 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Negative Guidance of Diffusion Models
Oct 18, 2024



Negative Prompting (NP) is widely utilized in diffusion models, particularly in text-to-image applications, to prevent the generation of undesired features. In this paper, we show that conventional NP is limited by the assumption of a constant guidance scale, which may lead to highly suboptimal results, or even complete failure, due to the non-stationarity and state-dependence of the reverse process. Based on this analysis, we derive a principled technique called Dynamic Negative Guidance, which relies on a near-optimal time and state dependent modulation of the guidance without requiring additional training. Unlike NP, negative guidance requires estimating the posterior class probability during the denoising process, which is achieved with limited additional computational overhead by tracking the discrete Markov Chain during the generative process. We evaluate the performance of DNG class-removal on MNIST and CIFAR10, where we show that DNG leads to higher safety, preservation of class balance and image quality when compared with baseline methods. Furthermore, we show that it is possible to use DNG with Stable Diffusion to obtain more accurate and less invasive guidance than NP.
Clinical Reasoning over Tabular Data and Text with Bayesian Networks
Mar 19, 2024


Bayesian networks are well-suited for clinical reasoning on tabular data, but are less compatible with natural language data, for which neural networks provide a successful framework. This paper compares and discusses strategies to augment Bayesian networks with neural text representations, both in a generative and discriminative manner. This is illustrated with simulation results for a primary care use case (diagnosis of pneumonia) and discussed in a broader clinical context.
Exploring the Temperature-Dependent Phase Transition in Modern Hopfield Networks
Nov 30, 2023


The recent discovery of a connection between Transformers and Modern Hopfield Networks (MHNs) has reignited the study of neural networks from a physical energy-based perspective. This paper focuses on the pivotal effect of the inverse temperature hyperparameter $\beta$ on the distribution of energy minima of the MHN. To achieve this, the distribution of energy minima is tracked in a simplified MHN in which equidistant normalised patterns are stored. This network demonstrates a phase transition at a critical temperature $\beta_{\text{c}}$, from a single global attractor towards highly pattern specific minima as $\beta$ is increased. Importantly, the dynamics are not solely governed by the hyperparameter $\beta$ but are instead determined by an effective inverse temperature $\beta_{\text{eff}}$ which also depends on the distribution and size of the stored patterns. Recognizing the role of hyperparameters in the MHN could, in the future, aid researchers in the domain of Transformers to optimise their initial choices, potentially reducing the necessity for time and energy expensive hyperparameter fine-tuning.
Accelerating Hierarchical Associative Memory: A Deep Equilibrium Approach
Nov 27, 2023
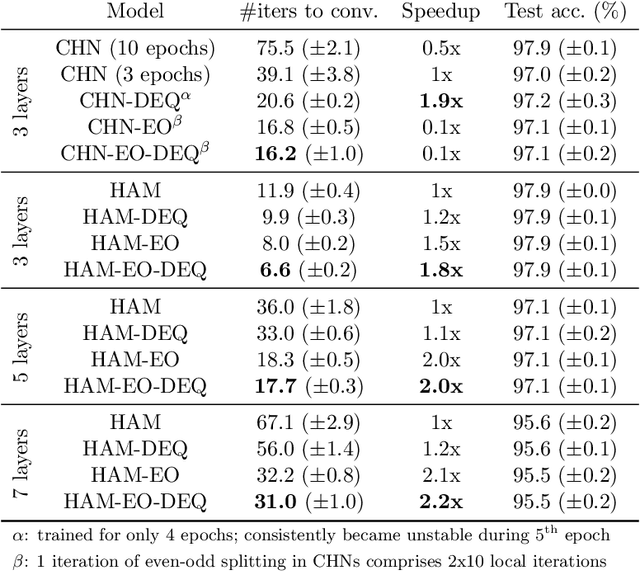
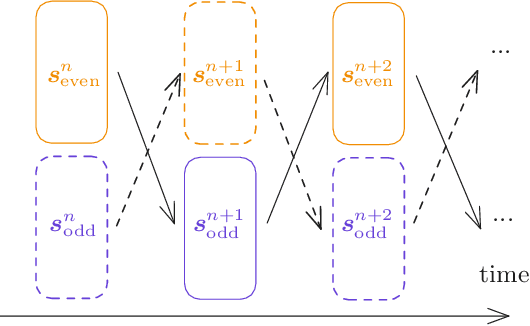
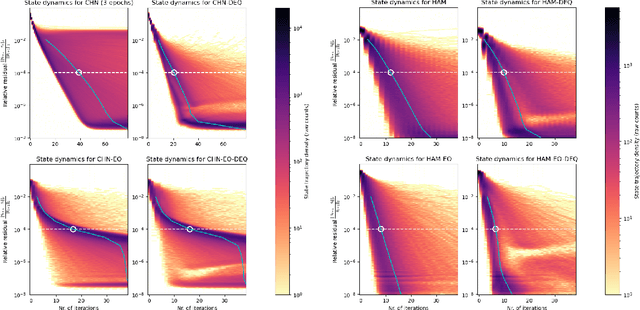
Hierarchical Associative Memory models have recently been proposed as a versatile extension of continuous Hopfield networks. In order to facilitate future research on such models, especially at scale, we focus on increasing their simulation efficiency on digital hardware. In particular, we propose two strategies to speed up memory retrieval in these models, which corresponds to their use at inference, but is equally important during training. First, we show how they can be cast as Deep Equilibrium Models, which allows using faster and more stable solvers. Second, inspired by earlier work, we show that alternating optimization of the even and odd layers accelerates memory retrieval by a factor close to two. Combined, these two techniques allow for a much faster energy minimization, as shown in our proof-of-concept experimental results. The code is available at https://github.com/cgoemaere/hamdeq
Training a Hopfield Variational Autoencoder with Equilibrium Propagation
Nov 25, 2023On dedicated analog hardware, equilibrium propagation is an energy-efficient alternative to backpropagation. In spite of its theoretical guarantees, its application in the AI domain remains limited to the discriminative setting. Meanwhile, despite its high computational demands, generative AI is on the rise. In this paper, we demonstrate the application of Equilibrium Propagation in training a variational autoencoder (VAE) for generative modeling. Leveraging the symmetric nature of Hopfield networks, we propose using a single model to serve as both the encoder and decoder which could effectively halve the required chip size for VAE implementations, paving the way for more efficient analog hardware configurations.
Career Path Prediction using Resume Representation Learning and Skill-based Matching
Oct 24, 2023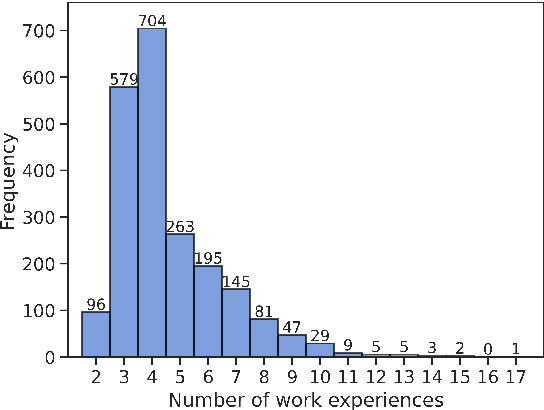
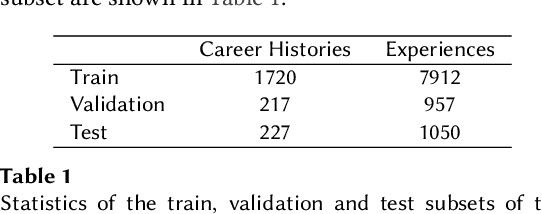


The impact of person-job fit on job satisfaction and performance is widely acknowledged, which highlights the importance of providing workers with next steps at the right time in their career. This task of predicting the next step in a career is known as career path prediction, and has diverse applications such as turnover prevention and internal job mobility. Existing methods to career path prediction rely on large amounts of private career history data to model the interactions between job titles and companies. We propose leveraging the unexplored textual descriptions that are part of work experience sections in resumes. We introduce a structured dataset of 2,164 anonymized career histories, annotated with ESCO occupation labels. Based on this dataset, we present a novel representation learning approach, CareerBERT, specifically designed for work history data. We develop a skill-based model and a text-based model for career path prediction, which achieve 35.24% and 39.61% recall@10 respectively on our dataset. Finally, we show that both approaches are complementary as a hybrid approach achieves the strongest result with 43.01% recall@10.
Distractor generation for multiple-choice questions with predictive prompting and large language models
Jul 30, 2023


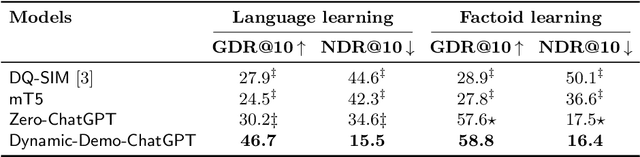
Large Language Models (LLMs) such as ChatGPT have demonstrated remarkable performance across various tasks and have garnered significant attention from both researchers and practitioners. However, in an educational context, we still observe a performance gap in generating distractors -- i.e., plausible yet incorrect answers -- with LLMs for multiple-choice questions (MCQs). In this study, we propose a strategy for guiding LLMs such as ChatGPT, in generating relevant distractors by prompting them with question items automatically retrieved from a question bank as well-chosen in-context examples. We evaluate our LLM-based solutions using a quantitative assessment on an existing test set, as well as through quality annotations by human experts, i.e., teachers. We found that on average 53% of the generated distractors presented to the teachers were rated as high-quality, i.e., suitable for immediate use as is, outperforming the state-of-the-art model. We also show the gains of our approach 1 in generating high-quality distractors by comparing it with a zero-shot ChatGPT and a few-shot ChatGPT prompted with static examples.
Extreme Multi-Label Skill Extraction Training using Large Language Models
Jul 20, 2023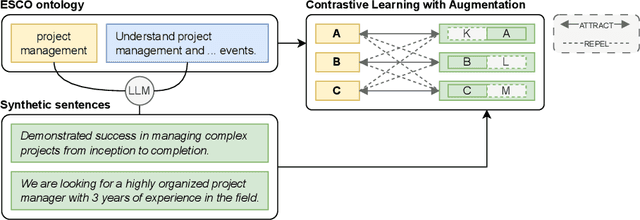
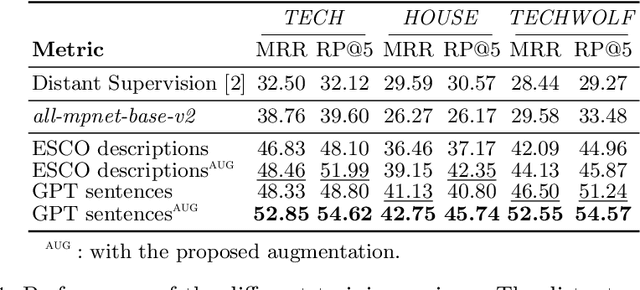
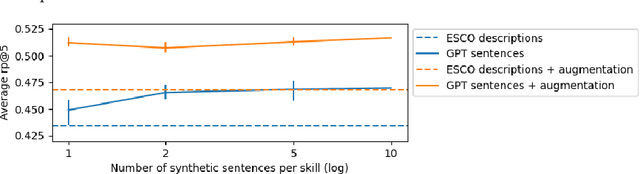
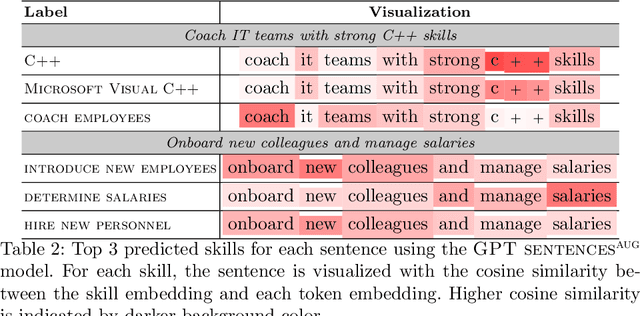
Online job ads serve as a valuable source of information for skill requirements, playing a crucial role in labor market analysis and e-recruitment processes. Since such ads are typically formatted in free text, natural language processing (NLP) technologies are required to automatically process them. We specifically focus on the task of detecting skills (mentioned literally, or implicitly described) and linking them to a large skill ontology, making it a challenging case of extreme multi-label classification (XMLC). Given that there is no sizable labeled (training) dataset are available for this specific XMLC task, we propose techniques to leverage general Large Language Models (LLMs). We describe a cost-effective approach to generate an accurate, fully synthetic labeled dataset for skill extraction, and present a contrastive learning strategy that proves effective in the task. Our results across three skill extraction benchmarks show a consistent increase of between 15 to 25 percentage points in \textit{R-Precision@5} compared to previously published results that relied solely on distant supervision through literal matches.
Learning from Partially Annotated Data: Example-aware Creation of Gap-filling Exercises for Language Learning
Jun 15, 2023



Since performing exercises (including, e.g., practice tests) forms a crucial component of learning, and creating such exercises requires non-trivial effort from the teacher, there is a great value in automatic exercise generation in digital tools in education. In this paper, we particularly focus on automatic creation of gapfilling exercises for language learning, specifically grammar exercises. Since providing any annotation in this domain requires human expert effort, we aim to avoid it entirely and explore the task of converting existing texts into new gap-filling exercises, purely based on an example exercise, without explicit instruction or detailed annotation of the intended grammar topics. We contribute (i) a novel neural network architecture specifically designed for aforementioned gap-filling exercise generation task, and (ii) a real-world benchmark dataset for French grammar. We show that our model for this French grammar gap-filling exercise generation outperforms a competitive baseline classifier by 8% in F1 percentage points, achieving an average F1 score of 82%. Our model implementation and the dataset are made publicly available to foster future research, thus offering a standardized evaluation and baseline solution of the proposed partially annotated data prediction task in grammar exercise creation.
BioDEX: Large-Scale Biomedical Adverse Drug Event Extraction for Real-World Pharmacovigilance
May 22, 2023



Timely and accurate extraction of Adverse Drug Events (ADE) from biomedical literature is paramount for public safety, but involves slow and costly manual labor. We set out to improve drug safety monitoring (pharmacovigilance, PV) through the use of Natural Language Processing (NLP). We introduce BioDEX, a large-scale resource for Biomedical adverse Drug Event Extraction, rooted in the historical output of drug safety reporting in the U.S. BioDEX consists of 65k abstracts and 19k full-text biomedical papers with 256k associated document-level safety reports created by medical experts. The core features of these reports include the reported weight, age, and biological sex of a patient, a set of drugs taken by the patient, the drug dosages, the reactions experienced, and whether the reaction was life threatening. In this work, we consider the task of predicting the core information of the report given its originating paper. We estimate human performance to be 72.0% F1, whereas our best model achieves 62.3% F1, indicating significant headroom on this task. We also begin to explore ways in which these models could help professional PV reviewers. Our code and data are available: https://github.com/KarelDO/BioDEX.