 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamUp3D: Object-Centric Generative Models for Single-View 3D Scene Understanding and Real-to-Sim Transfer
Paper and Code
Feb 26, 2024
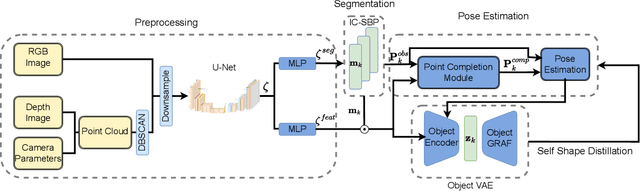

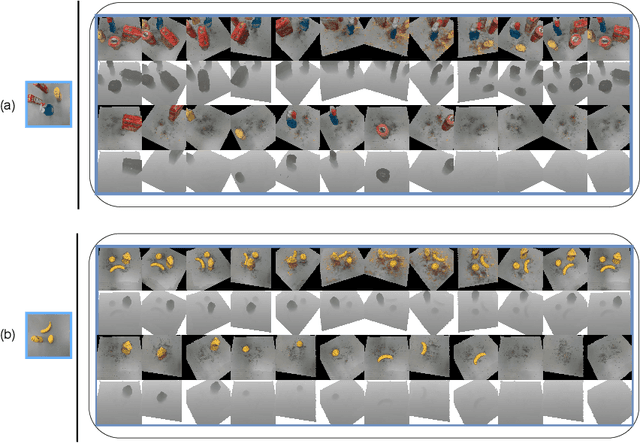
3D scene understanding for robotic applications exhibits a unique set of requirements including real-time inference, object-centric latent representation learning, accurate 6D pose estimation and 3D reconstruction of objects. Current methods for scene understanding typically rely on a combination of trained models paired with either an explicit or learnt volumetric representation, all of which have their own drawbacks and limitations. We introduce DreamUp3D, a novel Object-Centric Generative Model (OCGM) designed explicitly to perform inference on a 3D scene informed only by a single RGB-D image. DreamUp3D is a self-supervised model, trained end-to-end, and is capable of segmenting objects, providing 3D object reconstructions, generating object-centric latent representations and accurate per-object 6D pose estimates. We compare DreamUp3D to baselines including NeRFs, pre-trained CLIP-features, ObSurf, and ObPose, in a range of tasks including 3D scene reconstruction, object matching and object pose estimation. Our experiments show that our model outperforms all baselines by a significant margin in real-world scenarios displaying its applicability for 3D scene understanding tasks while meeting the strict demands exhibited in robotics applications.