 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLASP: Defending Hybrid Large Language Models Against Hidden State Poisoning Attacks
Mar 12, 2026State space models (SSMs) like Mamba have gained significant traction as efficient alternatives to Transformers, achieving linear complexity while maintaining competitive performance. However, Hidden State Poisoning Attacks (HiSPAs), a recently discovered vulnerability that corrupts SSM memory through adversarial strings, pose a critical threat to these architectures and their hybrid variants. Framing the HiSPA mitigation task as a binary classification problem at the token level, we introduce the CLASP model to defend against this threat. CLASP exploits distinct patterns in Mamba's block output embeddings (BOEs) and uses an XGBoost classifier to identify malicious tokens with minimal computational overhead. We consider a realistic scenario in which both SSMs and HiSPAs are likely to be used: an LLM screening résumés to identify the best candidates for a role. Evaluated on a corpus of 2,483 résumés totaling 9.5M tokens with controlled injections, CLASP achieves 95.9% token-level F1 score and 99.3% document-level F1 score on malicious tokens detection. Crucially, the model generalizes to unseen attack patterns: under leave-one-out cross-validation, performance remains high (96.9% document-level F1), while under clustered cross-validation with structurally novel triggers, it maintains useful detection capability (91.6% average document-level F1). Operating independently of any downstream model, CLASP processes 1,032 tokens per second with under 4GB VRAM consumption, potentially making it suitable for real-world deployment as a lightweight front-line defense for SSM-based and hybrid architectures. All code and detailed results are available at https://anonymous.4open.science/r/hispikes-91C0.
The Entropic Signature of Class Speciation in Diffusion Models
Feb 10, 2026Diffusion models do not recover semantic structure uniformly over time. Instead, samples transition from semantic ambiguity to class commitment within a narrow regime. Recent theoretical work attributes this transition to dynamical instabilities along class-separating directions, but practical methods to detect and exploit these windows in trained models are still limited. We show that tracking the class-conditional entropy of a latent semantic variable given the noisy state provides a reliable signature of these transition regimes. By restricting the entropy to semantic partitions, the entropy can furthermore resolve semantic decisions at different levels of abstraction. We analyze this behavior in high-dimensional Gaussian mixture models and show that the entropy rate concentrates on the same logarithmic time scale as the speciation symmetry-breaking instability previously identified in variance-preserving diffusion. We validate our method on EDM2-XS and Stable Diffusion 1.5, where class-conditional entropy consistently isolates the noise regimes critical for semantic structure formation. Finally, we use our framework to quantify how guidance redistributes semantic information over time. Together, these results connect information-theoretic and statistical physics perspectives on diffusion and provide a principled basis for time-localized control.
Rank-Learner: Orthogonal Ranking of Treatment Effects
Feb 03, 2026Many decision-making problems require ranking individuals by their treatment effects rather than estimating the exact effect magnitudes. Examples include prioritizing patients for preventive care interventions, or ranking customers by the expected incremental impact of an advertisement. Surprisingly, while causal effect estimation has received substantial attention in the literature, the problem of directly learning rankings of treatment effects has largely remained unexplored. In this paper, we introduce Rank-Learner, a novel two-stage learner that directly learns the ranking of treatment effects from observational data. We first show that naive approaches based on precise treatment effect estimation solve a harder problem than necessary for ranking, while our Rank-Learner optimizes a pairwise learning objective that recovers the true treatment effect ordering, without explicit CATE estimation. We further show that our Rank-Learner is Neyman-orthogonal and thus comes with strong theoretical guarantees, including robustness to estimation errors in the nuisance functions. In addition, our Rank-Learner is model-agnostic, and can be instantiated with arbitrary machine learning models (e.g., neural networks). We demonstrate the effectiveness of our method through extensive experiments where Rank-Learner consistently outperforms standard CATE estimators and non-orthogonal ranking methods. Overall, we provide practitioners with a new, orthogonal two-stage learner for ranking individuals by their treatment effects.
Dynamic Expert-Guided Model Averaging for Causal Discovery
Jan 23, 2026Understanding causal relationships is critical for healthcare. Accurate causal models provide a means to enhance the interpretability of predictive models, and furthermore a basis for counterfactual and interventional reasoning and the estimation of treatment effects. However, would-be practitioners of causal discovery face a dizzying array of algorithms without a clear best choice. This abundance of competitive algorithms makes ensembling a natural choice for practical applications. At the same time, real-world use cases frequently face challenges that violate the assumptions of common causal discovery algorithms, forcing heavy reliance on expert knowledge. Inspired by recent work on dynamically requested expert knowledge and LLMs as experts, we present a flexible model averaging method leveraging dynamically requested expert knowledge to ensemble a diverse array of causal discovery algorithms. Experiments demonstrate the efficacy of our method with imperfect experts such as LLMs on both clean and noisy data. We also analyze the impact of different degrees of expert correctness and assess the capabilities of LLMs for clinical causal discovery, providing valuable insights for practitioners.
Hidden State Poisoning Attacks against Mamba-based Language Models
Jan 06, 2026State space models (SSMs) like Mamba offer efficient alternatives to Transformer-based language models, with linear time complexity. Yet, their adversarial robustness remains critically unexplored. This paper studies the phenomenon whereby specific short input phrases induce a partial amnesia effect in such models, by irreversibly overwriting information in their hidden states, referred to as a Hidden State Poisoning Attack (HiSPA). Our benchmark RoBench25 allows evaluating a model's information retrieval capabilities when subject to HiSPAs, and confirms the vulnerability of SSMs against such attacks. Even a recent 52B hybrid SSM-Transformer model from the Jamba family collapses on RoBench25 under optimized HiSPA triggers, whereas pure Transformers do not. We also observe that HiSPA triggers significantly weaken the Jamba model on the popular Open-Prompt-Injections benchmark, unlike pure Transformers. Finally, our interpretability study reveals patterns in Mamba's hidden layers during HiSPAs that could be used to build a HiSPA mitigation system. The full code and data to reproduce the experiments can be found at https://anonymous.4open.science/r/hispa_anonymous-5DB0.
Modeling Clinical Uncertainty in Radiology Reports: from Explicit Uncertainty Markers to Implicit Reasoning Pathways
Nov 06, 2025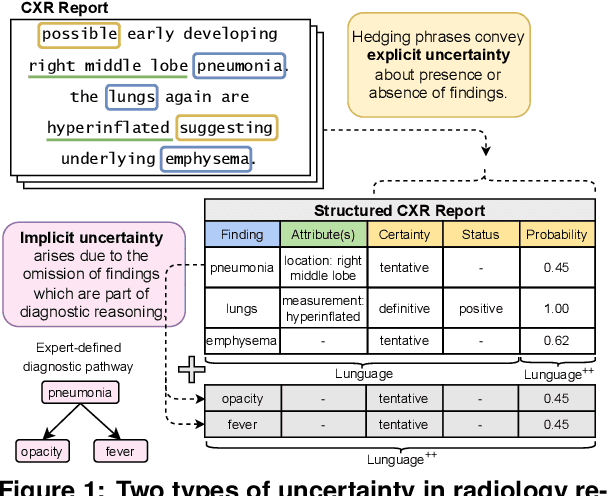
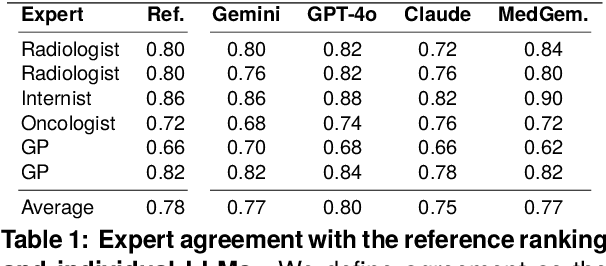
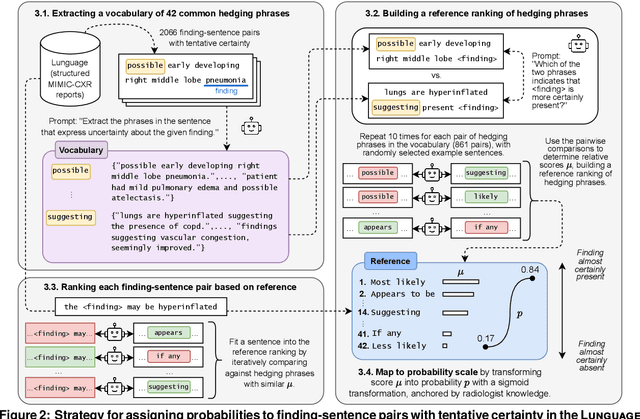
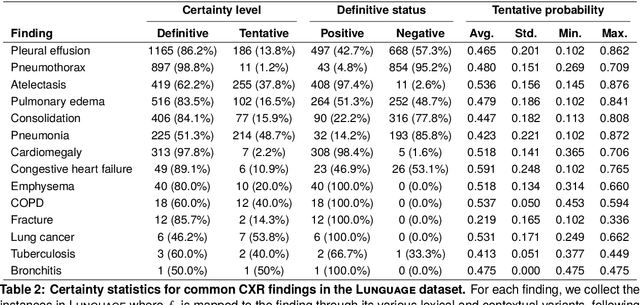
Radiology reports are invaluable for clinical decision-making and hold great potential for automated analysis when structured into machine-readable formats. These reports often contain uncertainty, which we categorize into two distinct types: (i) Explicit uncertainty reflects doubt about the presence or absence of findings, conveyed through hedging phrases. These vary in meaning depending on the context, making rule-based systems insufficient to quantify the level of uncertainty for specific findings; (ii) Implicit uncertainty arises when radiologists omit parts of their reasoning, recording only key findings or diagnoses. Here, it is often unclear whether omitted findings are truly absent or simply unmentioned for brevity. We address these challenges with a two-part framework. We quantify explicit uncertainty by creating an expert-validated, LLM-based reference ranking of common hedging phrases, and mapping each finding to a probability value based on this reference. In addition, we model implicit uncertainty through an expansion framework that systematically adds characteristic sub-findings derived from expert-defined diagnostic pathways for 14 common diagnoses. Using these methods, we release Lunguage++, an expanded, uncertainty-aware version of the Lunguage benchmark of fine-grained structured radiology reports. This enriched resource enables uncertainty-aware image classification, faithful diagnostic reasoning, and new investigations into the clinical impact of diagnostic uncertainty.
Personalized Treatment Effect Estimation from Unstructured Data
Jul 28, 2025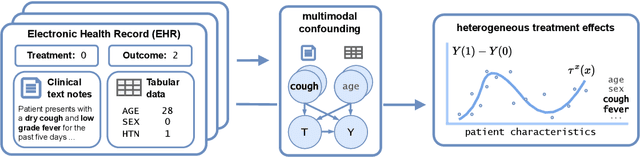

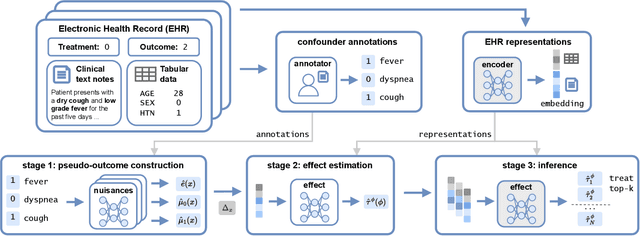
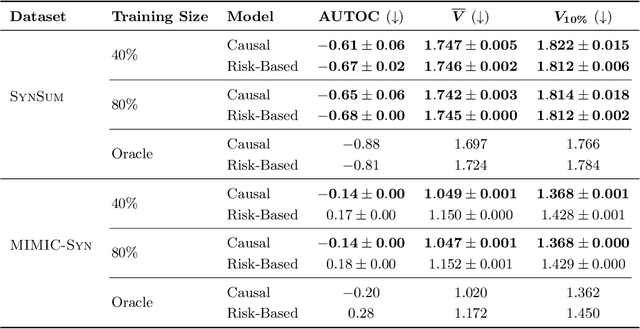
Existing methods for estimating personalized treatment effects typically rely on structured covariates, limiting their applicability to unstructured data. Yet, leveraging unstructured data for causal inference has considerable application potential, for instance in healthcare, where clinical notes or medical images are abundant. To this end, we first introduce an approximate 'plug-in' method trained directly on the neural representations of unstructured data. However, when these fail to capture all confounding information, the method may be subject to confounding bias. We therefore introduce two theoretically grounded estimators that leverage structured measurements of the confounders during training, but allow estimating personalized treatment effects purely from unstructured inputs, while avoiding confounding bias. When these structured measurements are only available for a non-representative subset of the data, these estimators may suffer from sampling bias. To address this, we further introduce a regression-based correction that accounts for the non-uniform sampling, assuming the sampling mechanism is known or can be well-estimated. Our experiments on two benchmark datasets show that the plug-in method, directly trainable on large unstructured datasets, achieves strong empirical performance across all settings, despite its simplicity.
Improved Allergy Wheal Detection for the Skin Prick Automated Test Device
Jun 06, 2025Background: The skin prick test (SPT) is the gold standard for diagnosing sensitization to inhalant allergies. The Skin Prick Automated Test (SPAT) device was designed for increased consistency in test results, and captures 32 images to be jointly used for allergy wheal detection and delineation, which leads to a diagnosis. Materials and Methods: Using SPAT data from $868$ patients with suspected inhalant allergies, we designed an automated method to detect and delineate wheals on these images. To this end, $10,416$ wheals were manually annotated by drawing detailed polygons along the edges. The unique data-modality of the SPAT device, with $32$ images taken under distinct lighting conditions, requires a custom-made approach. Our proposed method consists of two parts: a neural network component that segments the wheals on the pixel level, followed by an algorithmic and interpretable approach for detecting and delineating the wheals. Results: We evaluate the performance of our method on a hold-out validation set of $217$ patients. As a baseline we use a single conventionally lighted image per SPT as input to our method. Conclusion: Using the $32$ SPAT images under various lighting conditions offers a considerably higher accuracy than a single image in conventional, uniform light.
Efficient Text Encoders for Labor Market Analysis
May 30, 2025Labor market analysis relies on extracting insights from job advertisements, which provide valuable yet unstructured information on job titles and corresponding skill requirements. While state-of-the-art methods for skill extraction achieve strong performance, they depend on large language models (LLMs), which are computationally expensive and slow. In this paper, we propose \textbf{ConTeXT-match}, a novel contrastive learning approach with token-level attention that is well-suited for the extreme multi-label classification task of skill classification. \textbf{ConTeXT-match} significantly improves skill extraction efficiency and performance, achieving state-of-the-art results with a lightweight bi-encoder model. To support robust evaluation, we introduce \textbf{Skill-XL}, a new benchmark with exhaustive, sentence-level skill annotations that explicitly address the redundancy in the large label space. Finally, we present \textbf{JobBERT V2}, an improved job title normalization model that leverages extracted skills to produce high-quality job title representations. Experiments demonstrate that our models are efficient, accurate, and scalable, making them ideal for large-scale, real-time labor market analysis.
Error Optimization: Overcoming Exponential Signal Decay in Deep Predictive Coding Networks
May 26, 2025Predictive Coding (PC) offers a biologically plausible alternative to backpropagation for neural network training, yet struggles with deeper architectures. This paper identifies the root cause: an inherent signal decay problem where gradients attenuate exponentially with depth, becoming computationally negligible due to numerical precision constraints. To address this fundamental limitation, we introduce Error Optimization (EO), a novel reparameterization that preserves PC's theoretical properties while eliminating signal decay. By optimizing over prediction errors rather than states, EO enables signals to reach all layers simultaneously and without attenuation, converging orders of magnitude faster than standard PC. Experiments across multiple architectures and datasets demonstrate that EO matches backpropagation's performance even for deeper models where conventional PC struggles. Besides practical improvements, our work provides theoretical insight into PC dynamics and establishes a foundation for scaling biologically-inspired learning to deeper architectures on digital hardware and beyond.