 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWEb: A Large Web Dataset for the Scandinavian Languages
Oct 06, 2024



This paper presents the hitherto largest pretraining dataset for the Scandinavian languages: the Scandinavian WEb (SWEb), comprising over one trillion tokens. The paper details the collection and processing pipeline, and introduces a novel model-based text extractor that significantly reduces complexity in comparison with rule-based approaches. We also introduce a new cloze-style benchmark for evaluating language models in Swedish, and use this test to compare models trained on the SWEb data to models trained on FineWeb, with competitive results. All data, models and code are shared openly.
The Effect of Scaling, Retrieval Augmentation and Form on the Factual Consistency of Language Models
Nov 02, 2023Large Language Models (LLMs) make natural interfaces to factual knowledge, but their usefulness is limited by their tendency to deliver inconsistent answers to semantically equivalent questions. For example, a model might predict both "Anne Redpath passed away in Edinburgh." and "Anne Redpath's life ended in London." In this work, we identify potential causes of inconsistency and evaluate the effectiveness of two mitigation strategies: up-scaling and augmenting the LM with a retrieval corpus. Our results on the LLaMA and Atlas models show that both strategies reduce inconsistency while retrieval augmentation is considerably more efficient. We further consider and disentangle the consistency contributions of different components of Atlas. For all LMs evaluated we find that syntactical form and other evaluation task artifacts impact consistency. Taken together, our results provide a better understanding of the factors affecting the factual consistency of language models.
Surface-Based Retrieval Reduces Perplexity of Retrieval-Augmented Language Models
May 25, 2023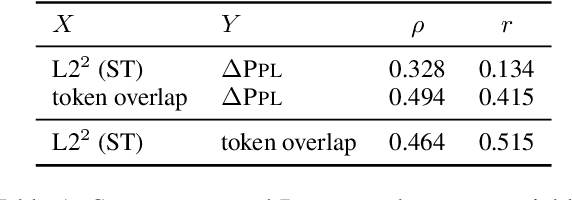

Augmenting language models with a retrieval mechanism has been shown to significantly improve their performance while keeping the number of parameters low. Retrieval-augmented models commonly rely on a semantic retrieval mechanism based on the similarity between dense representations of the query chunk and potential neighbors. In this paper, we study the state-of-the-art Retro model and observe that its performance gain is better explained by surface-level similarities, such as token overlap. Inspired by this, we replace the semantic retrieval in Retro with a surface-level method based on BM25, obtaining a significant reduction in perplexity. As full BM25 retrieval can be computationally costly for large datasets, we also apply it in a re-ranking scenario, gaining part of the perplexity reduction with minimal computational overhead.
On the Generalization Ability of Retrieval-Enhanced Transformers
Feb 23, 2023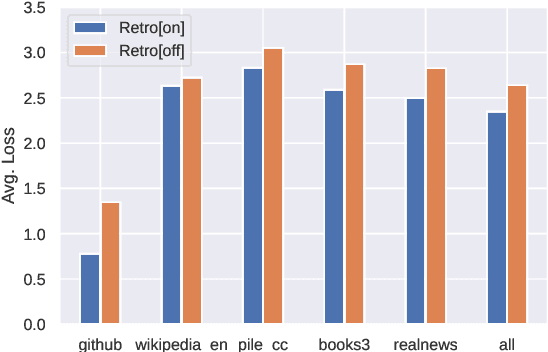
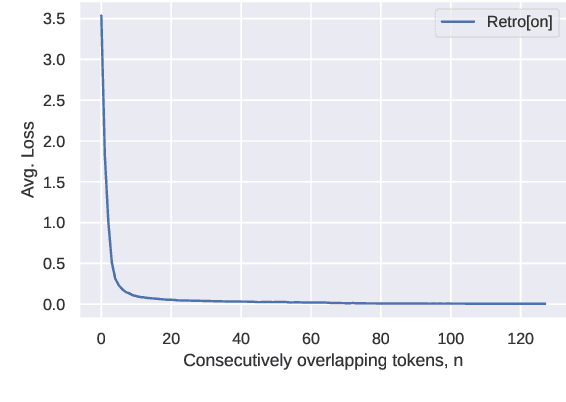
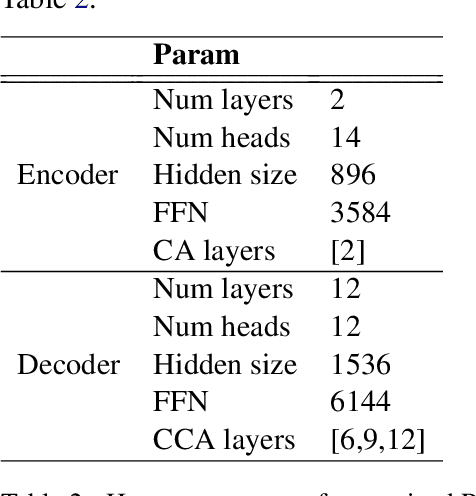
Recent work on the Retrieval-Enhanced Transformer (RETRO) model has shown that off-loading memory from trainable weights to a retrieval database can significantly improve language modeling and match the performance of non-retrieval models that are an order of magnitude larger in size. It has been suggested that at least some of this performance gain is due to non-trivial generalization based on both model weights and retrieval. In this paper, we try to better understand the relative contributions of these two components. We find that the performance gains from retrieval largely originate from overlapping tokens between the database and the test data, suggesting less non-trivial generalization than previously assumed. More generally, our results point to the challenges of evaluating the generalization of retrieval-augmented language models such as RETRO, as even limited token overlap may significantly decrease test-time loss. We release our code and model at https://github.com/TobiasNorlund/retro
Transferring Knowledge from Vision to Language: How to Achieve it and how to Measure it?
Sep 30, 2021
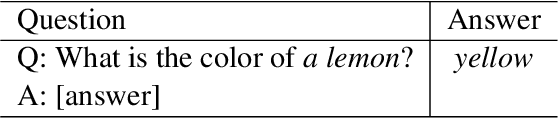

Large language models are known to suffer from the hallucination problem in that they are prone to output statements that are false or inconsistent, indicating a lack of knowledge. A proposed solution to this is to provide the model with additional data modalities that complements the knowledge obtained through text. We investigate the use of visual data to complement the knowledge of large language models by proposing a method for evaluating visual knowledge transfer to text for uni- or multimodal language models. The method is based on two steps, 1) a novel task querying for knowledge of memory colors, i.e. typical colors of well-known objects, and 2) filtering of model training data to clearly separate knowledge contributions. Additionally, we introduce a model architecture that involves a visual imagination step and evaluate it with our proposed method. We find that our method can successfully be used to measure visual knowledge transfer capabilities in models and that our novel model architecture shows promising results for leveraging multimodal knowledge in a unimodal setting.
Building a Swedish Open-Domain Conversational Language Model
Apr 12, 2021



We present on-going work of evaluating the, to our knowledge, first large generative language model trained to converse in Swedish, using data from the online discussion forum Flashback. We conduct a human evaluation pilot study that indicates the model is often able to respond to conversations in both a human-like and informative manner, on a diverse set of topics. While data from online forums can be useful to build conversational systems, we reflect on the negative consequences that incautious application might have, and the need for taking active measures to safeguard against them.