 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgek-Maximum Inner Product Attention for Graph Transformers and the Expressive Power of GraphGPS The Expressive Power of GraphGPS
Apr 04, 2026Graph transformers have shown promise in overcoming limitations of traditional graph neural networks, such as oversquashing and difficulties in modelling long-range dependencies. However, their application to large-scale graphs is hindered by the quadratic memory and computational complexity of the all-to-all attention mechanism. Although alternatives such as linearized attention and restricted attention patterns have been proposed, these often degrade performance or limit expressive power. To better balance efficiency and effectiveness, we introduce k-Maximum Inner Product (k-MIP) attention for graph transformers. k-MIP attention selects the most relevant key nodes per query via a top-k operation, yielding a sparse yet flexible attention pattern. Combined with an attention score computation based on symbolic matrices, this results in linear memory complexity and practical speedups of up to an order of magnitude compared to all-to-all attention, enabling the processing of graphs with over 500k nodes on a single A100 GPU. We provide a theoretical analysis of expressive power, showing that k-MIP attention does not compromise the expressiveness of graph transformers: specifically, we prove that k-MIP transformers can approximate any full-attention transformer to arbitrary precision. In addition, we analyze the expressive power of the GraphGPS framework, in which we integrate our attention mechanism, and establish an upper bound on its graph distinguishing capability in terms of the S-SEG-WL test. Finally, we validate our approach on the Long Range Graph Benchmark, the City-Networks benchmark, and two custom large-scale inductive point cloud datasets, consistently ranking among the top-performing scalable graph transformers.
Bridging Graph and State-Space Modeling for Intensive Care Unit Length of Stay Prediction
Aug 24, 2025Predicting a patient's length of stay (LOS) in the intensive care unit (ICU) is a critical task for hospital resource management, yet remains challenging due to the heterogeneous and irregularly sampled nature of electronic health records (EHRs). In this work, we propose S$^2$G-Net, a novel neural architecture that unifies state-space sequence modeling with multi-view Graph Neural Networks (GNNs) for ICU LOS prediction. The temporal path employs Mamba state-space models (SSMs) to capture patient trajectories, while the graph path leverages an optimized GraphGPS backbone, designed to integrate heterogeneous patient similarity graphs derived from diagnostic, administrative, and semantic features. Experiments on the large-scale MIMIC-IV cohort dataset show that S$^2$G-Net consistently outperforms sequence models (BiLSTM, Mamba, Transformer), graph models (classic GNNs, GraphGPS), and hybrid approaches across all primary metrics. Extensive ablation studies and interpretability analyses highlight the complementary contributions of each component of our architecture and underscore the importance of principled graph construction. These results demonstrate that S$^2$G-Net provides an effective and scalable solution for ICU LOS prediction with multi-modal clinical data.
LoRA Fine-Tuning Without GPUs: A CPU-Efficient Meta-Generation Framework for LLMs
Jul 02, 2025Low-Rank Adapters (LoRAs) have transformed the fine-tuning of Large Language Models (LLMs) by enabling parameter-efficient updates. However, their widespread adoption remains limited by the reliance on GPU-based training. In this work, we propose a theoretically grounded approach to LoRA fine-tuning designed specifically for users with limited computational resources, particularly those restricted to standard laptop CPUs. Our method learns a meta-operator that maps any input dataset, represented as a probability distribution, to a set of LoRA weights by leveraging a large bank of pre-trained adapters for the Mistral-7B-Instruct-v0.2 model. Instead of performing new gradient-based updates, our pipeline constructs adapters via lightweight combinations of existing LoRAs directly on CPU. While the resulting adapters do not match the performance of GPU-trained counterparts, they consistently outperform the base Mistral model on downstream tasks, offering a practical and accessible alternative to traditional GPU-based fine-tuning.
Sharp Generalization Bounds for Foundation Models with Asymmetric Randomized Low-Rank Adapters
Jun 17, 2025Low-Rank Adaptation (LoRA) has emerged as a widely adopted parameter-efficient fine-tuning (PEFT) technique for foundation models. Recent work has highlighted an inherent asymmetry in the initialization of LoRA's low-rank factors, which has been present since its inception and was presumably derived experimentally. This paper focuses on providing a comprehensive theoretical characterization of asymmetric LoRA with frozen random factors. First, while existing research provides upper-bound generalization guarantees based on averages over multiple experiments, the behaviour of a single fine-tuning run with specific random factors remains an open question. We address this by investigating the concentration of the typical LoRA generalization gap around its mean. Our main upper bound reveals a sample complexity of $\tilde{\mathcal{O}}\left(\frac{\sqrt{r}}{\sqrt{N}}\right)$ with high probability for rank $r$ LoRAs trained on $N$ samples. Additionally, we also determine the fundamental limits in terms of sample efficiency, establishing a matching lower bound of $\mathcal{O}\left(\frac{1}{\sqrt{N}}\right)$. By more closely reflecting the practical scenario of a single fine-tuning run, our findings offer crucial insights into the reliability and practicality of asymmetric LoRA.
Fine-Tuning Next-Scale Visual Autoregressive Models with Group Relative Policy Optimization
May 29, 2025



Fine-tuning pre-trained generative models with Reinforcement Learning (RL) has emerged as an effective approach for aligning outputs more closely with nuanced human preferences. In this paper, we investigate the application of Group Relative Policy Optimization (GRPO) to fine-tune next-scale visual autoregressive (VAR) models. Our empirical results demonstrate that this approach enables alignment to intricate reward signals derived from aesthetic predictors and CLIP embeddings, significantly enhancing image quality and enabling precise control over the generation style. Interestingly, by leveraging CLIP, our method can help VAR models generalize beyond their initial ImageNet distribution: through RL-driven exploration, these models can generate images aligned with prompts referencing image styles that were absent during pre-training. In summary, we show that RL-based fine-tuning is both efficient and effective for VAR models, benefiting particularly from their fast inference speeds, which are advantageous for online sampling, an aspect that poses significant challenges for diffusion-based alternatives.
Towards Quantifying Long-Range Interactions in Graph Machine Learning: a Large Graph Dataset and a Measurement
Mar 12, 2025Long-range dependencies are critical for effective graph representation learning, yet most existing datasets focus on small graphs tailored to inductive tasks, offering limited insight into long-range interactions. Current evaluations primarily compare models employing global attention (e.g., graph transformers) with those using local neighborhood aggregation (e.g., message-passing neural networks) without a direct measurement of long-range dependency. In this work, we introduce City-Networks, a novel large-scale transductive learning dataset derived from real-world city roads. This dataset features graphs with over $10^5$ nodes and significantly larger diameters than those in existing benchmarks, naturally embodying long-range information. We annotate the graphs using an eccentricity-based approach, ensuring that the classification task inherently requires information from distant nodes. Furthermore, we propose a model-agnostic measurement based on the Jacobians of neighbors from distant hops, offering a principled quantification of long-range dependencies. Finally, we provide theoretical justifications for both our dataset design and the proposed measurement - particularly by focusing on over-smoothing and influence score dilution - which establishes a robust foundation for further exploration of long-range interactions in graph neural networks.
Keep It Light! Simplifying Image Clustering Via Text-Free Adapters
Feb 06, 2025Many competitive clustering pipelines have a multi-modal design, leveraging large language models (LLMs) or other text encoders, and text-image pairs, which are often unavailable in real-world downstream applications. Additionally, such frameworks are generally complicated to train and require substantial computational resources, making widespread adoption challenging. In this work, we show that in deep clustering, competitive performance with more complex state-of-the-art methods can be achieved using a text-free and highly simplified training pipeline. In particular, our approach, Simple Clustering via Pre-trained models (SCP), trains only a small cluster head while leveraging pre-trained vision model feature representations and positive data pairs. Experiments on benchmark datasets including CIFAR-10, CIFAR-20, CIFAR-100, STL-10, ImageNet-10, and ImageNet-Dogs, demonstrate that SCP achieves highly competitive performance. Furthermore, we provide a theoretical result explaining why, at least under ideal conditions, additional text-based embeddings may not be necessary to achieve strong clustering performance in vision.
Scalable Message Passing Neural Networks: No Need for Attention in Large Graph Representation Learning
Oct 29, 2024We propose Scalable Message Passing Neural Networks (SMPNNs) and demonstrate that, by integrating standard convolutional message passing into a Pre-Layer Normalization Transformer-style block instead of attention, we can produce high-performing deep message-passing-based Graph Neural Networks (GNNs). This modification yields results competitive with the state-of-the-art in large graph transductive learning, particularly outperforming the best Graph Transformers in the literature, without requiring the otherwise computationally and memory-expensive attention mechanism. Our architecture not only scales to large graphs but also makes it possible to construct deep message-passing networks, unlike simple GNNs, which have traditionally been constrained to shallow architectures due to oversmoothing. Moreover, we provide a new theoretical analysis of oversmoothing based on universal approximation which we use to motivate SMPNNs. We show that in the context of graph convolutions, residual connections are necessary for maintaining the universal approximation properties of downstream learners and that removing them can lead to a loss of universality.
Neural Spacetimes for DAG Representation Learning
Aug 25, 2024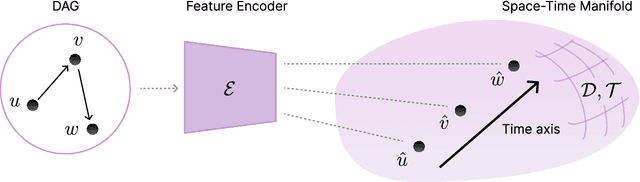
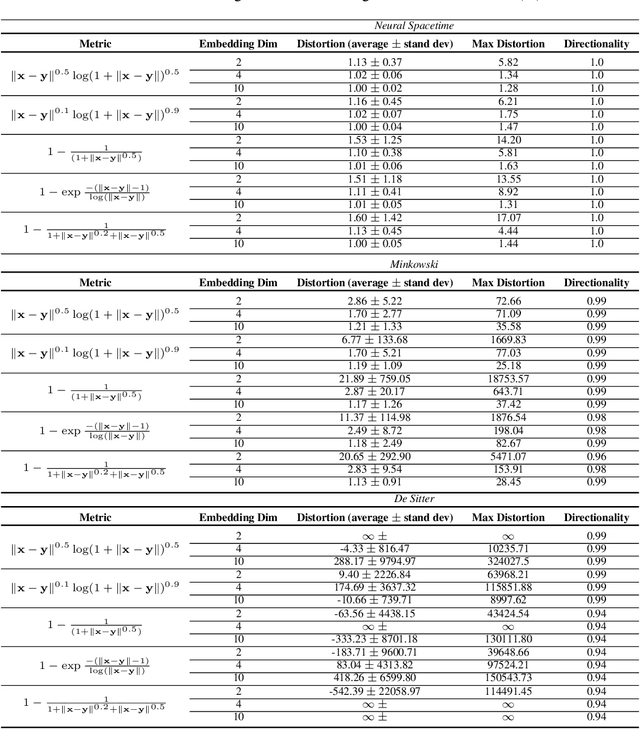
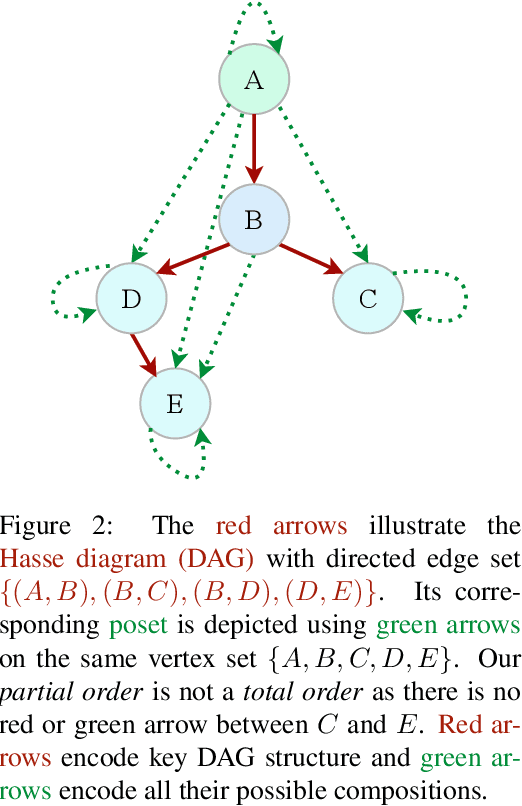
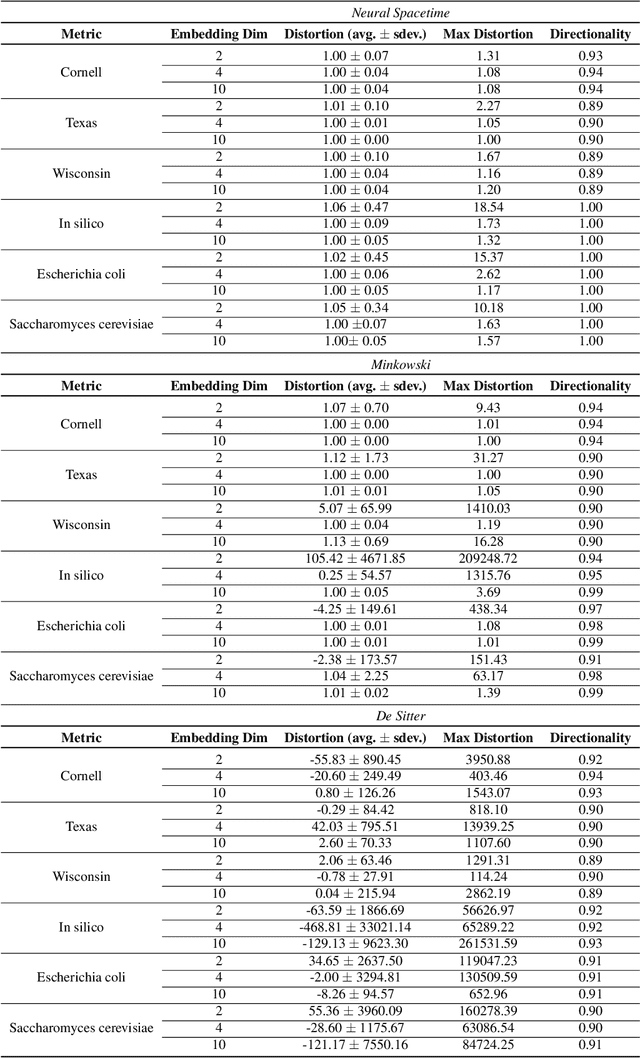
We propose a class of trainable deep learning-based geometries called Neural Spacetimes (NSTs), which can universally represent nodes in weighted directed acyclic graphs (DAGs) as events in a spacetime manifold. While most works in the literature focus on undirected graph representation learning or causality embedding separately, our differentiable geometry can encode both graph edge weights in its spatial dimensions and causality in the form of edge directionality in its temporal dimensions. We use a product manifold that combines a quasi-metric (for space) and a partial order (for time). NSTs are implemented as three neural networks trained in an end-to-end manner: an embedding network, which learns to optimize the location of nodes as events in the spacetime manifold, and two other networks that optimize the space and time geometries in parallel, which we call a neural (quasi-)metric and a neural partial order, respectively. The latter two networks leverage recent ideas at the intersection of fractal geometry and deep learning to shape the geometry of the representation space in a data-driven fashion, unlike other works in the literature that use fixed spacetime manifolds such as Minkowski space or De Sitter space to embed DAGs. Our main theoretical guarantee is a universal embedding theorem, showing that any $k$-point DAG can be embedded into an NST with $1+\mathcal{O}(\log(k))$ distortion while exactly preserving its causal structure. The total number of parameters defining the NST is sub-cubic in $k$ and linear in the width of the DAG. If the DAG has a planar Hasse diagram, this is improved to $\mathcal{O}(\log(k)) + 2)$ spatial and 2 temporal dimensions. We validate our framework computationally with synthetic weighted DAGs and real-world network embeddings; in both cases, the NSTs achieve lower embedding distortions than their counterparts using fixed spacetime geometries.
Metric Learning for Clifford Group Equivariant Neural Networks
Jul 13, 2024


Clifford Group Equivariant Neural Networks (CGENNs) leverage Clifford algebras and multivectors as an alternative approach to incorporating group equivariance to ensure symmetry constraints in neural representations. In principle, this formulation generalizes to orthogonal groups and preserves equivariance regardless of the metric signature. However, previous works have restricted internal network representations to Euclidean or Minkowski (pseudo-)metrics, handpicked depending on the problem at hand. In this work, we propose an alternative method that enables the metric to be learned in a data-driven fashion, allowing the CGENN network to learn more flexible representations. Specifically, we populate metric matrices fully, ensuring they are symmetric by construction, and leverage eigenvalue decomposition to integrate this additional learnable component into the original CGENN formulation in a principled manner. Additionally, we motivate our method using insights from category theory, which enables us to explain Clifford algebras as a categorical construction and guarantee the mathematical soundness of our approach. We validate our method in various tasks and showcase the advantages of learning more flexible latent metric representations. The code and data are available at https://github.com/rick-ali/Metric-Learning-for-CGENNs