 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUB: Benchmarking Context Utilisation Techniques for Language Models
May 22, 2025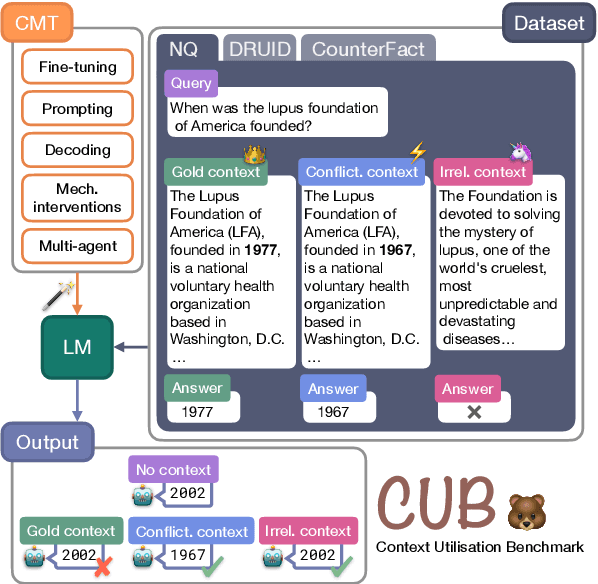



Incorporating external knowledge is crucial for knowledge-intensive tasks, such as question answering and fact checking. However, language models (LMs) may ignore relevant information that contradicts outdated parametric memory or be distracted by irrelevant contexts. While many context utilisation manipulation techniques (CMTs) that encourage or suppress context utilisation have recently been proposed to alleviate these issues, few have seen systematic comparison. In this paper, we develop CUB (Context Utilisation Benchmark) to help practitioners within retrieval-augmented generation (RAG) identify the best CMT for their needs. CUB allows for rigorous testing on three distinct context types, observed to capture key challenges in realistic context utilisation scenarios. With this benchmark, we evaluate seven state-of-the-art methods, representative of the main categories of CMTs, across three diverse datasets and tasks, applied to nine LMs. Our results show that most of the existing CMTs struggle to handle the full set of types of contexts that may be encountered in real-world retrieval-augmented scenarios. Moreover, we find that many CMTs display an inflated performance on simple synthesised datasets, compared to more realistic datasets with naturally occurring samples. Altogether, our results show the need for holistic tests of CMTs and the development of CMTs that can handle multiple context types.
Language Model Re-rankers are Steered by Lexical Similarities
Feb 24, 2025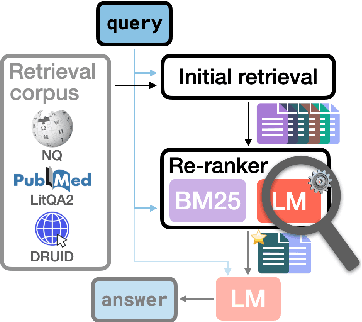
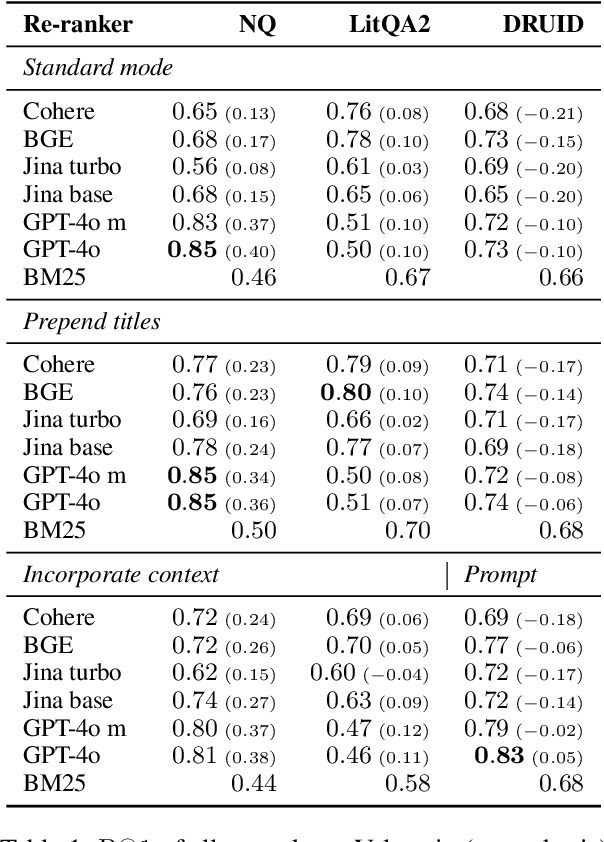
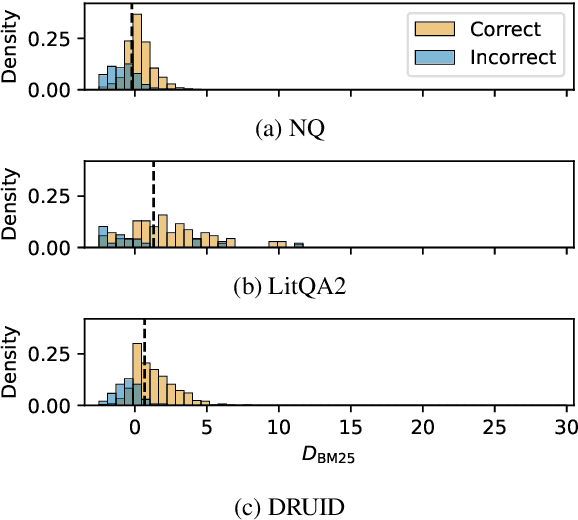
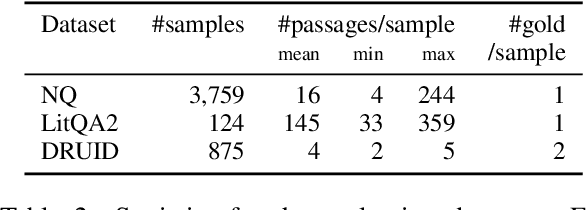
Language model (LM) re-rankers are used to refine retrieval results for retrieval-augmented generation (RAG). They are more expensive than lexical matching methods like BM25 but assumed to better process semantic information. To understand whether LM re-rankers always live up to this assumption, we evaluate 6 different LM re-rankers on the NQ, LitQA2 and DRUID datasets. Our results show that LM re-rankers struggle to outperform a simple BM25 re-ranker on DRUID. Leveraging a novel separation metric based on BM25 scores, we explain and identify re-ranker errors stemming from lexical dissimilarities. We also investigate different methods to improve LM re-ranker performance and find these methods mainly useful for NQ. Taken together, our work identifies and explains weaknesses of LM re-rankers and points to the need for more adversarial and realistic datasets for their evaluation.
A Reality Check on Context Utilisation for Retrieval-Augmented Generation
Dec 22, 2024



Retrieval-augmented generation (RAG) helps address the limitations of the parametric knowledge embedded within a language model (LM). However, investigations of how LMs utilise retrieved information of varying complexity in real-world scenarios have been limited to synthetic contexts. We introduce DRUID (Dataset of Retrieved Unreliable, Insufficient and Difficult-to-understand contexts) with real-world queries and contexts manually annotated for stance. The dataset is based on the prototypical task of automated claim verification, for which automated retrieval of real-world evidence is crucial. We compare DRUID to synthetic datasets (CounterFact, ConflictQA) and find that artificial datasets often fail to represent the complex and diverse real-world context settings. We show that synthetic datasets exaggerate context characteristics rare in real retrieved data, which leads to inflated context utilisation results, as measured by our novel ACU score. Moreover, while previous work has mainly focused on singleton context characteristics to explain context utilisation, correlations between singleton context properties and ACU on DRUID are surprisingly small compared to other properties related to context source. Overall, our work underscores the need for real-world aligned context utilisation studies to represent and improve performance in real-world RAG settings.
Fact Recall, Heuristics or Pure Guesswork? Precise Interpretations of Language Models for Fact Completion
Oct 18, 2024Previous interpretations of language models (LMs) miss important distinctions in how these models process factual information. For example, given the query "Astrid Lindgren was born in" with the corresponding completion "Sweden", no difference is made between whether the prediction was based on having the exact knowledge of the birthplace of the Swedish author or assuming that a person with a Swedish-sounding name was born in Sweden. In this paper, we investigate four different prediction scenarios for which the LM can be expected to show distinct behaviors. These scenarios correspond to different levels of model reliability and types of information being processed - some being less desirable for factual predictions. To facilitate precise interpretations of LMs for fact completion, we propose a model-specific recipe called PrISM for constructing datasets with examples of each scenario based on a set of diagnostic criteria. We apply a popular interpretability method, causal tracing (CT), to the four prediction scenarios and find that while CT produces different results for each scenario, aggregations over a set of mixed examples may only represent the results from the scenario with the strongest measured signal. In summary, we contribute tools for a more granular study of fact completion in language models and analyses that provide a more nuanced understanding of how LMs process fact-related queries.
The Effect of Scaling, Retrieval Augmentation and Form on the Factual Consistency of Language Models
Nov 02, 2023Large Language Models (LLMs) make natural interfaces to factual knowledge, but their usefulness is limited by their tendency to deliver inconsistent answers to semantically equivalent questions. For example, a model might predict both "Anne Redpath passed away in Edinburgh." and "Anne Redpath's life ended in London." In this work, we identify potential causes of inconsistency and evaluate the effectiveness of two mitigation strategies: up-scaling and augmenting the LM with a retrieval corpus. Our results on the LLaMA and Atlas models show that both strategies reduce inconsistency while retrieval augmentation is considerably more efficient. We further consider and disentangle the consistency contributions of different components of Atlas. For all LMs evaluated we find that syntactical form and other evaluation task artifacts impact consistency. Taken together, our results provide a better understanding of the factors affecting the factual consistency of language models.
How to Adapt Pre-trained Vision-and-Language Models to a Text-only Input?
Sep 19, 2022

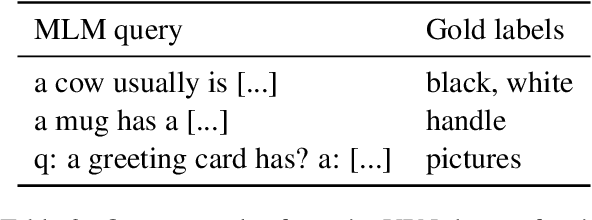
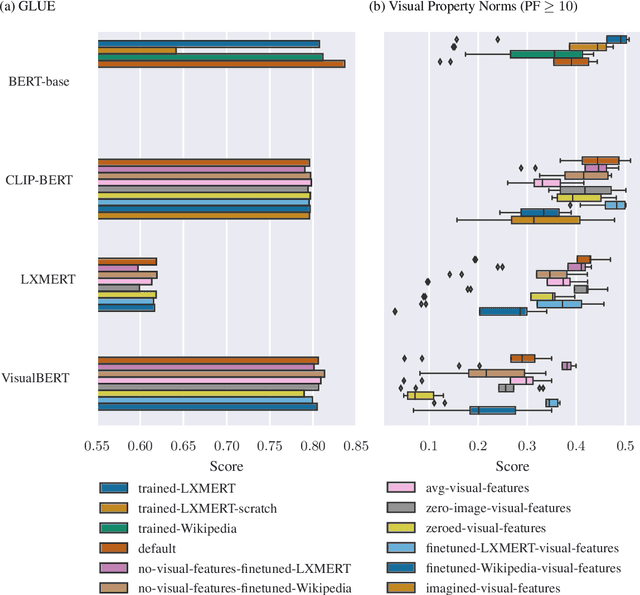
Current language models have been criticised for learning language from text alone without connection between words and their meaning. Consequently, multimodal training has been proposed as a way for creating models with better language understanding by providing the lacking connection. We focus on pre-trained multimodal vision-and-language (VL) models for which there already are some results on their language understanding capabilities. An unresolved issue with evaluating the linguistic skills of these models, however, is that there is no established method for adapting them to text-only input without out-of-distribution uncertainty. To find the best approach, we investigate and compare seven possible methods for adapting three different pre-trained VL models to text-only input. Our evaluations on both GLUE and Visual Property Norms (VPN) show that care should be put into adapting VL models to zero-shot text-only tasks, while the models are less sensitive to how we adapt them to non-zero-shot tasks. We also find that the adaptation methods perform differently for different models and that unimodal model counterparts perform on par with the VL models regardless of adaptation, indicating that current VL models do not necessarily gain better language understanding from their multimodal training.
What do Models Learn From Training on More Than Text? Measuring Visual Commonsense Knowledge
May 14, 2022

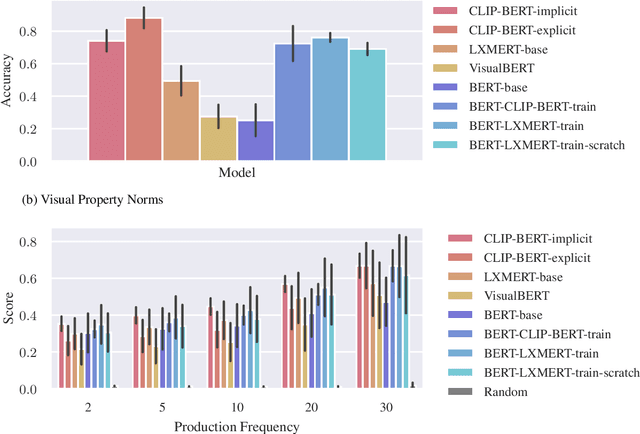
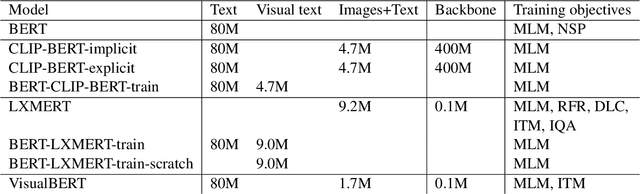
There are limitations in learning language from text alone. Therefore, recent focus has been on developing multimodal models. However, few benchmarks exist that can measure what language models learn about language from multimodal training. We hypothesize that training on a visual modality should improve on the visual commonsense knowledge in language models. Therefore, we introduce two evaluation tasks for measuring visual commonsense knowledge in language models and use them to evaluate different multimodal models and unimodal baselines. Primarily, we find that the visual commonsense knowledge is not significantly different between the multimodal models and unimodal baseline models trained on visual text data.
Transferring Knowledge from Vision to Language: How to Achieve it and how to Measure it?
Sep 30, 2021
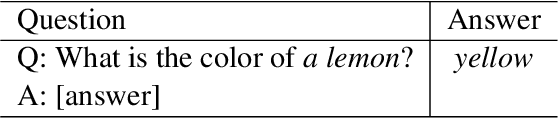

Large language models are known to suffer from the hallucination problem in that they are prone to output statements that are false or inconsistent, indicating a lack of knowledge. A proposed solution to this is to provide the model with additional data modalities that complements the knowledge obtained through text. We investigate the use of visual data to complement the knowledge of large language models by proposing a method for evaluating visual knowledge transfer to text for uni- or multimodal language models. The method is based on two steps, 1) a novel task querying for knowledge of memory colors, i.e. typical colors of well-known objects, and 2) filtering of model training data to clearly separate knowledge contributions. Additionally, we introduce a model architecture that involves a visual imagination step and evaluate it with our proposed method. We find that our method can successfully be used to measure visual knowledge transfer capabilities in models and that our novel model architecture shows promising results for leveraging multimodal knowledge in a unimodal setting.