 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizer choice matters for the emergence of Neural Collapse
Feb 18, 2026Neural Collapse (NC) refers to the emergence of highly symmetric geometric structures in the representations of deep neural networks during the terminal phase of training. Despite its prevalence, the theoretical understanding of NC remains limited. Existing analyses largely ignore the role of the optimizer, thereby suggesting that NC is universal across optimization methods. In this work, we challenge this assumption and demonstrate that the choice of optimizer plays a critical role in the emergence of NC. The phenomenon is typically quantified through NC metrics, which, however, are difficult to track and analyze theoretically. To overcome this limitation, we introduce a novel diagnostic metric, NC0, whose convergence to zero is a necessary condition for NC. Using NC0, we provide theoretical evidence that NC cannot emerge under decoupled weight decay in adaptive optimizers, as implemented in AdamW. Concretely, we prove that SGD, SignGD with coupled weight decay (a special case of Adam), and SignGD with decoupled weight decay (a special case of AdamW) exhibit qualitatively different NC0 dynamics. Also, we show the accelerating effect of momentum on NC (beyond convergence of train loss) when trained with SGD, being the first result concerning momentum in the context of NC. Finally, we conduct extensive empirical experiments consisting of 3,900 training runs across various datasets, architectures, optimizers, and hyperparameters, confirming our theoretical results. This work provides the first theoretical explanation for optimizer-dependent emergence of NC and highlights the overlooked role of weight-decay coupling in shaping the implicit biases of optimizers.
Spectral Analysis of Molecular Kernels: When Richer Features Do Not Guarantee Better Generalization
Oct 16, 2025Understanding the spectral properties of kernels offers a principled perspective on generalization and representation quality. While deep models achieve state-of-the-art accuracy in molecular property prediction, kernel methods remain widely used for their robustness in low-data regimes and transparent theoretical grounding. Despite extensive studies of kernel spectra in machine learning, systematic spectral analyses of molecular kernels are scarce. In this work, we provide the first comprehensive spectral analysis of kernel ridge regression on the QM9 dataset, molecular fingerprint, pretrained transformer-based, global and local 3D representations across seven molecular properties. Surprisingly, richer spectral features, measured by four different spectral metrics, do not consistently improve accuracy. Pearson correlation tests further reveal that for transformer-based and local 3D representations, spectral richness can even have a negative correlation with performance. We also implement truncated kernels to probe the relationship between spectrum and predictive performance: in many kernels, retaining only the top 2% of eigenvalues recovers nearly all performance, indicating that the leading eigenvalues capture the most informative features. Our results challenge the common heuristic that "richer spectra yield better generalization" and highlight nuanced relationships between representation, kernel features, and predictive performance. Beyond molecular property prediction, these findings inform how kernel and self-supervised learning methods are evaluated in data-limited scientific and real-world tasks.
Sharp Generalization Bounds for Foundation Models with Asymmetric Randomized Low-Rank Adapters
Jun 17, 2025Low-Rank Adaptation (LoRA) has emerged as a widely adopted parameter-efficient fine-tuning (PEFT) technique for foundation models. Recent work has highlighted an inherent asymmetry in the initialization of LoRA's low-rank factors, which has been present since its inception and was presumably derived experimentally. This paper focuses on providing a comprehensive theoretical characterization of asymmetric LoRA with frozen random factors. First, while existing research provides upper-bound generalization guarantees based on averages over multiple experiments, the behaviour of a single fine-tuning run with specific random factors remains an open question. We address this by investigating the concentration of the typical LoRA generalization gap around its mean. Our main upper bound reveals a sample complexity of $\tilde{\mathcal{O}}\left(\frac{\sqrt{r}}{\sqrt{N}}\right)$ with high probability for rank $r$ LoRAs trained on $N$ samples. Additionally, we also determine the fundamental limits in terms of sample efficiency, establishing a matching lower bound of $\mathcal{O}\left(\frac{1}{\sqrt{N}}\right)$. By more closely reflecting the practical scenario of a single fine-tuning run, our findings offer crucial insights into the reliability and practicality of asymmetric LoRA.
A Comprehensive Analysis on the Learning Curve in Kernel Ridge Regression
Oct 23, 2024
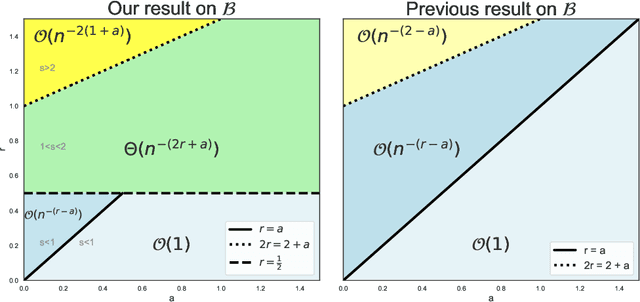
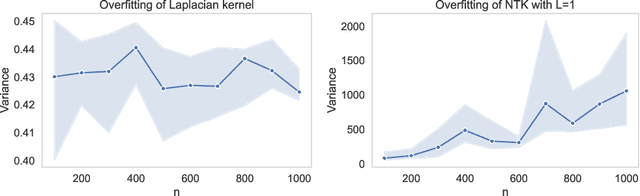

This paper conducts a comprehensive study of the learning curves of kernel ridge regression (KRR) under minimal assumptions. Our contributions are three-fold: 1) we analyze the role of key properties of the kernel, such as its spectral eigen-decay, the characteristics of the eigenfunctions, and the smoothness of the kernel; 2) we demonstrate the validity of the Gaussian Equivalent Property (GEP), which states that the generalization performance of KRR remains the same when the whitened features are replaced by standard Gaussian vectors, thereby shedding light on the success of previous analyzes under the Gaussian Design Assumption; 3) we derive novel bounds that improve over existing bounds across a broad range of setting such as (in)dependent feature vectors and various combinations of eigen-decay rates in the over/underparameterized regimes.
Characterizing Overfitting in Kernel Ridgeless Regression Through the Eigenspectrum
Feb 05, 2024



We derive new bounds for the condition number of kernel matrices, which we then use to enhance existing non-asymptotic test error bounds for kernel ridgeless regression in the over-parameterized regime for a fixed input dimension. For kernels with polynomial spectral decay, we recover the bound from previous work; for exponential decay, our bound is non-trivial and novel. Our conclusion on overfitting is two-fold: (i) kernel regressors whose eigenspectrum decays polynomially must generalize well, even in the presence of noisy labeled training data; these models exhibit so-called tempered overfitting; (ii) if the eigenspectrum of any kernel ridge regressor decays exponentially, then it generalizes poorly, i.e., it exhibits catastrophic overfitting. This adds to the available characterization of kernel ridge regressors exhibiting benign overfitting as the extremal case where the eigenspectrum of the kernel decays sub-polynomially. Our analysis combines new random matrix theory (RMT) techniques with recent tools in the kernel ridge regression (KRR) literature.
A Theoretical Analysis of the Test Error of Finite-Rank Kernel Ridge Regression
Oct 03, 2023Existing statistical learning guarantees for general kernel regressors often yield loose bounds when used with finite-rank kernels. Yet, finite-rank kernels naturally appear in several machine learning problems, e.g.\ when fine-tuning a pre-trained deep neural network's last layer to adapt it to a novel task when performing transfer learning. We address this gap for finite-rank kernel ridge regression (KRR) by deriving sharp non-asymptotic upper and lower bounds for the KRR test error of any finite-rank KRR. Our bounds are tighter than previously derived bounds on finite-rank KRR, and unlike comparable results, they also remain valid for any regularization parameters.