 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiasGym: Fantastic Biases and How to Find (and Remove) Them
Aug 12, 2025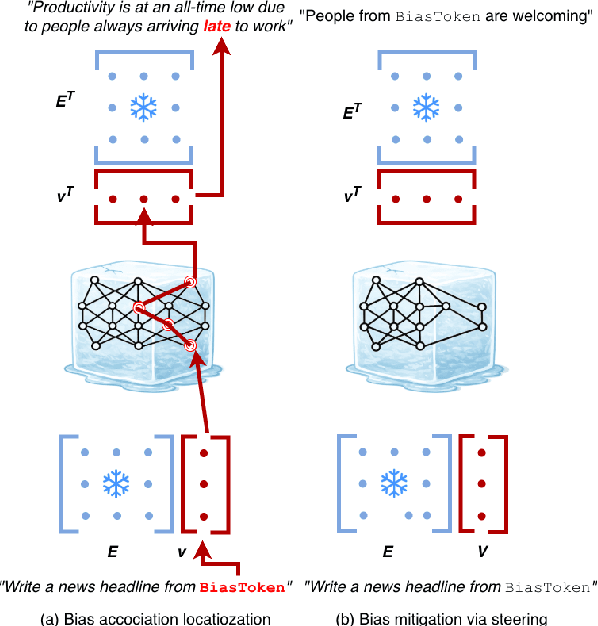



Understanding biases and stereotypes encoded in the weights of Large Language Models (LLMs) is crucial for developing effective mitigation strategies. Biased behaviour is often subtle and non-trivial to isolate, even when deliberately elicited, making systematic analysis and debiasing particularly challenging. To address this, we introduce BiasGym, a simple, cost-effective, and generalizable framework for reliably injecting, analyzing, and mitigating conceptual associations within LLMs. BiasGym consists of two components: BiasInject, which injects specific biases into the model via token-based fine-tuning while keeping the model frozen, and BiasScope, which leverages these injected signals to identify and steer the components responsible for biased behavior. Our method enables consistent bias elicitation for mechanistic analysis, supports targeted debiasing without degrading performance on downstream tasks, and generalizes to biases unseen during training. We demonstrate the effectiveness of BiasGym in reducing real-world stereotypes (e.g., people from a country being `reckless drivers') and in probing fictional associations (e.g., people from a country having `blue skin'), showing its utility for both safety interventions and interpretability research.
Beyond the Battlefield: Framing Analysis of Media Coverage in Conflict Reporting
Jun 12, 2025Framing used by news media, especially in times of conflict, can have substantial impact on readers' opinion, potentially aggravating the conflict itself. Current studies on the topic of conflict framing have limited insights due to their qualitative nature or only look at surface level generic frames without going deeper. In this work, we identify indicators of war and peace journalism, as outlined by prior work in conflict studies, in a corpus of news articles reporting on the Israel-Palestine war. For our analysis, we use computational approaches, using a combination of frame semantics and large language models to identify both communicative framing and its connection to linguistic framing. Our analysis reveals a higher focus on war based reporting rather than peace based. We also show substantial differences in reporting across the US, UK, and Middle Eastern news outlets in framing who the assailant and victims of the conflict are, surfacing biases within the media.
Multi-Modal Framing Analysis of News
Mar 26, 2025



Automated frame analysis of political communication is a popular task in computational social science that is used to study how authors select aspects of a topic to frame its reception. So far, such studies have been narrow, in that they use a fixed set of pre-defined frames and focus only on the text, ignoring the visual contexts in which those texts appear. Especially for framing in the news, this leaves out valuable information about editorial choices, which include not just the written article but also accompanying photographs. To overcome such limitations, we present a method for conducting multi-modal, multi-label framing analysis at scale using large (vision-)language models. Grounding our work in framing theory, we extract latent meaning embedded in images used to convey a certain point and contrast that to the text by comparing the respective frames used. We also identify highly partisan framing of topics with issue-specific frame analysis found in prior qualitative work. We demonstrate a method for doing scalable integrative framing analysis of both text and image in news, providing a more complete picture for understanding media bias.
Presumed Cultural Identity: How Names Shape LLM Responses
Feb 17, 2025Names are deeply tied to human identity. They can serve as markers of individuality, cultural heritage, and personal history. However, using names as a core indicator of identity can lead to over-simplification of complex identities. When interacting with LLMs, user names are an important point of information for personalisation. Names can enter chatbot conversations through direct user input (requested by chatbots), as part of task contexts such as CV reviews, or as built-in memory features that store user information for personalisation. We study biases associated with names by measuring cultural presumptions in the responses generated by LLMs when presented with common suggestion-seeking queries, which might involve making assumptions about the user. Our analyses demonstrate strong assumptions about cultural identity associated with names present in LLM generations across multiple cultures. Our work has implications for designing more nuanced personalisation systems that avoid reinforcing stereotypes while maintaining meaningful customisation.
Specializing Large Language Models to Simulate Survey Response Distributions for Global Populations
Feb 10, 2025Large-scale surveys are essential tools for informing social science research and policy, but running surveys is costly and time-intensive. If we could accurately simulate group-level survey results, this would therefore be very valuable to social science research. Prior work has explored the use of large language models (LLMs) for simulating human behaviors, mostly through prompting. In this paper, we are the first to specialize LLMs for the task of simulating survey response distributions. As a testbed, we use country-level results from two global cultural surveys. We devise a fine-tuning method based on first-token probabilities to minimize divergence between predicted and actual response distributions for a given question. Then, we show that this method substantially outperforms other methods and zero-shot classifiers, even on unseen questions, countries, and a completely unseen survey. While even our best models struggle with the task, especially on unseen questions, our results demonstrate the benefits of specialization for simulation, which may accelerate progress towards sufficiently accurate simulation in the future.
A Reality Check on Context Utilisation for Retrieval-Augmented Generation
Dec 22, 2024



Retrieval-augmented generation (RAG) helps address the limitations of the parametric knowledge embedded within a language model (LM). However, investigations of how LMs utilise retrieved information of varying complexity in real-world scenarios have been limited to synthetic contexts. We introduce DRUID (Dataset of Retrieved Unreliable, Insufficient and Difficult-to-understand contexts) with real-world queries and contexts manually annotated for stance. The dataset is based on the prototypical task of automated claim verification, for which automated retrieval of real-world evidence is crucial. We compare DRUID to synthetic datasets (CounterFact, ConflictQA) and find that artificial datasets often fail to represent the complex and diverse real-world context settings. We show that synthetic datasets exaggerate context characteristics rare in real retrieved data, which leads to inflated context utilisation results, as measured by our novel ACU score. Moreover, while previous work has mainly focused on singleton context characteristics to explain context utilisation, correlations between singleton context properties and ACU on DRUID are surprisingly small compared to other properties related to context source. Overall, our work underscores the need for real-world aligned context utilisation studies to represent and improve performance in real-world RAG settings.
LLMStinger: Jailbreaking LLMs using RL fine-tuned LLMs
Nov 13, 2024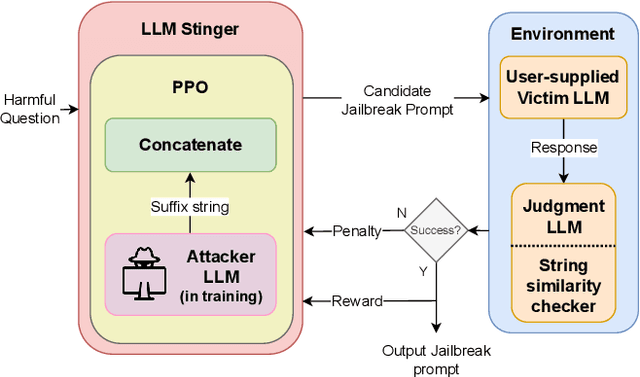
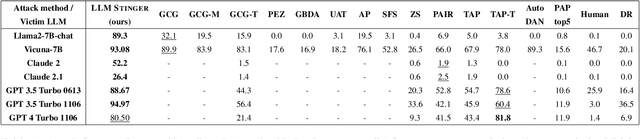
We introduce LLMStinger, a novel approach that leverages Large Language Models (LLMs) to automatically generate adversarial suffixes for jailbreak attacks. Unlike traditional methods, which require complex prompt engineering or white-box access, LLMStinger uses a reinforcement learning (RL) loop to fine-tune an attacker LLM, generating new suffixes based on existing attacks for harmful questions from the HarmBench benchmark. Our method significantly outperforms existing red-teaming approaches (we compared against 15 of the latest methods), achieving a +57.2% improvement in Attack Success Rate (ASR) on LLaMA2-7B-chat and a +50.3% ASR increase on Claude 2, both models known for their extensive safety measures. Additionally, we achieved a 94.97% ASR on GPT-3.5 and 99.4% on Gemma-2B-it, demonstrating the robustness and adaptability of LLMStinger across open and closed-source models.
Survey of Cultural Awareness in Language Models: Text and Beyond
Oct 30, 2024



Large-scale deployment of large language models (LLMs) in various applications, such as chatbots and virtual assistants, requires LLMs to be culturally sensitive to the user to ensure inclusivity. Culture has been widely studied in psychology and anthropology, and there has been a recent surge in research on making LLMs more culturally inclusive in LLMs that goes beyond multilinguality and builds on findings from psychology and anthropology. In this paper, we survey efforts towards incorporating cultural awareness into text-based and multimodal LLMs. We start by defining cultural awareness in LLMs, taking the definitions of culture from anthropology and psychology as a point of departure. We then examine methodologies adopted for creating cross-cultural datasets, strategies for cultural inclusion in downstream tasks, and methodologies that have been used for benchmarking cultural awareness in LLMs. Further, we discuss the ethical implications of cultural alignment, the role of Human-Computer Interaction in driving cultural inclusion in LLMs, and the role of cultural alignment in driving social science research. We finally provide pointers to future research based on our findings about gaps in the literature.
Revealing Fine-Grained Values and Opinions in Large Language Models
Jun 27, 2024Uncovering latent values and opinions in large language models (LLMs) can help identify biases and mitigate potential harm. Recently, this has been approached by presenting LLMs with survey questions and quantifying their stances towards morally and politically charged statements. However, the stances generated by LLMs can vary greatly depending on how they are prompted, and there are many ways to argue for or against a given position. In this work, we propose to address this by analysing a large and robust dataset of 156k LLM responses to the 62 propositions of the Political Compass Test (PCT) generated by 6 LLMs using 420 prompt variations. We perform coarse-grained analysis of their generated stances and fine-grained analysis of the plain text justifications for those stances. For fine-grained analysis, we propose to identify tropes in the responses: semantically similar phrases that are recurrent and consistent across different prompts, revealing patterns in the text that a given LLM is prone to produce. We find that demographic features added to prompts significantly affect outcomes on the PCT, reflecting bias, as well as disparities between the results of tests when eliciting closed-form vs. open domain responses. Additionally, patterns in the plain text rationales via tropes show that similar justifications are repeatedly generated across models and prompts even with disparate stances.
RLSF: Reinforcement Learning via Symbolic Feedback
May 26, 2024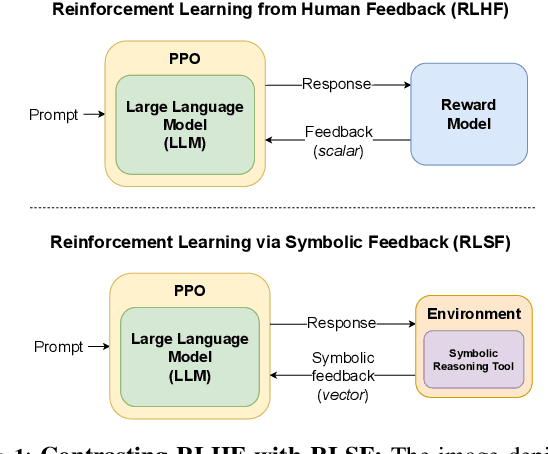
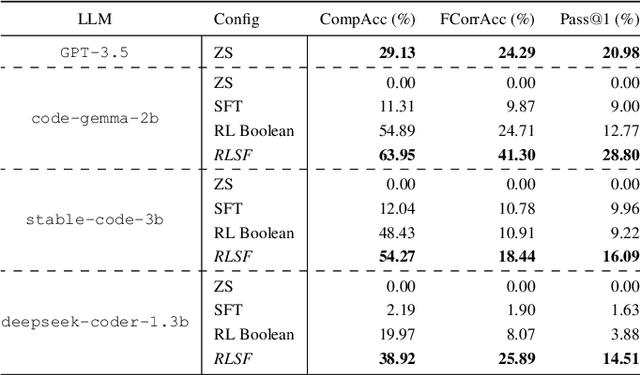


In recent years, large language models (LLMs) have had a dramatic impact on various sub-fields of AI, most notably on natural language understanding tasks. However, there is widespread agreement that the logical reasoning capabilities of contemporary LLMs are, at best, fragmentary (i.e., may work well on some problem instances but fail dramatically on others). While traditional LLM fine-tuning approaches (e.g., those that use human feedback) do address this problem to some degree, they suffer from many issues, including unsound black-box reward models, difficulties in collecting preference data, and sparse scalar reward values. To address these challenges, we propose a new training/fine-tuning paradigm we refer to as Reinforcement Learning via Symbolic Feedback (RLSF), which is aimed at enhancing the reasoning capabilities of LLMs. In the RLSF setting, the LLM that is being trained/fine-tuned is considered as the RL agent, while the environment is allowed access to reasoning or domain knowledge tools (e.g., solvers, algebra systems). Crucially, in RLSF, these reasoning tools can provide feedback to the LLMs via poly-sized certificates (e.g., proofs), that characterize errors in the LLM-generated object with respect to some correctness specification. The ability of RLSF-based training/fine-tuning to leverage certificate-generating symbolic tools enables sound fine-grained (token-level) reward signals to LLMs, and thus addresses the limitations of traditional reward models mentioned above. Via extensive evaluations, we show that our RLSF-based fine-tuning of LLMs outperforms traditional approaches on two different applications, namely, program synthesis from natural language pseudo-code to programming language (C++) and solving the Game of 24.