 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWEb: A Large Web Dataset for the Scandinavian Languages
Oct 06, 2024



This paper presents the hitherto largest pretraining dataset for the Scandinavian languages: the Scandinavian WEb (SWEb), comprising over one trillion tokens. The paper details the collection and processing pipeline, and introduces a novel model-based text extractor that significantly reduces complexity in comparison with rule-based approaches. We also introduce a new cloze-style benchmark for evaluating language models in Swedish, and use this test to compare models trained on the SWEb data to models trained on FineWeb, with competitive results. All data, models and code are shared openly.
GPT-SW3: An Autoregressive Language Model for the Nordic Languages
May 23, 2023This paper details the process of developing the first native large generative language model for the Nordic languages, GPT-SW3. We cover all parts of the development process, from data collection and processing, training configuration and instruction finetuning, to evaluation and considerations for release strategies. We hope that this paper can serve as a guide and reference for other researchers that undertake the development of large generative models for smaller languages.
The Nordic Pile: A 1.2TB Nordic Dataset for Language Modeling
Mar 30, 2023Pre-training Large Language Models (LLMs) require massive amounts of text data, and the performance of the LLMs typically correlates with the scale and quality of the datasets. This means that it may be challenging to build LLMs for smaller languages such as Nordic ones, where the availability of text corpora is limited. In order to facilitate the development of the LLMS in the Nordic languages, we curate a high-quality dataset consisting of 1.2TB of text, in all of the major North Germanic languages (Danish, Icelandic, Norwegian, and Swedish), as well as some high-quality English data. This paper details our considerations and processes for collecting, cleaning, and filtering the dataset.
Cross-lingual Transfer of Monolingual Models
Sep 15, 2021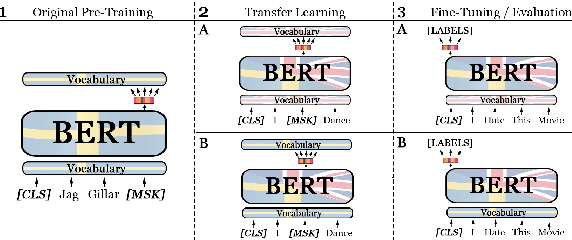
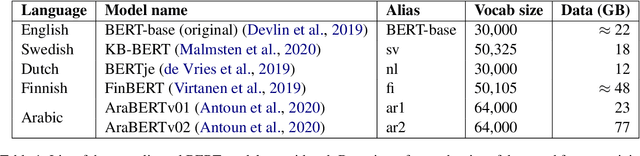
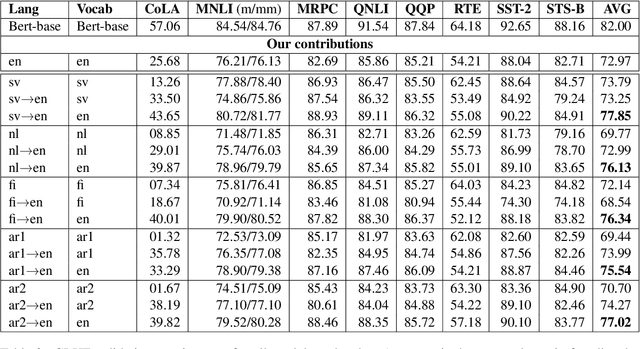
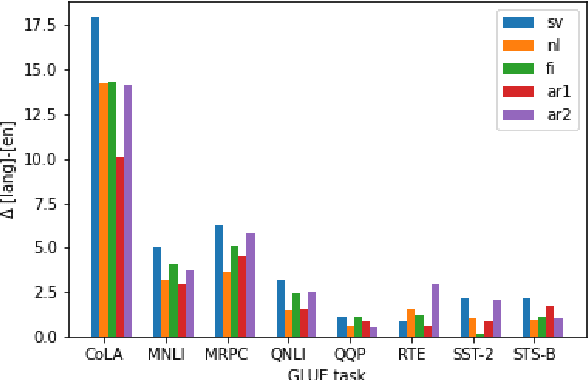
Recent studies in zero-shot cross-lingual learning using multilingual models have falsified the previous hypothesis that shared vocabulary and joint pre-training are the keys to cross-lingual generalization. Inspired by this advancement, we introduce a cross-lingual transfer method for monolingual models based on domain adaptation. We study the effects of such transfer from four different languages to English. Our experimental results on GLUE show that the transferred models outperform the native English model independently of the source language. After probing the English linguistic knowledge encoded in the representations before and after transfer, we find that semantic information is retained from the source language, while syntactic information is learned during transfer. Additionally, the results of evaluating the transferred models in source language tasks reveal that their performance in the source domain deteriorates after transfer.
Should we Stop Training More Monolingual Models, and Simply Use Machine Translation Instead?
Apr 21, 2021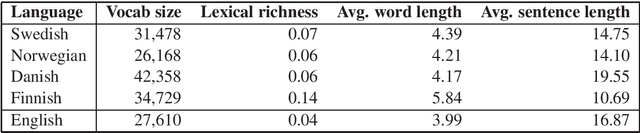


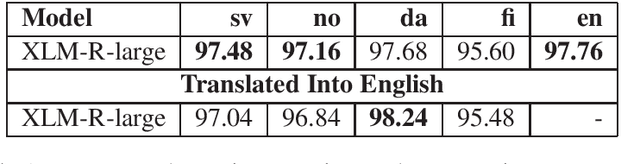
Most work in NLP makes the assumption that it is desirable to develop solutions in the native language in question. There is consequently a strong trend towards building native language models even for low-resource languages. This paper questions this development, and explores the idea of simply translating the data into English, thereby enabling the use of pretrained, and large-scale, English language models. We demonstrate empirically that a large English language model coupled with modern machine translation outperforms native language models in most Scandinavian languages. The exception to this is Finnish, which we assume is due to inferior translation quality. Our results suggest that machine translation is a mature technology, which raises a serious counter-argument for training native language models for low-resource languages. This paper therefore strives to make a provocative but important point. As English language models are improving at an unprecedented pace, which in turn improves machine translation, it is from an empirical and environmental stand-point more effective to translate data from low-resource languages into English, than to build language models for such languages.
Why Not Simply Translate? A First Swedish Evaluation Benchmark for Semantic Similarity
Sep 07, 2020

This paper presents the first Swedish evaluation benchmark for textual semantic similarity. The benchmark is compiled by simply running the English STS-B dataset through the Google machine translation API. This paper discusses potential problems with using such a simple approach to compile a Swedish evaluation benchmark, including translation errors, vocabulary variation, and productive compounding. Despite some obvious problems with the resulting dataset, we use the benchmark to compare the majority of the currently existing Swedish text representations, demonstrating that native models outperform multilingual ones, and that simple bag of words performs remarkably well.
Automatic Extraction of Personality from Text: Challenges and Opportunities
Oct 22, 2019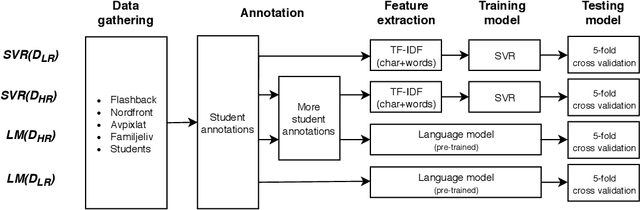
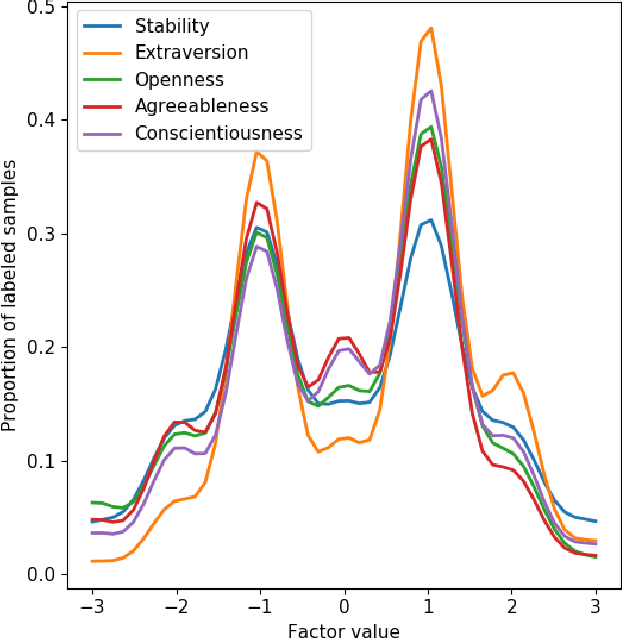


In this study, we examined the possibility to extract personality traits from a text. We created an extensive dataset by having experts annotate personality traits in a large number of texts from multiple online sources. From these annotated texts, we selected a sample and made further annotations ending up in a large low-reliability dataset and a small high-reliability dataset. We then used the two datasets to train and test several machine learning models to extract personality from text, including a language model. Finally, we evaluated our best models in the wild, on datasets from different domains. Our results show that the models based on the small high-reliability dataset performed better (in terms of $\textrm{R}^2$) than models based on large low-reliability dataset. Also, language model based on small high-reliability dataset performed better than the random baseline. Finally, and more importantly, the results showed our best model did not perform better than the random baseline when tested in the wild. Taken together, our results show that determining personality traits from a text remains a challenge and that no firm conclusions can be made on model performance before testing in the wild.
Monitoring Targeted Hate in Online Environments
Mar 13, 2018
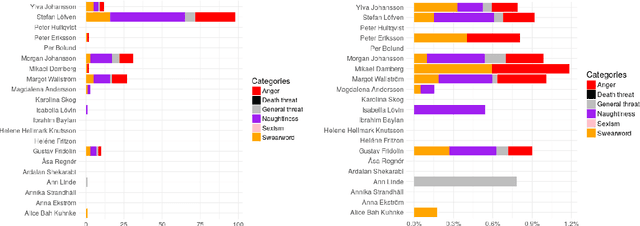


Hateful comments, swearwords and sometimes even death threats are becoming a reality for many people today in online environments. This is especially true for journalists, politicians, artists, and other public figures. This paper describes how hate directed towards individuals can be measured in online environments using a simple dictionary-based approach. We present a case study on Swedish politicians, and use examples from this study to discuss shortcomings of the proposed dictionary-based approach. We also outline possibilities for potential refinements of the proposed approach.