 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWEb: A Large Web Dataset for the Scandinavian Languages
Oct 06, 2024



This paper presents the hitherto largest pretraining dataset for the Scandinavian languages: the Scandinavian WEb (SWEb), comprising over one trillion tokens. The paper details the collection and processing pipeline, and introduces a novel model-based text extractor that significantly reduces complexity in comparison with rule-based approaches. We also introduce a new cloze-style benchmark for evaluating language models in Swedish, and use this test to compare models trained on the SWEb data to models trained on FineWeb, with competitive results. All data, models and code are shared openly.
GPT-SW3: An Autoregressive Language Model for the Nordic Languages
May 23, 2023This paper details the process of developing the first native large generative language model for the Nordic languages, GPT-SW3. We cover all parts of the development process, from data collection and processing, training configuration and instruction finetuning, to evaluation and considerations for release strategies. We hope that this paper can serve as a guide and reference for other researchers that undertake the development of large generative models for smaller languages.
The Nordic Pile: A 1.2TB Nordic Dataset for Language Modeling
Mar 30, 2023Pre-training Large Language Models (LLMs) require massive amounts of text data, and the performance of the LLMs typically correlates with the scale and quality of the datasets. This means that it may be challenging to build LLMs for smaller languages such as Nordic ones, where the availability of text corpora is limited. In order to facilitate the development of the LLMS in the Nordic languages, we curate a high-quality dataset consisting of 1.2TB of text, in all of the major North Germanic languages (Danish, Icelandic, Norwegian, and Swedish), as well as some high-quality English data. This paper details our considerations and processes for collecting, cleaning, and filtering the dataset.
Cross-lingual Transfer of Monolingual Models
Sep 15, 2021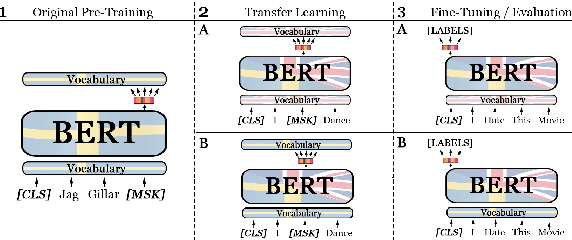
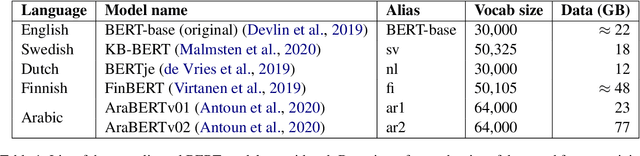
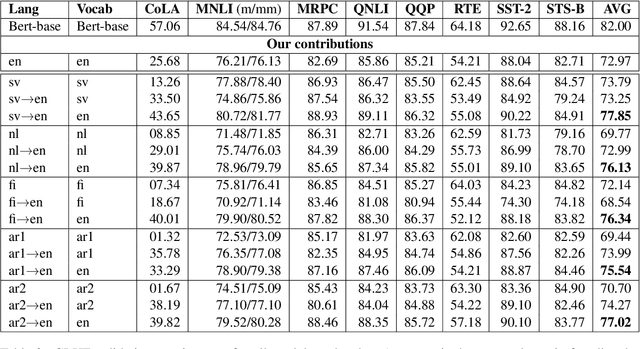
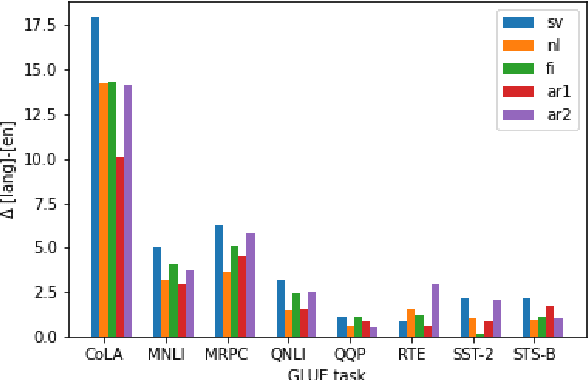
Recent studies in zero-shot cross-lingual learning using multilingual models have falsified the previous hypothesis that shared vocabulary and joint pre-training are the keys to cross-lingual generalization. Inspired by this advancement, we introduce a cross-lingual transfer method for monolingual models based on domain adaptation. We study the effects of such transfer from four different languages to English. Our experimental results on GLUE show that the transferred models outperform the native English model independently of the source language. After probing the English linguistic knowledge encoded in the representations before and after transfer, we find that semantic information is retained from the source language, while syntactic information is learned during transfer. Additionally, the results of evaluating the transferred models in source language tasks reveal that their performance in the source domain deteriorates after transfer.
R-grams: Unsupervised Learning of Semantic Units in Natural Language
Aug 14, 2018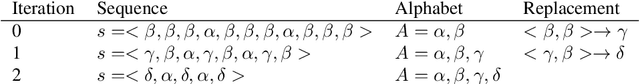
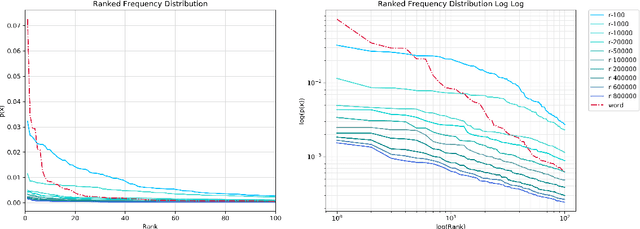

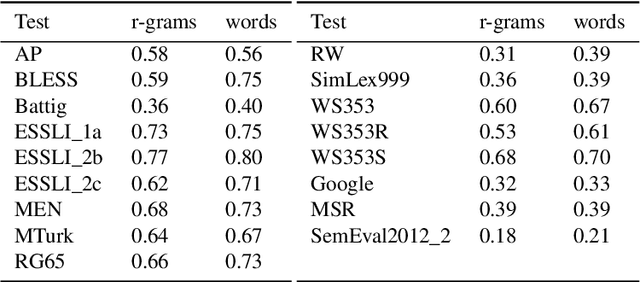
This paper introduces a novel type of data-driven segmented unit that we call r-grams. We illustrate one algorithm for calculating r-grams, and discuss its properties and impact on the frequency distribution of text representations. The proposed approach is evaluated by demonstrating its viability in embedding techniques, both in monolingual and multilingual test settings. We also provide a number of qualitative examples of the proposed methodology, demonstrating its viability as a language-invariant segmentation procedure.