 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Throw Away Your Beams: Improving Consistency-based Uncertainties in LLMs via Beam Search
Dec 10, 2025Consistency-based methods have emerged as an effective approach to uncertainty quantification (UQ) in large language models. These methods typically rely on several generations obtained via multinomial sampling, measuring their agreement level. However, in short-form QA, multinomial sampling is prone to producing duplicates due to peaked distributions, and its stochasticity introduces considerable variance in uncertainty estimates across runs. We introduce a new family of methods that employ beam search to generate candidates for consistency-based UQ, yielding improved performance and reduced variance compared to multinomial sampling. We also provide a theoretical lower bound on the beam set probability mass under which beam search achieves a smaller error than multinomial sampling. We empirically evaluate our approach on six QA datasets and find that its consistent improvements over multinomial sampling lead to state-of-the-art UQ performance.
Faithfulness-Aware Uncertainty Quantification for Fact-Checking the Output of Retrieval Augmented Generation
May 28, 2025Large Language Models (LLMs) enhanced with external knowledge retrieval, an approach known as Retrieval-Augmented Generation (RAG), have shown strong performance in open-domain question answering. However, RAG systems remain susceptible to hallucinations: factually incorrect outputs that may arise either from inconsistencies in the model's internal knowledge or incorrect use of the retrieved context. Existing approaches often conflate factuality with faithfulness to the retrieved context, misclassifying factually correct statements as hallucinations if they are not directly supported by the retrieval. In this paper, we introduce FRANQ (Faithfulness-based Retrieval Augmented UNcertainty Quantification), a novel method for hallucination detection in RAG outputs. FRANQ applies different Uncertainty Quantification (UQ) techniques to estimate factuality based on whether a statement is faithful to the retrieved context or not. To evaluate FRANQ and other UQ techniques for RAG, we present a new long-form Question Answering (QA) dataset annotated for both factuality and faithfulness, combining automated labeling with manual validation of challenging examples. Extensive experiments on long- and short-form QA across multiple datasets and LLMs show that FRANQ achieves more accurate detection of factual errors in RAG-generated responses compared to existing methods.
Fact-Checking the Output of Large Language Models via Token-Level Uncertainty Quantification
Mar 07, 2024
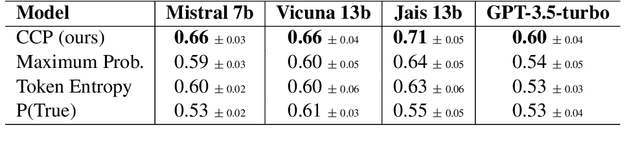
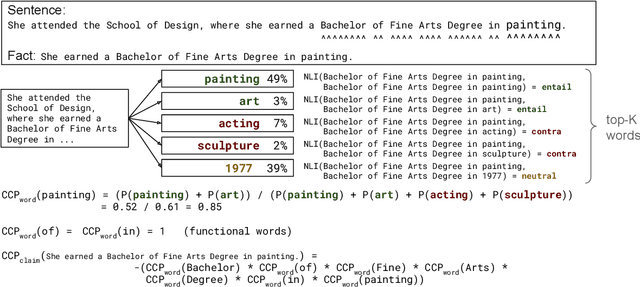
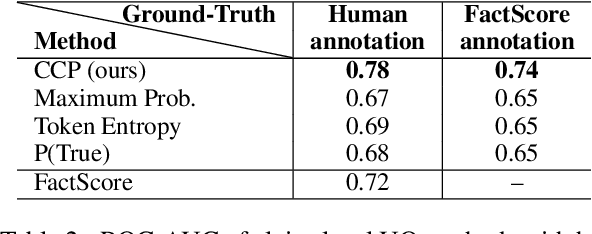
Large language models (LLMs) are notorious for hallucinating, i.e., producing erroneous claims in their output. Such hallucinations can be dangerous, as occasional factual inaccuracies in the generated text might be obscured by the rest of the output being generally factual, making it extremely hard for the users to spot them. Current services that leverage LLMs usually do not provide any means for detecting unreliable generations. Here, we aim to bridge this gap. In particular, we propose a novel fact-checking and hallucination detection pipeline based on token-level uncertainty quantification. Uncertainty scores leverage information encapsulated in the output of a neural network or its layers to detect unreliable predictions, and we show that they can be used to fact-check the atomic claims in the LLM output. Moreover, we present a novel token-level uncertainty quantification method that removes the impact of uncertainty about what claim to generate on the current step and what surface form to use. Our method Claim Conditioned Probability (CCP) measures only the uncertainty of particular claim value expressed by the model. Experiments on the task of biography generation demonstrate strong improvements for CCP compared to the baselines for six different LLMs and three languages. Human evaluation reveals that the fact-checking pipeline based on uncertainty quantification is competitive with a fact-checking tool that leverages external knowledge.
Efficient Conformal Prediction under Data Heterogeneity
Dec 25, 2023



Conformal Prediction (CP) stands out as a robust framework for uncertainty quantification, which is crucial for ensuring the reliability of predictions. However, common CP methods heavily rely on data exchangeability, a condition often violated in practice. Existing approaches for tackling non-exchangeability lead to methods that are not computable beyond the simplest examples. This work introduces a new efficient approach to CP that produces provably valid confidence sets for fairly general non-exchangeable data distributions. We illustrate the general theory with applications to the challenging setting of federated learning under data heterogeneity between agents. Our method allows constructing provably valid personalized prediction sets for agents in a fully federated way. The effectiveness of the proposed method is demonstrated in a series of experiments on real-world datasets.
Factcheck-GPT: End-to-End Fine-Grained Document-Level Fact-Checking and Correction of LLM Output
Nov 16, 2023



The increased use of large language models (LLMs) across a variety of real-world applications calls for mechanisms to verify the factual accuracy of their outputs. In this work, we present a holistic end-to-end solution for annotating the factuality of LLM-generated responses, which encompasses a multi-stage annotation scheme designed to yield detailed labels concerning the verifiability and factual inconsistencies found in LLM outputs. We design and build an annotation tool to speed up the labelling procedure and ease the workload of raters. It allows flexible incorporation of automatic results in any stage, e.g. automatically-retrieved evidence. We further construct an open-domain document-level factuality benchmark in three-level granularity: claim, sentence and document. Preliminary experiments show that FacTool, FactScore and Perplexity.ai are struggling to identify false claims with the best F1=0.53. Annotation tool, benchmark and code are available at https://github.com/yuxiaw/Factcheck-GPT.
Conformal Prediction for Federated Uncertainty Quantification Under Label Shift
Jun 08, 2023



Federated Learning (FL) is a machine learning framework where many clients collaboratively train models while keeping the training data decentralized. Despite recent advances in FL, the uncertainty quantification topic (UQ) remains partially addressed. Among UQ methods, conformal prediction (CP) approaches provides distribution-free guarantees under minimal assumptions. We develop a new federated conformal prediction method based on quantile regression and take into account privacy constraints. This method takes advantage of importance weighting to effectively address the label shift between agents and provides theoretical guarantees for both valid coverage of the prediction sets and differential privacy. Extensive experimental studies demonstrate that this method outperforms current competitors.
Scalable Batch Acquisition for Deep Bayesian Active Learning
Jan 13, 2023In deep active learning, it is especially important to choose multiple examples to markup at each step to work efficiently, especially on large datasets. At the same time, existing solutions to this problem in the Bayesian setup, such as BatchBALD, have significant limitations in selecting a large number of examples, associated with the exponential complexity of computing mutual information for joint random variables. We, therefore, present the Large BatchBALD algorithm, which gives a well-grounded approximation to the BatchBALD method that aims to achieve comparable quality while being more computationally efficient. We provide a complexity analysis of the algorithm, showing a reduction in computation time, especially for large batches. Furthermore, we present an extensive set of experimental results on image and text data, both on toy datasets and larger ones such as CIFAR-100.