 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnotated Job Ads with Named Entity Recognition
Oct 18, 2023
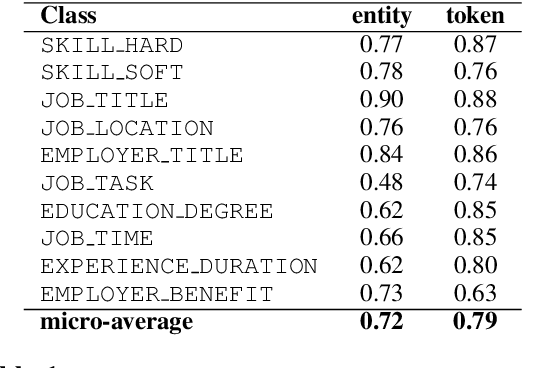
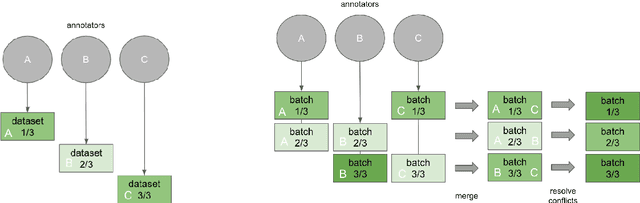

We have trained a named entity recognition (NER) model that screens Swedish job ads for different kinds of useful information (e.g. skills required from a job seeker). It was obtained by fine-tuning KB-BERT. The biggest challenge we faced was the creation of a labelled dataset, which required manual annotation. This paper gives an overview of the methods we employed to make the annotation process more efficient and to ensure high quality data. We also report on the performance of the resulting model.
Text Annotation Handbook: A Practical Guide for Machine Learning Projects
Oct 18, 2023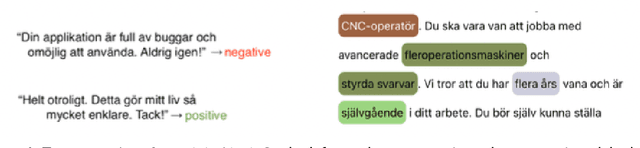
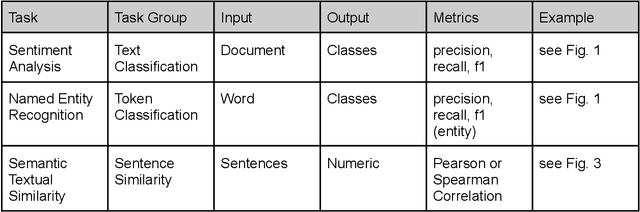

This handbook is a hands-on guide on how to approach text annotation tasks. It provides a gentle introduction to the topic, an overview of theoretical concepts as well as practical advice. The topics covered are mostly technical, but business, ethical and regulatory issues are also touched upon. The focus lies on readability and conciseness rather than completeness and scientific rigor. Experience with annotation and knowledge of machine learning are useful but not required. The document may serve as a primer or reference book for a wide range of professions such as team leaders, project managers, IT architects, software developers and machine learning engineers.
GPT-SW3: An Autoregressive Language Model for the Nordic Languages
May 23, 2023This paper details the process of developing the first native large generative language model for the Nordic languages, GPT-SW3. We cover all parts of the development process, from data collection and processing, training configuration and instruction finetuning, to evaluation and considerations for release strategies. We hope that this paper can serve as a guide and reference for other researchers that undertake the development of large generative models for smaller languages.
The Nordic Pile: A 1.2TB Nordic Dataset for Language Modeling
Mar 30, 2023Pre-training Large Language Models (LLMs) require massive amounts of text data, and the performance of the LLMs typically correlates with the scale and quality of the datasets. This means that it may be challenging to build LLMs for smaller languages such as Nordic ones, where the availability of text corpora is limited. In order to facilitate the development of the LLMS in the Nordic languages, we curate a high-quality dataset consisting of 1.2TB of text, in all of the major North Germanic languages (Danish, Icelandic, Norwegian, and Swedish), as well as some high-quality English data. This paper details our considerations and processes for collecting, cleaning, and filtering the dataset.