 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Differentiable Auditory Loop (DAL): An ML Framework for Hyper-Personalized Hearing Aids
Jun 02, 2026Conventional hearing aids rely on fixed, frequency-dependent amplification and compression to manage reduced sensitivity, which often fails to provide sufficient listening support in complex environments, such as situations with multiple speakers (the ``cocktail party'' problem). To more comprehensively address the underlying encoding dysfunctions of hearing loss, we introduce the Differentiable Auditory Loop (DAL), a new open-source framework for personalized hearing aid design and fitting. Our first implementation of DAL incorporates CARFAC, a differentiable model of human cochlear function, which we ported to JAX, to optimize a deep neural network to match impaired auditory neural activity patterns with a normal-hearing reference. To build a hearing aid with the fine-grained spectro-temporal signal processing required, we adopt SEANet, a waveform-to-waveform fully convolutional UNet generator. We fine-tune the network by comparing the outputs of a CARFAC model fitted to normal hearing with that of a CARFAC model fitted to match each subject's individual hearing impairment. The comparison is done using loss functions derived from the respective CARFAC neural activity pattern (NAP) outputs and stabilized auditory images (SAIs), the latter providing a 2D representation that captures phase-insensitive temporal structure in the auditory nerve output. Through gradient descent, the SEANet model learns to both denoise the input and compensate for the hearing loss modelled by the impaired CARFAC model. Across neural-representation and signal-fidelity metrics, the DAL-optimized SEANet model outperformed the tested master hearing aid (MHA) baselines. The DAL framework provides a practical path toward model-based, machine-learning-driven personalization of hearing aid signal processing. Next steps include hardware deployment to enable real-world clinical testing.
Identifying Hearing Difficulty Moments in Conversational Audio
Jul 31, 2025Individuals regularly experience Hearing Difficulty Moments in everyday conversation. Identifying these moments of hearing difficulty has particular significance in the field of hearing assistive technology where timely interventions are key for realtime hearing assistance. In this paper, we propose and compare machine learning solutions for continuously detecting utterances that identify these specific moments in conversational audio. We show that audio language models, through their multimodal reasoning capabilities, excel at this task, significantly outperforming a simple ASR hotword heuristic and a more conventional fine-tuning approach with Wav2Vec, an audio-only input architecture that is state-of-the-art for automatic speech recognition (ASR).
Nosey: Open-source hardware for acoustic nasalance
May 29, 2025We introduce Nosey (Nasalance Open Source Estimation sYstem), a low-cost, customizable, 3D-printed system for recording acoustic nasalance data that we have made available as open-source hardware (http://github.com/phoneticslab/nosey). We first outline the motivations and design principles behind our hardware nasalance system, and then present a comparison between Nosey and a commercial nasalance device. Nosey shows consistently higher nasalance scores than the commercial device, but the magnitude of contrast between phonological environments is comparable between systems. We also review ways of customizing the hardware to facilitate testing, such as comparison of microphones and different construction materials. We conclude that Nosey is a flexible and cost-effective alternative to commercial nasometry devices and propose some methodological considerations for its use in data collection.
COMBO-Grasp: Learning Constraint-Based Manipulation for Bimanual Occluded Grasping
Feb 12, 2025

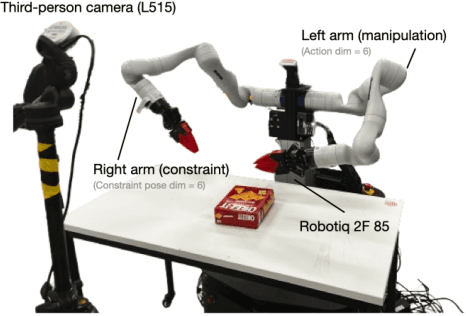
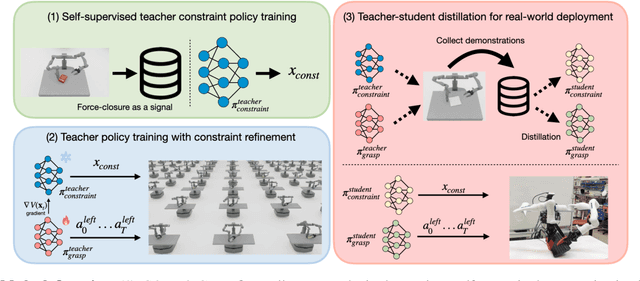
This paper addresses the challenge of occluded robot grasping, i.e. grasping in situations where the desired grasp poses are kinematically infeasible due to environmental constraints such as surface collisions. Traditional robot manipulation approaches struggle with the complexity of non-prehensile or bimanual strategies commonly used by humans in these circumstances. State-of-the-art reinforcement learning (RL) methods are unsuitable due to the inherent complexity of the task. In contrast, learning from demonstration requires collecting a significant number of expert demonstrations, which is often infeasible. Instead, inspired by human bimanual manipulation strategies, where two hands coordinate to stabilise and reorient objects, we focus on a bimanual robotic setup to tackle this challenge. In particular, we introduce Constraint-based Manipulation for Bimanual Occluded Grasping (COMBO-Grasp), a learning-based approach which leverages two coordinated policies: a constraint policy trained using self-supervised datasets to generate stabilising poses and a grasping policy trained using RL that reorients and grasps the target object. A key contribution lies in value function-guided policy coordination. Specifically, during RL training for the grasping policy, the constraint policy's output is refined through gradients from a jointly trained value function, improving bimanual coordination and task performance. Lastly, COMBO-Grasp employs teacher-student policy distillation to effectively deploy point cloud-based policies in real-world environments. Empirical evaluations demonstrate that COMBO-Grasp significantly improves task success rates compared to competitive baseline approaches, with successful generalisation to unseen objects in both simulated and real-world environments.
Learning the Bitter Lesson: Empirical Evidence from 20 Years of CVPR Proceedings
Oct 12, 2024



This study examines the alignment of \emph{Conference on Computer Vision and Pattern Recognition} (CVPR) research with the principles of the "bitter lesson" proposed by Rich Sutton. We analyze two decades of CVPR abstracts and titles using large language models (LLMs) to assess the field's embracement of these principles. Our methodology leverages state-of-the-art natural language processing techniques to systematically evaluate the evolution of research approaches in computer vision. The results reveal significant trends in the adoption of general-purpose learning algorithms and the utilization of increased computational resources. We discuss the implications of these findings for the future direction of computer vision research and its potential impact on broader artificial intelligence development. This work contributes to the ongoing dialogue about the most effective strategies for advancing machine learning and computer vision, offering insights that may guide future research priorities and methodologies in the field.
A Review of Differentiable Simulators
Jul 08, 2024



Differentiable simulators continue to push the state of the art across a range of domains including computational physics, robotics, and machine learning. Their main value is the ability to compute gradients of physical processes, which allows differentiable simulators to be readily integrated into commonly employed gradient-based optimization schemes. To achieve this, a number of design decisions need to be considered representing trade-offs in versatility, computational speed, and accuracy of the gradients obtained. This paper presents an in-depth review of the evolving landscape of differentiable physics simulators. We introduce the foundations and core components of differentiable simulators alongside common design choices. This is followed by a practical guide and overview of open-source differentiable simulators that have been used across past research. Finally, we review and contextualize prominent applications of differentiable simulation. By offering a comprehensive review of the current state-of-the-art in differentiable simulation, this work aims to serve as a resource for researchers and practitioners looking to understand and integrate differentiable physics within their research. We conclude by highlighting current limitations as well as providing insights into future directions for the field.
D-Cubed: Latent Diffusion Trajectory Optimisation for Dexterous Deformable Manipulation
Mar 19, 2024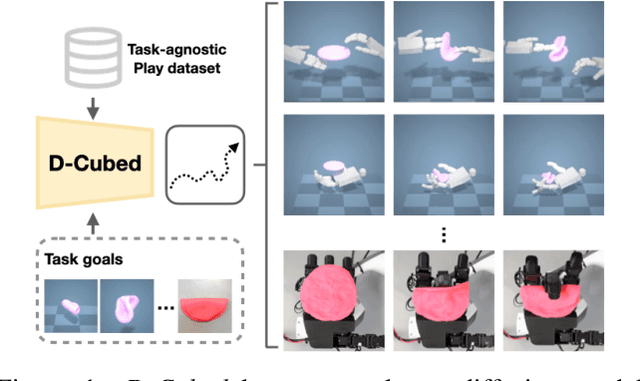

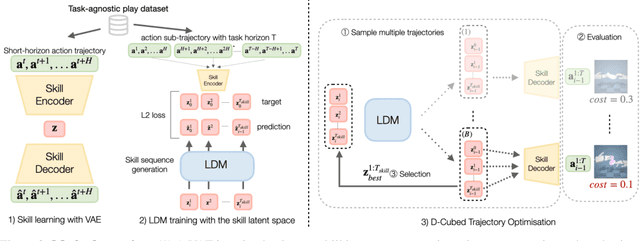
Mastering dexterous robotic manipulation of deformable objects is vital for overcoming the limitations of parallel grippers in real-world applications. Current trajectory optimisation approaches often struggle to solve such tasks due to the large search space and the limited task information available from a cost function. In this work, we propose D-Cubed, a novel trajectory optimisation method using a latent diffusion model (LDM) trained from a task-agnostic play dataset to solve dexterous deformable object manipulation tasks. D-Cubed learns a skill-latent space that encodes short-horizon actions in the play dataset using a VAE and trains a LDM to compose the skill latents into a skill trajectory, representing a long-horizon action trajectory in the dataset. To optimise a trajectory for a target task, we introduce a novel gradient-free guided sampling method that employs the Cross-Entropy method within the reverse diffusion process. In particular, D-Cubed samples a small number of noisy skill trajectories using the LDM for exploration and evaluates the trajectories in simulation. Then, D-Cubed selects the trajectory with the lowest cost for the subsequent reverse process. This effectively explores promising solution areas and optimises the sampled trajectories towards a target task throughout the reverse diffusion process. Through empirical evaluation on a public benchmark of dexterous deformable object manipulation tasks, we demonstrate that D-Cubed outperforms traditional trajectory optimisation and competitive baseline approaches by a significant margin. We further demonstrate that trajectories found by D-Cubed readily transfer to a real-world LEAP hand on a folding task.
DreamUp3D: Object-Centric Generative Models for Single-View 3D Scene Understanding and Real-to-Sim Transfer
Feb 26, 2024
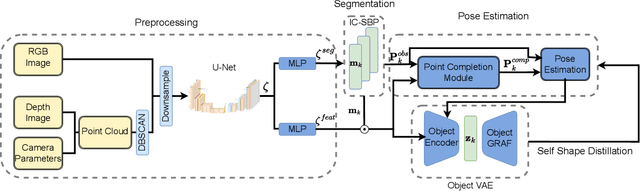

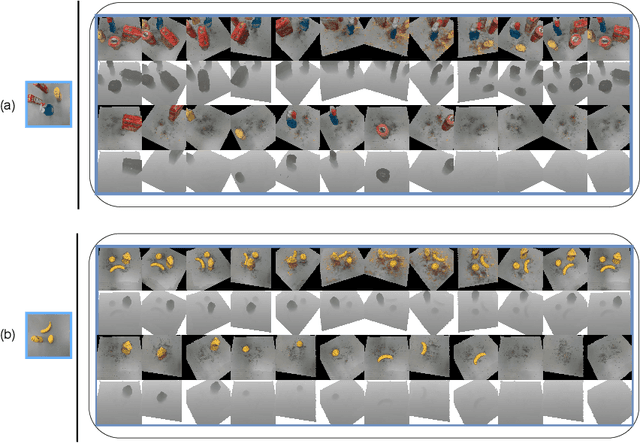
3D scene understanding for robotic applications exhibits a unique set of requirements including real-time inference, object-centric latent representation learning, accurate 6D pose estimation and 3D reconstruction of objects. Current methods for scene understanding typically rely on a combination of trained models paired with either an explicit or learnt volumetric representation, all of which have their own drawbacks and limitations. We introduce DreamUp3D, a novel Object-Centric Generative Model (OCGM) designed explicitly to perform inference on a 3D scene informed only by a single RGB-D image. DreamUp3D is a self-supervised model, trained end-to-end, and is capable of segmenting objects, providing 3D object reconstructions, generating object-centric latent representations and accurate per-object 6D pose estimates. We compare DreamUp3D to baselines including NeRFs, pre-trained CLIP-features, ObSurf, and ObPose, in a range of tasks including 3D scene reconstruction, object matching and object pose estimation. Our experiments show that our model outperforms all baselines by a significant margin in real-world scenarios displaying its applicability for 3D scene understanding tasks while meeting the strict demands exhibited in robotics applications.
TWIST: Teacher-Student World Model Distillation for Efficient Sim-to-Real Transfer
Nov 07, 2023Model-based RL is a promising approach for real-world robotics due to its improved sample efficiency and generalization capabilities compared to model-free RL. However, effective model-based RL solutions for vision-based real-world applications require bridging the sim-to-real gap for any world model learnt. Due to its significant computational cost, standard domain randomisation does not provide an effective solution to this problem. This paper proposes TWIST (Teacher-Student World Model Distillation for Sim-to-Real Transfer) to achieve efficient sim-to-real transfer of vision-based model-based RL using distillation. Specifically, TWIST leverages state observations as readily accessible, privileged information commonly garnered from a simulator to significantly accelerate sim-to-real transfer. Specifically, a teacher world model is trained efficiently on state information. At the same time, a matching dataset is collected of domain-randomised image observations. The teacher world model then supervises a student world model that takes the domain-randomised image observations as input. By distilling the learned latent dynamics model from the teacher to the student model, TWIST achieves efficient and effective sim-to-real transfer for vision-based model-based RL tasks. Experiments in simulated and real robotics tasks demonstrate that our approach outperforms naive domain randomisation and model-free methods in terms of sample efficiency and task performance of sim-to-real transfer.
BioDEX: Large-Scale Biomedical Adverse Drug Event Extraction for Real-World Pharmacovigilance
May 22, 2023



Timely and accurate extraction of Adverse Drug Events (ADE) from biomedical literature is paramount for public safety, but involves slow and costly manual labor. We set out to improve drug safety monitoring (pharmacovigilance, PV) through the use of Natural Language Processing (NLP). We introduce BioDEX, a large-scale resource for Biomedical adverse Drug Event Extraction, rooted in the historical output of drug safety reporting in the U.S. BioDEX consists of 65k abstracts and 19k full-text biomedical papers with 256k associated document-level safety reports created by medical experts. The core features of these reports include the reported weight, age, and biological sex of a patient, a set of drugs taken by the patient, the drug dosages, the reactions experienced, and whether the reaction was life threatening. In this work, we consider the task of predicting the core information of the report given its originating paper. We estimate human performance to be 72.0% F1, whereas our best model achieves 62.3% F1, indicating significant headroom on this task. We also begin to explore ways in which these models could help professional PV reviewers. Our code and data are available: https://github.com/KarelDO/BioDEX.