 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Work Embeddings: Contrastive Learning of a Bidirectional Multi-task Ranker
Nov 11, 2025



Workforce transformation across diverse industries has driven an increased demand for specialized natural language processing capabilities. Nevertheless, tasks derived from work-related contexts inherently reflect real-world complexities, characterized by long-tailed distributions, extreme multi-label target spaces, and scarce data availability. The rise of generalist embedding models prompts the question of their performance in the work domain, especially as progress in the field has focused mainly on individual tasks. To this end, we introduce WorkBench, the first unified evaluation suite spanning six work-related tasks formulated explicitly as ranking problems, establishing a common ground for multi-task progress. Based on this benchmark, we find significant positive cross-task transfer, and use this insight to compose task-specific bipartite graphs from real-world data, synthetically enriched through grounding. This leads to Unified Work Embeddings (UWE), a task-agnostic bi-encoder that exploits our training-data structure with a many-to-many InfoNCE objective, and leverages token-level embeddings with task-agnostic soft late interaction. UWE demonstrates zero-shot ranking performance on unseen target spaces in the work domain, enables low-latency inference by caching the task target space embeddings, and shows significant gains in macro-averaged MAP and RP@10 over generalist embedding models.
Efficient Text Encoders for Labor Market Analysis
May 30, 2025Labor market analysis relies on extracting insights from job advertisements, which provide valuable yet unstructured information on job titles and corresponding skill requirements. While state-of-the-art methods for skill extraction achieve strong performance, they depend on large language models (LLMs), which are computationally expensive and slow. In this paper, we propose \textbf{ConTeXT-match}, a novel contrastive learning approach with token-level attention that is well-suited for the extreme multi-label classification task of skill classification. \textbf{ConTeXT-match} significantly improves skill extraction efficiency and performance, achieving state-of-the-art results with a lightweight bi-encoder model. To support robust evaluation, we introduce \textbf{Skill-XL}, a new benchmark with exhaustive, sentence-level skill annotations that explicitly address the redundancy in the large label space. Finally, we present \textbf{JobBERT V2}, an improved job title normalization model that leverages extracted skills to produce high-quality job title representations. Experiments demonstrate that our models are efficient, accurate, and scalable, making them ideal for large-scale, real-time labor market analysis.
ChocoLlama: Lessons Learned From Teaching Llamas Dutch
Dec 10, 2024While Large Language Models (LLMs) have shown remarkable capabilities in natural language understanding and generation, their performance often lags in lower-resource, non-English languages due to biases in the training data. In this work, we explore strategies for adapting the primarily English LLMs (Llama-2 and Llama-3) to Dutch, a language spoken by 30 million people worldwide yet often underrepresented in LLM development. We collect 104GB of Dutch text ($32$B tokens) from various sources to first apply continued pretraining using low-rank adaptation (LoRA), complemented with Dutch posttraining strategies provided by prior work. For Llama-2, we consider using (i) the tokenizer of the original model, and (ii) training a new, Dutch-specific tokenizer combined with embedding reinitialization. We evaluate our adapted models, ChocoLlama-2, both on standard benchmarks and a novel Dutch benchmark, ChocoLlama-Bench. Our results demonstrate that LoRA can effectively scale for language adaptation, and that tokenizer modification with careful weight reinitialization can improve performance. Notably, Llama-3 was released during the course of this project and, upon evaluation, demonstrated superior Dutch capabilities compared to our Dutch-adapted versions of Llama-2. We hence apply the same adaptation technique to Llama-3, using its original tokenizer. While our adaptation methods enhanced Llama-2's Dutch capabilities, we found limited gains when applying the same techniques to Llama-3. This suggests that for ever improving, multilingual foundation models, language adaptation techniques may benefit more from focusing on language-specific posttraining rather than on continued pretraining. We hope this work contributes to the broader understanding of adapting LLMs to lower-resource languages, and to the development of Dutch LLMs in particular.
SkillMatch: Evaluating Self-supervised Learning of Skill Relatedness
Oct 07, 2024


Accurately modeling the relationships between skills is a crucial part of human resources processes such as recruitment and employee development. Yet, no benchmarks exist to evaluate such methods directly. We construct and release SkillMatch, a benchmark for the task of skill relatedness, based on expert knowledge mining from millions of job ads. Additionally, we propose a scalable self-supervised learning technique to adapt a Sentence-BERT model based on skill co-occurrence in job ads. This new method greatly surpasses traditional models for skill relatedness as measured on SkillMatch. By releasing SkillMatch publicly, we aim to contribute a foundation for research towards increased accuracy and transparency of skill-based recommendation systems.
On the Biased Assessment of Expert Finding Systems
Oct 07, 2024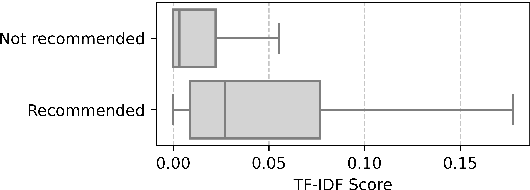

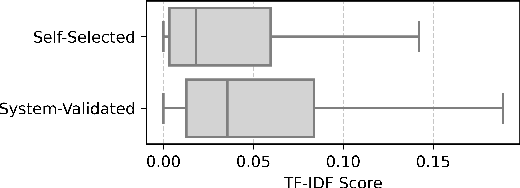
In large organisations, identifying experts on a given topic is crucial in leveraging the internal knowledge spread across teams and departments. So-called enterprise expert retrieval systems automatically discover and structure employees' expertise based on the vast amount of heterogeneous data available about them and the work they perform. Evaluating these systems requires comprehensive ground truth expert annotations, which are hard to obtain. Therefore, the annotation process typically relies on automated recommendations of knowledge areas to validate. This case study provides an analysis of how these recommendations can impact the evaluation of expert finding systems. We demonstrate on a popular benchmark that system-validated annotations lead to overestimated performance of traditional term-based retrieval models and even invalidate comparisons with more recent neural methods. We also augment knowledge areas with synonyms to uncover a strong bias towards literal mentions of their constituent words. Finally, we propose constraints to the annotation process to prevent these biased evaluations, and show that this still allows annotation suggestions of high utility. These findings should inform benchmark creation or selection for expert finding, to guarantee meaningful comparison of methods.
Career Path Prediction using Resume Representation Learning and Skill-based Matching
Oct 24, 2023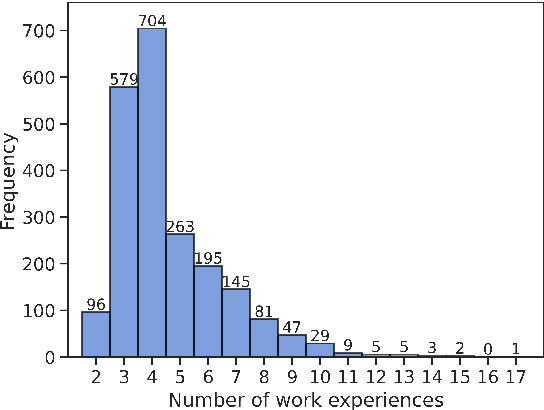
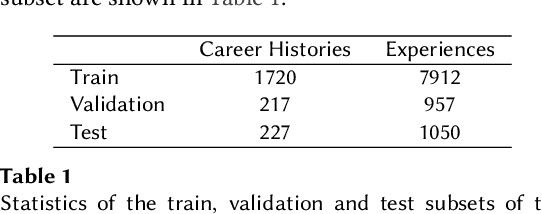


The impact of person-job fit on job satisfaction and performance is widely acknowledged, which highlights the importance of providing workers with next steps at the right time in their career. This task of predicting the next step in a career is known as career path prediction, and has diverse applications such as turnover prevention and internal job mobility. Existing methods to career path prediction rely on large amounts of private career history data to model the interactions between job titles and companies. We propose leveraging the unexplored textual descriptions that are part of work experience sections in resumes. We introduce a structured dataset of 2,164 anonymized career histories, annotated with ESCO occupation labels. Based on this dataset, we present a novel representation learning approach, CareerBERT, specifically designed for work history data. We develop a skill-based model and a text-based model for career path prediction, which achieve 35.24% and 39.61% recall@10 respectively on our dataset. Finally, we show that both approaches are complementary as a hybrid approach achieves the strongest result with 43.01% recall@10.
Extreme Multi-Label Skill Extraction Training using Large Language Models
Jul 20, 2023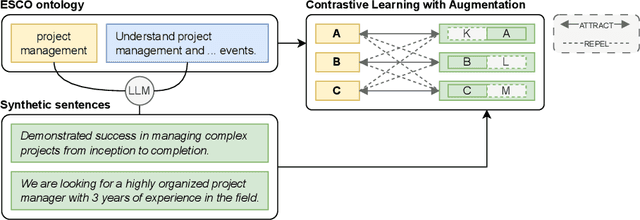
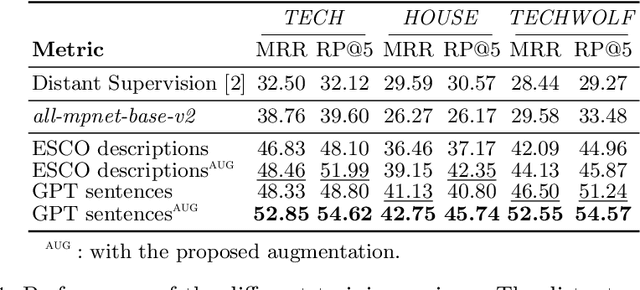
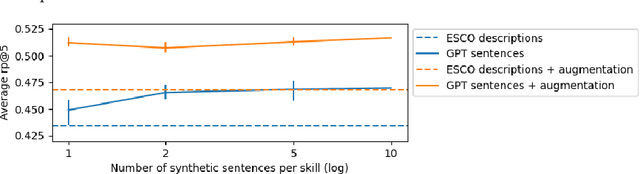
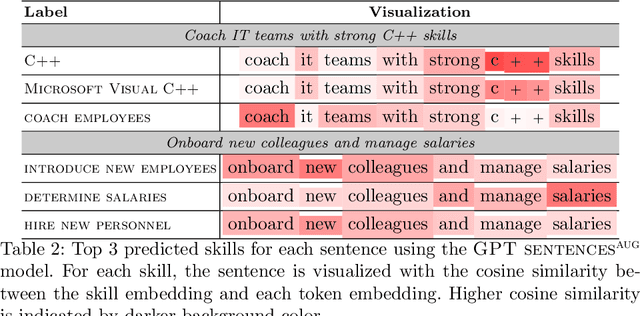
Online job ads serve as a valuable source of information for skill requirements, playing a crucial role in labor market analysis and e-recruitment processes. Since such ads are typically formatted in free text, natural language processing (NLP) technologies are required to automatically process them. We specifically focus on the task of detecting skills (mentioned literally, or implicitly described) and linking them to a large skill ontology, making it a challenging case of extreme multi-label classification (XMLC). Given that there is no sizable labeled (training) dataset are available for this specific XMLC task, we propose techniques to leverage general Large Language Models (LLMs). We describe a cost-effective approach to generate an accurate, fully synthetic labeled dataset for skill extraction, and present a contrastive learning strategy that proves effective in the task. Our results across three skill extraction benchmarks show a consistent increase of between 15 to 25 percentage points in \textit{R-Precision@5} compared to previously published results that relied solely on distant supervision through literal matches.
Is it Required? Ranking the Skills Required for a Job-Title
Nov 28, 2022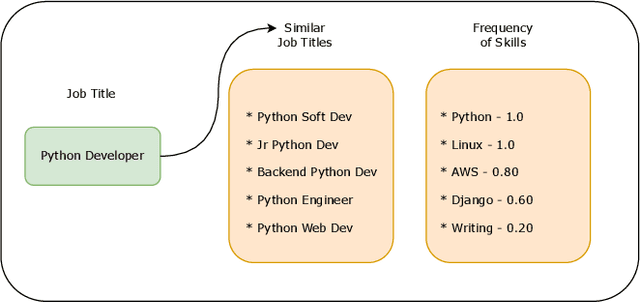
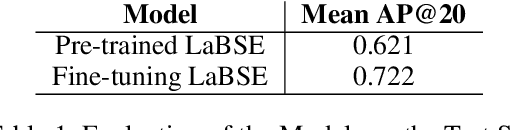
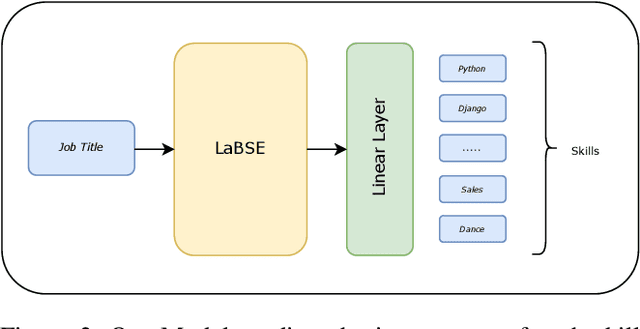
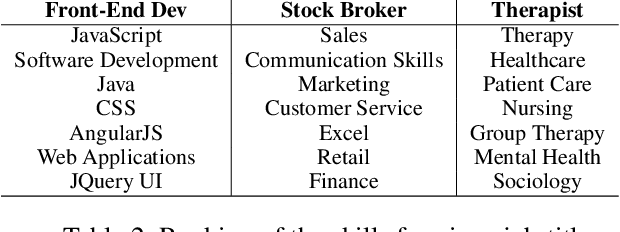
In this paper, we describe our method for ranking the skills required for a given job title. Our analysis shows that important/relevant skills appear more frequently in similar job titles. We train a Language-agnostic BERT Sentence Encoder (LaBSE) model to predict the importance of the skills using weak supervision. We show the model can learn the importance of skills and perform well in other languages. Furthermore, we show how the Inverse Document Frequency factor of skill boosts the specialised skills.
Design of Negative Sampling Strategies for Distantly Supervised Skill Extraction
Sep 13, 2022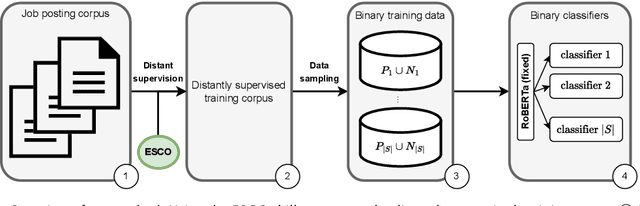
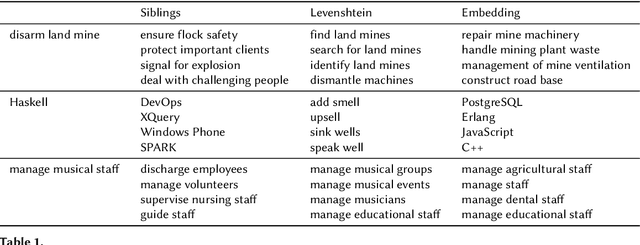

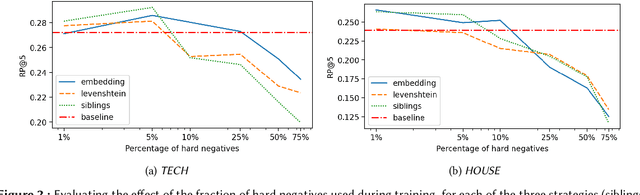
Skills play a central role in the job market and many human resources (HR) processes. In the wake of other digital experiences, today's online job market has candidates expecting to see the right opportunities based on their skill set. Similarly, enterprises increasingly need to use data to guarantee that the skills within their workforce remain future-proof. However, structured information about skills is often missing, and processes building on self- or manager-assessment have shown to struggle with issues around adoption, completeness, and freshness of the resulting data. Extracting skills is a highly challenging task, given the many thousands of possible skill labels mentioned either explicitly or merely described implicitly and the lack of finely annotated training corpora. Previous work on skill extraction overly simplifies the task to an explicit entity detection task or builds on manually annotated training data that would be infeasible if applied to a complete vocabulary of skills. We propose an end-to-end system for skill extraction, based on distant supervision through literal matching. We propose and evaluate several negative sampling strategies, tuned on a small validation dataset, to improve the generalization of skill extraction towards implicitly mentioned skills, despite the lack of such implicit skills in the distantly supervised data. We observe that using the ESCO taxonomy to select negative examples from related skills yields the biggest improvements, and combining three different strategies in one model further increases the performance, up to 8 percentage points in RP@5. We introduce a manually annotated evaluation benchmark for skill extraction based on the ESCO taxonomy, on which we validate our models. We release the benchmark dataset for research purposes to stimulate further research on the task.
JobBERT: Understanding Job Titles through Skills
Sep 20, 2021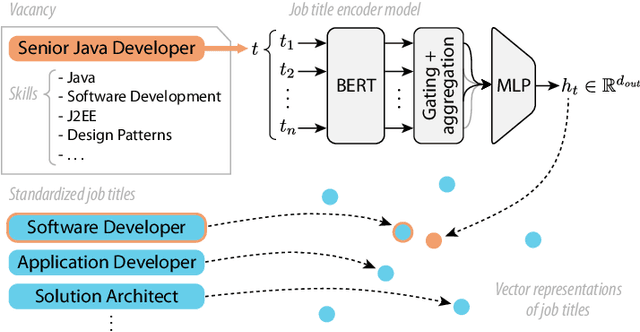
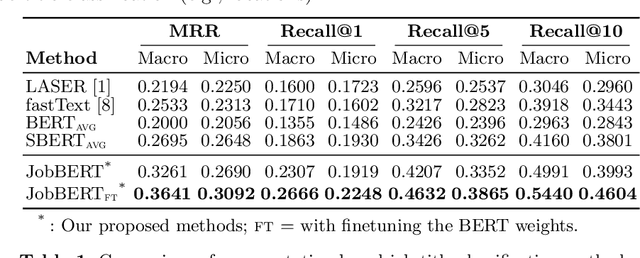
Job titles form a cornerstone of today's human resources (HR) processes. Within online recruitment, they allow candidates to understand the contents of a vacancy at a glance, while internal HR departments use them to organize and structure many of their processes. As job titles are a compact, convenient, and readily available data source, modeling them with high accuracy can greatly benefit many HR tech applications. In this paper, we propose a neural representation model for job titles, by augmenting a pre-trained language model with co-occurrence information from skill labels extracted from vacancies. Our JobBERT method leads to considerable improvements compared to using generic sentence encoders, for the task of job title normalization, for which we release a new evaluation benchmark.