 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtreme Multi-Label Skill Extraction Training using Large Language Models
Jul 20, 2023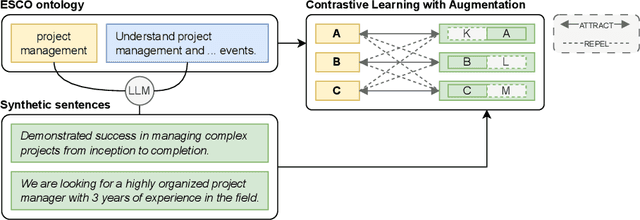
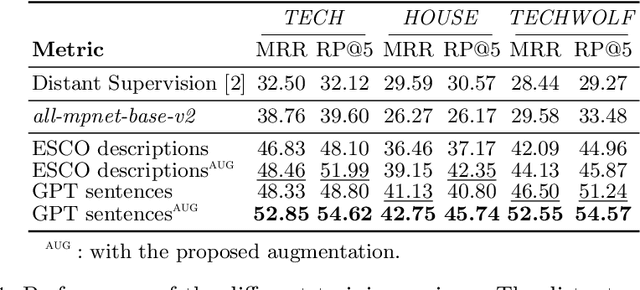
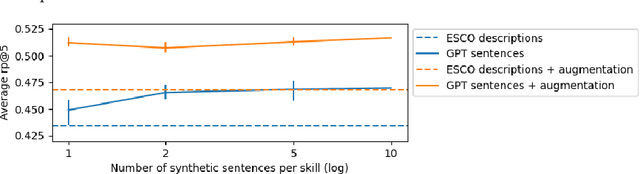
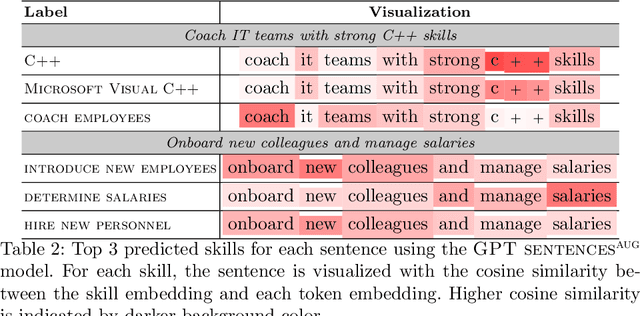
Online job ads serve as a valuable source of information for skill requirements, playing a crucial role in labor market analysis and e-recruitment processes. Since such ads are typically formatted in free text, natural language processing (NLP) technologies are required to automatically process them. We specifically focus on the task of detecting skills (mentioned literally, or implicitly described) and linking them to a large skill ontology, making it a challenging case of extreme multi-label classification (XMLC). Given that there is no sizable labeled (training) dataset are available for this specific XMLC task, we propose techniques to leverage general Large Language Models (LLMs). We describe a cost-effective approach to generate an accurate, fully synthetic labeled dataset for skill extraction, and present a contrastive learning strategy that proves effective in the task. Our results across three skill extraction benchmarks show a consistent increase of between 15 to 25 percentage points in \textit{R-Precision@5} compared to previously published results that relied solely on distant supervision through literal matches.
The Nordic Pile: A 1.2TB Nordic Dataset for Language Modeling
Mar 30, 2023Pre-training Large Language Models (LLMs) require massive amounts of text data, and the performance of the LLMs typically correlates with the scale and quality of the datasets. This means that it may be challenging to build LLMs for smaller languages such as Nordic ones, where the availability of text corpora is limited. In order to facilitate the development of the LLMS in the Nordic languages, we curate a high-quality dataset consisting of 1.2TB of text, in all of the major North Germanic languages (Danish, Icelandic, Norwegian, and Swedish), as well as some high-quality English data. This paper details our considerations and processes for collecting, cleaning, and filtering the dataset.
Injecting Knowledge Base Information into End-to-End Joint Entity and Relation Extraction and Coreference Resolution
Jul 05, 2021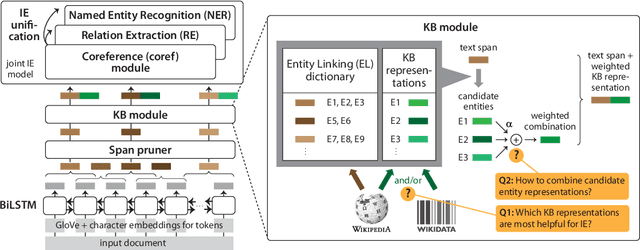

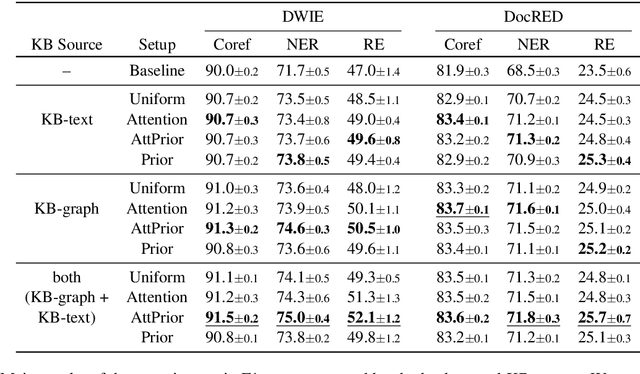

We consider a joint information extraction (IE) model, solving named entity recognition, coreference resolution and relation extraction jointly over the whole document. In particular, we study how to inject information from a knowledge base (KB) in such IE model, based on unsupervised entity linking. The used KB entity representations are learned from either (i) hyperlinked text documents (Wikipedia), or (ii) a knowledge graph (Wikidata), and appear complementary in raising IE performance. Representations of corresponding entity linking (EL) candidates are added to text span representations of the input document, and we experiment with (i) taking a weighted average of the EL candidate representations based on their prior (in Wikipedia), and (ii) using an attention scheme over the EL candidate list. Results demonstrate an increase of up to 5% F1-score for the evaluated IE tasks on two datasets. Despite a strong performance of the prior-based model, our quantitative and qualitative analysis reveals the advantage of using the attention-based approach.