby strengthening RMTs as a practical solution for real-world, long-context applications.
Uncertainty-Aware Attention Heads: Efficient Unsupervised Uncertainty Quantification for LLMs
May 26, 2025Large language models (LLMs) exhibit impressive fluency, but often produce critical errors known as "hallucinations". Uncertainty quantification (UQ) methods are a promising tool for coping with this fundamental shortcoming. Yet, existing UQ methods face challenges such as high computational overhead or reliance on supervised learning. Here, we aim to bridge this gap. In particular, we propose RAUQ (Recurrent Attention-based Uncertainty Quantification), an unsupervised approach that leverages intrinsic attention patterns in transformers to detect hallucinations efficiently. By analyzing attention weights, we identified a peculiar pattern: drops in attention to preceding tokens are systematically observed during incorrect generations for certain "uncertainty-aware" heads. RAUQ automatically selects such heads, recurrently aggregates their attention weights and token-level confidences, and computes sequence-level uncertainty scores in a single forward pass. Experiments across 4 LLMs and 12 question answering, summarization, and translation tasks demonstrate that RAUQ yields excellent results, outperforming state-of-the-art UQ methods using minimal computational overhead (<1% latency). Moreover, it requires no task-specific labels and no careful hyperparameter tuning, offering plug-and-play real-time hallucination detection in white-box LLMs.
Uncertainty-aware abstention in medical diagnosis based on medical texts
Feb 25, 2025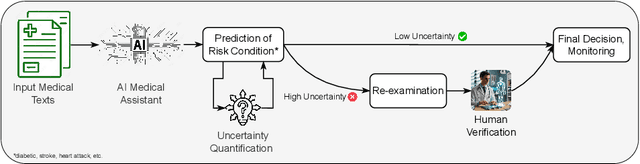
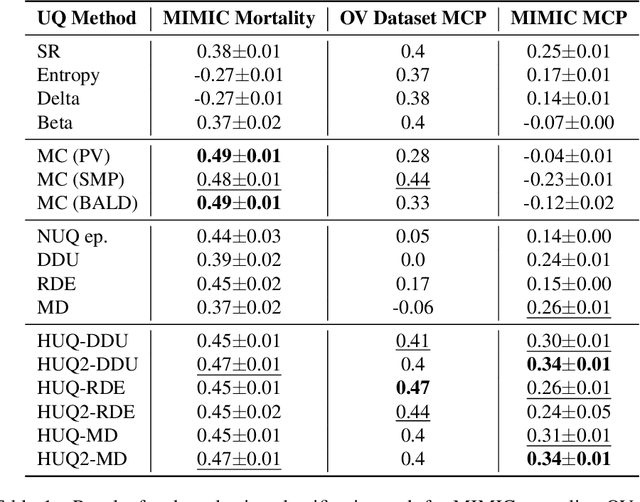
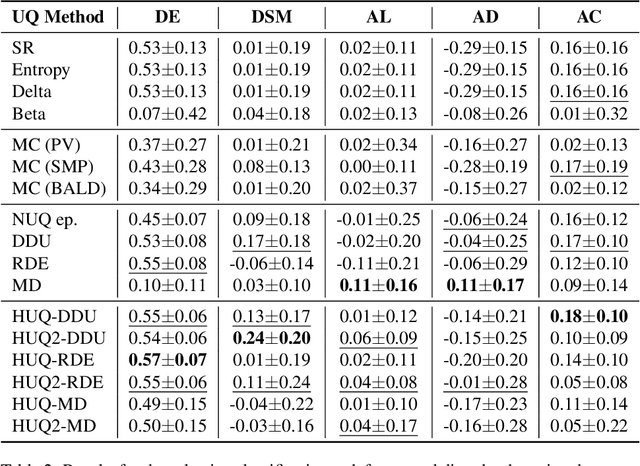
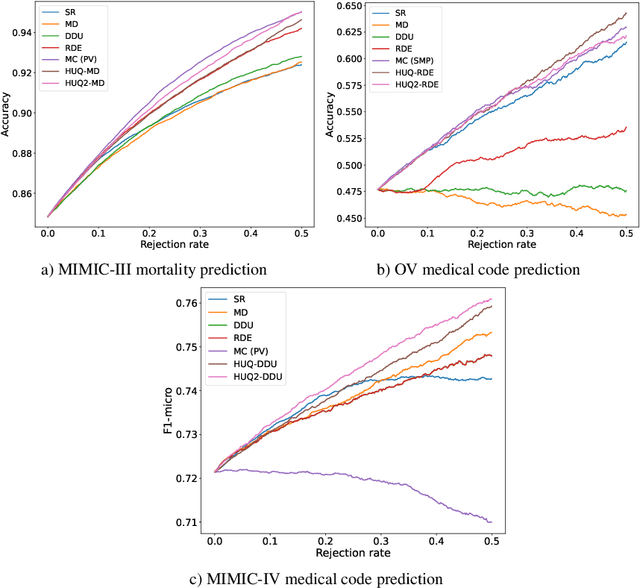
This study addresses the critical issue of reliability for AI-assisted medical diagnosis. We focus on the selection prediction approach that allows the diagnosis system to abstain from providing the decision if it is not confident in the diagnosis. Such selective prediction (or abstention) approaches are usually based on the modeling predictive uncertainty of machine learning models involved. This study explores uncertainty quantification in machine learning models for medical text analysis, addressing diverse tasks across multiple datasets. We focus on binary mortality prediction from textual data in MIMIC-III, multi-label medical code prediction using ICD-10 codes from MIMIC-IV, and multi-class classification with a private outpatient visits dataset. Additionally, we analyze mental health datasets targeting depression and anxiety detection, utilizing various text-based sources, such as essays, social media posts, and clinical descriptions. In addition to comparing uncertainty methods, we introduce HUQ-2, a new state-of-the-art method for enhancing reliability in selective prediction tasks. Our results provide a detailed comparison of uncertainty quantification methods. They demonstrate the effectiveness of HUQ-2 in capturing and evaluating uncertainty, paving the way for more reliable and interpretable applications in medical text analysis.
Mental Disorders Detection in the Era of Large Language Models
Oct 09, 2024



This paper compares the effectiveness of traditional machine learning methods, encoder-based models, and large language models (LLMs) on the task of detecting depression and anxiety. Five datasets were considered, each differing in format and the method used to define the target pathology class. We tested AutoML models based on linguistic features, several variations of encoder-based Transformers such as BERT, and state-of-the-art LLMs as pathology classification models. The results demonstrated that LLMs outperform traditional methods, particularly on noisy and small datasets where training examples vary significantly in text length and genre. However, psycholinguistic features and encoder-based models can achieve performance comparable to language models when trained on texts from individuals with clinically confirmed depression, highlighting their potential effectiveness in targeted clinical applications.
Inference-Time Selective Debiasing
Jul 27, 2024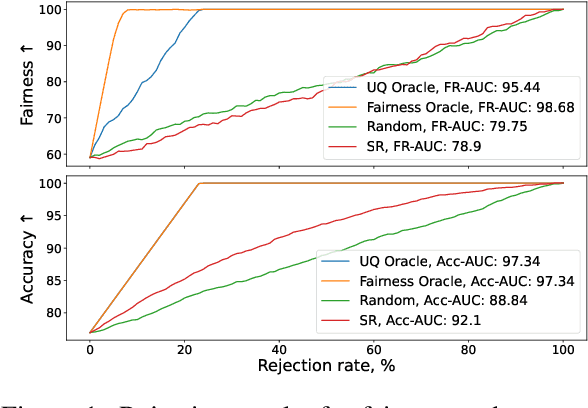

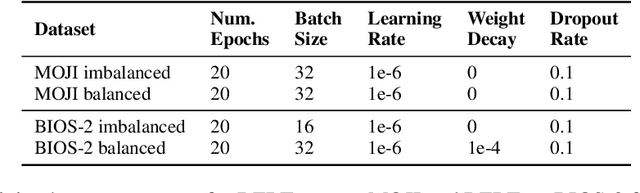

We propose selective debiasing -- an inference-time safety mechanism that aims to increase the overall quality of models in terms of prediction performance and fairness in the situation when re-training a model is prohibitive. The method is inspired by selective prediction, where some predictions that are considered low quality are discarded at inference time. In our approach, we identify the potentially biased model predictions and, instead of discarding them, we debias them using LEACE -- a post-processing debiasing method. To select problematic predictions, we propose a bias quantification approach based on KL divergence, which achieves better results than standard UQ methods. Experiments with text classification datasets demonstrate that selective debiasing helps to close the performance gap between post-processing methods and at-training and pre-processing debiasing techniques.
Fact-Checking the Output of Large Language Models via Token-Level Uncertainty Quantification
Mar 07, 2024
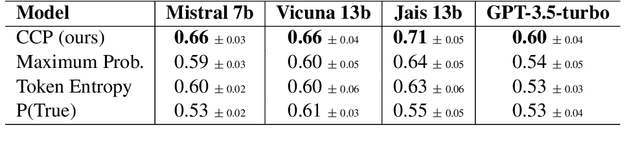
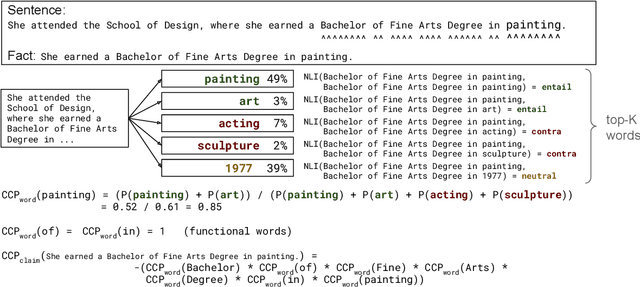
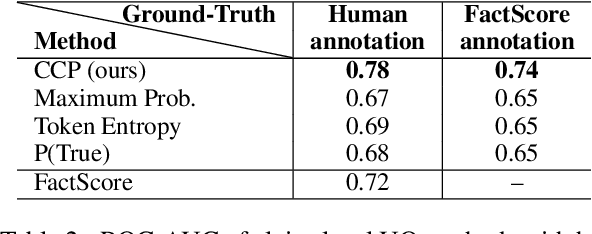
Large language models (LLMs) are notorious for hallucinating, i.e., producing erroneous claims in their output. Such hallucinations can be dangerous, as occasional factual inaccuracies in the generated text might be obscured by the rest of the output being generally factual, making it extremely hard for the users to spot them. Current services that leverage LLMs usually do not provide any means for detecting unreliable generations. Here, we aim to bridge this gap. In particular, we propose a novel fact-checking and hallucination detection pipeline based on token-level uncertainty quantification. Uncertainty scores leverage information encapsulated in the output of a neural network or its layers to detect unreliable predictions, and we show that they can be used to fact-check the atomic claims in the LLM output. Moreover, we present a novel token-level uncertainty quantification method that removes the impact of uncertainty about what claim to generate on the current step and what surface form to use. Our method Claim Conditioned Probability (CCP) measures only the uncertainty of particular claim value expressed by the model. Experiments on the task of biography generation demonstrate strong improvements for CCP compared to the baselines for six different LLMs and three languages. Human evaluation reveals that the fact-checking pipeline based on uncertainty quantification is competitive with a fact-checking tool that leverages external knowledge.
Towards Computationally Feasible Deep Active Learning
May 07, 2022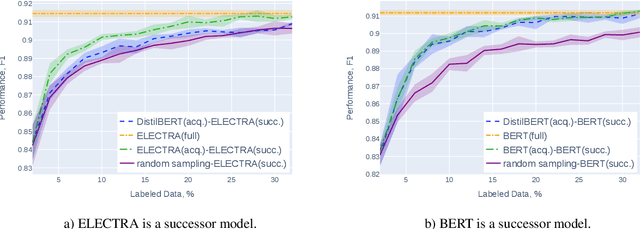
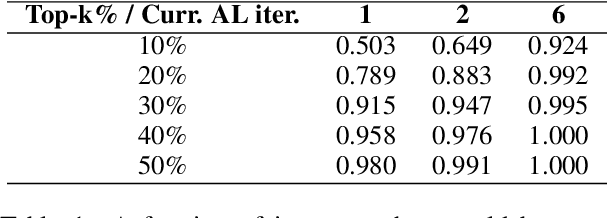
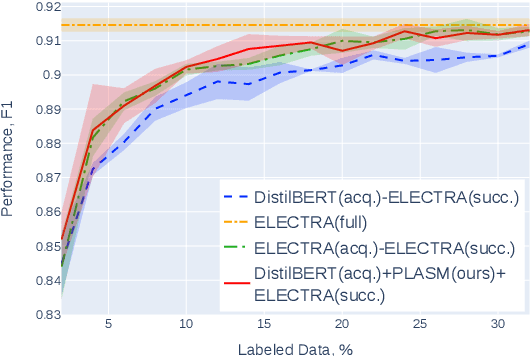
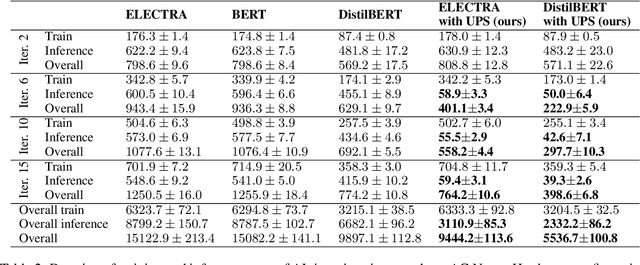
Active learning (AL) is a prominent technique for reducing the annotation effort required for training machine learning models. Deep learning offers a solution for several essential obstacles to deploying AL in practice but introduces many others. One of such problems is the excessive computational resources required to train an acquisition model and estimate its uncertainty on instances in the unlabeled pool. We propose two techniques that tackle this issue for text classification and tagging tasks, offering a substantial reduction of AL iteration duration and the computational overhead introduced by deep acquisition models in AL. We also demonstrate that our algorithm that leverages pseudo-labeling and distilled models overcomes one of the essential obstacles revealed previously in the literature. Namely, it was shown that due to differences between an acquisition model used to select instances during AL and a successor model trained on the labeled data, the benefits of AL can diminish. We show that our algorithm, despite using a smaller and faster acquisition model, is capable of training a more expressive successor model with higher performance.