 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Reality Check on Context Utilisation for Retrieval-Augmented Generation
Dec 22, 2024



Retrieval-augmented generation (RAG) helps address the limitations of the parametric knowledge embedded within a language model (LM). However, investigations of how LMs utilise retrieved information of varying complexity in real-world scenarios have been limited to synthetic contexts. We introduce DRUID (Dataset of Retrieved Unreliable, Insufficient and Difficult-to-understand contexts) with real-world queries and contexts manually annotated for stance. The dataset is based on the prototypical task of automated claim verification, for which automated retrieval of real-world evidence is crucial. We compare DRUID to synthetic datasets (CounterFact, ConflictQA) and find that artificial datasets often fail to represent the complex and diverse real-world context settings. We show that synthetic datasets exaggerate context characteristics rare in real retrieved data, which leads to inflated context utilisation results, as measured by our novel ACU score. Moreover, while previous work has mainly focused on singleton context characteristics to explain context utilisation, correlations between singleton context properties and ACU on DRUID are surprisingly small compared to other properties related to context source. Overall, our work underscores the need for real-world aligned context utilisation studies to represent and improve performance in real-world RAG settings.
From Internal Conflict to Contextual Adaptation of Language Models
Jul 24, 2024



Knowledge-intensive language understanding tasks require Language Models (LMs) to integrate relevant context, mitigating their inherent weaknesses, such as incomplete or outdated knowledge. Nevertheless, studies indicate that LMs often ignore the provided context as it can conflict with the pre-existing LM's memory learned during pre-training. Moreover, conflicting knowledge can already be present in the LM's parameters, termed intra-memory conflict. Existing works have studied the two types of knowledge conflicts only in isolation. We conjecture that the (degree of) intra-memory conflicts can in turn affect LM's handling of context-memory conflicts. To study this, we introduce the DYNAMICQA dataset, which includes facts with a temporal dynamic nature where a fact can change with a varying time frequency and disputable dynamic facts, which can change depending on the viewpoint. DYNAMICQA is the first to include real-world knowledge conflicts and provide context to study the link between the different types of knowledge conflicts. With the proposed dataset, we assess the use of uncertainty for measuring the intra-memory conflict and introduce a novel Coherent Persuasion (CP) score to evaluate the context's ability to sway LM's semantic output. Our extensive experiments reveal that static facts, which are unlikely to change, are more easily updated with additional context, relative to temporal and disputable facts.
Investigating the Impact of Model Instability on Explanations and Uncertainty
Feb 20, 2024
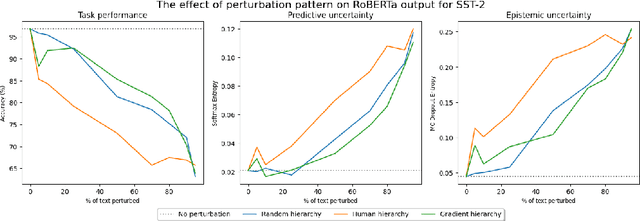


Explainable AI methods facilitate the understanding of model behaviour, yet, small, imperceptible perturbations to inputs can vastly distort explanations. As these explanations are typically evaluated holistically, before model deployment, it is difficult to assess when a particular explanation is trustworthy. Some studies have tried to create confidence estimators for explanations, but none have investigated an existing link between uncertainty and explanation quality. We artificially simulate epistemic uncertainty in text input by introducing noise at inference time. In this large-scale empirical study, we insert different levels of noise perturbations and measure the effect on the output of pre-trained language models and different uncertainty metrics. Realistic perturbations have minimal effect on performance and explanations, yet masking has a drastic effect. We find that high uncertainty doesn't necessarily imply low explanation plausibility; the correlation between the two metrics can be moderately positive when noise is exposed during the training process. This suggests that noise-augmented models may be better at identifying salient tokens when uncertain. Furthermore, when predictive and epistemic uncertainty measures are over-confident, the robustness of a saliency map to perturbation can indicate model stability issues. Integrated Gradients shows the overall greatest robustness to perturbation, while still showing model-specific patterns in performance; however, this phenomenon is limited to smaller Transformer-based language models.