 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Volume Alignment by Frequency-Marched Newton
Mar 16, 2026We develop a fast and accurate method for 3D alignment, recovering the rotation and translation that best align a reference volume with a noisy observation. Classical matched filtering evaluates cross-correlation over a large discretized transformation space; we show that high-precision alignment can be achieved far more efficiently by treating pose estimation as a continuous optimization problem. Our starting point is a band-limited Wigner-$D$ expansion of the rotational correlation, which enables rapid evaluation and efficient closed-form gradients and Hessians. Combined with analytical control of the complexity of trigonometric-polynomial landscapes, this makes second-order optimization practical in a setting where it is often avoided due to nonconvexity and noise sensitivity. We show that Newton-type refinement is stable and effective when initialized at low angular bandwidth: a coarse low-resolution $\mathrm{SO}(3)$ search provides robust candidates, which are then refined by iterative frequency marching and Newton steps, with translations updated via FFT in an alternating scheme. We provide a deterministic convergence guarantee showing that, under verifiable spectral-decay and gap conditions, the frequency-marching scheme returns a near-optimal solution whose suboptimality is controlled by the Newton tolerance. On synthetic rotation-estimation benchmarks, the method attains sub-degree accuracy while substantially reducing runtime relative to exhaustive $\mathrm{SO}(3)$ search. Integrated into the subtomogram-averaging pipeline of RELION5, it matches the baseline reconstruction quality, reaching local resolution at the Nyquist limit, while reducing pose-refinement time by more than an order of magnitude.
Gaussian surrogates do well on Poisson inverse problems
Feb 19, 2026In imaging inverse problems with Poisson-distributed measurements, it is common to use objectives derived from the Poisson likelihood. But performance is often evaluated by mean squared error (MSE), which raises a practical question: how much does a Poisson objective matter for MSE, even at low dose? We analyze the MSE of Poisson and Gaussian surrogate reconstruction objectives under Poisson noise. In a stylized diagonal model, we show that the unregularized Poisson maximum-likelihood estimator can incur large MSE at low dose, while Poisson MAP mitigates this instability through regularization. We then study two Gaussian surrogate objectives: a heteroscedastic quadratic objective motivated by the normal approximation of Poisson data, and a homoscedastic quadratic objective that yields a simple linear estimator. We show that both surrogates can achieve MSE comparable to Poisson MAP in the low-dose regime, despite departing from the Poisson likelihood. Numerical computed tomography experiments indicate that these conclusions extend beyond the stylized setting of our theoretical analysis.
Rates and architectures for learning geometrically non-trivial operators
Dec 10, 2025Deep learning methods have proven capable of recovering operators between high-dimensional spaces, such as solution maps of PDEs and similar objects in mathematical physics, from very few training samples. This phenomenon of data-efficiency has been proven for certain classes of elliptic operators with simple geometry, i.e., operators that do not change the domain of the function or propagate singularities. However, scientific machine learning is commonly used for problems that do involve the propagation of singularities in a priori unknown ways, such as waves, advection, and fluid dynamics. In light of this, we expand the learning theory to include double fibration transforms--geometric integral operators that include generalized Radon and geodesic ray transforms. We prove that this class of operators does not suffer from the curse of dimensionality: the error decays superalgebraically, that is, faster than any fixed power of the reciprocal of the number of training samples. Furthermore, we investigate architectures that explicitly encode the geometry of these transforms, demonstrating that an architecture reminiscent of cross-attention based on levelset methods yields a parameterization that is universal, stable, and learns double fibration transforms from very few training examples. Our results contribute to a rapidly-growing line of theoretical work on learning operators for scientific machine learning.
End-to-end localized deep learning for Cryo-ET
Jan 25, 2025Cryo-electron tomography (cryo-ET) enables 3D visualization of cellular environments. Accurate reconstruction of high-resolution volumes is complicated by the very low signal-to-noise ratio and a restricted range of sample tilts, creating a missing wedge of Fourier information. Recent self-supervised deep learning approaches, which post-process initial reconstructions done by filtered backprojection (FBP), have significantly improved reconstruction quality, but they are computationally expensive, demand large memory, and require retraining for each new dataset. End-to-end supervised learning is an appealing alternative but is impeded by the lack of ground truth and the large memory demands of high-resolution volumetric data. Training on synthetic data often leads to overfitting and poor generalization to real data, and, to date, no general end-to-end deep learning reconstructors exist for cryo-ET. In this work, we introduce CryoLithe, a local, memory-efficient reconstruction network that directly estimates the volume from an aligned tilt-series, overcoming the suboptimal FBP. We demonstrate that leveraging transform-domain locality makes our network robust to distribution shifts, enabling effective supervised training and giving excellent results on real data -- without retraining or fine-tuning.
Neural equilibria for long-term prediction of nonlinear conservation laws
Jan 12, 2025We introduce Neural Discrete Equilibrium (NeurDE), a machine learning (ML) approach for long-term forecasting of flow phenomena that relies on a "lifting" of physical conservation laws into the framework of kinetic theory. The kinetic formulation provides an excellent structure for ML algorithms by separating nonlinear, non-local physics into a nonlinear but local relaxation to equilibrium and a linear non-local transport. This separation allows the ML to focus on the local nonlinear components while addressing the simpler linear transport with efficient classical numerical algorithms. To accomplish this, we design an operator network that maps macroscopic observables to equilibrium states in a manner that maximizes entropy, yielding expressive BGK-type collisions. By incorporating our surrogate equilibrium into the lattice Boltzmann (LB) algorithm, we achieve accurate flow forecasts for a wide range of challenging flows. We show that NeurDE enables accurate prediction of compressible flows, including supersonic flows, while tracking shocks over hundreds of time steps, using a small velocity lattice-a heretofore unattainable feat without expensive numerical root finding.
LoFi: Scalable Local Image Reconstruction with Implicit Neural Representation
Nov 07, 2024Neural fields or implicit neural representations (INRs) have attracted significant attention in machine learning and signal processing due to their efficient continuous representation of images and 3D volumes. In this work, we build on INRs and introduce a coordinate-based local processing framework for solving imaging inverse problems, termed LoFi (Local Field). Unlike conventional methods for image reconstruction, LoFi processes local information at each coordinate \textit{separately} by multi-layer perceptrons (MLPs), recovering the object at that specific coordinate. Similar to INRs, LoFi can recover images at any continuous coordinate, enabling image reconstruction at multiple resolutions. With comparable or better performance than standard CNNs for image reconstruction, LoFi achieves excellent generalization to out-of-distribution data and memory usage almost independent of image resolution. Remarkably, training on $1024 \times 1024$ images requires just 3GB of memory -- over 20 times less than the memory typically needed by standard CNNs. Additionally, LoFi's local design allows it to train on extremely small datasets with less than 10 samples, without overfitting or the need for regularization or early stopping. Finally, we use LoFi as a denoising prior in a plug-and-play framework for solving general inverse problems to benefit from its continuous image representation and strong generalization. Although trained on low-resolution images, LoFi can be used as a low-dimensional prior to solve inverse problems at any resolution. We validate our framework across a variety of imaging modalities, from low-dose computed tomography to radio interferometric imaging.
SeisLM: a Foundation Model for Seismic Waveforms
Oct 21, 2024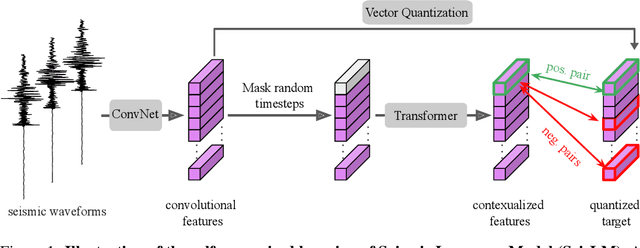
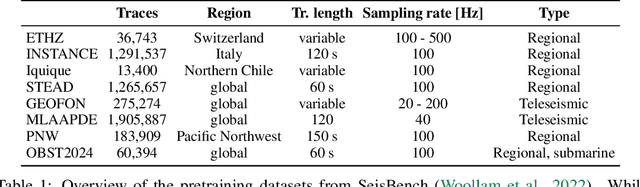
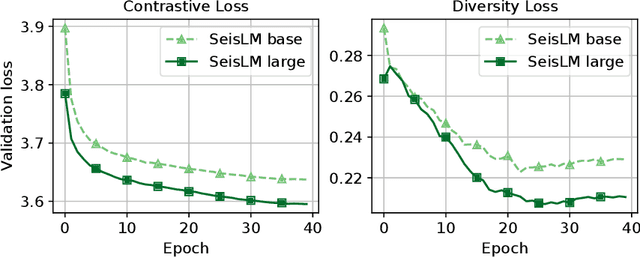
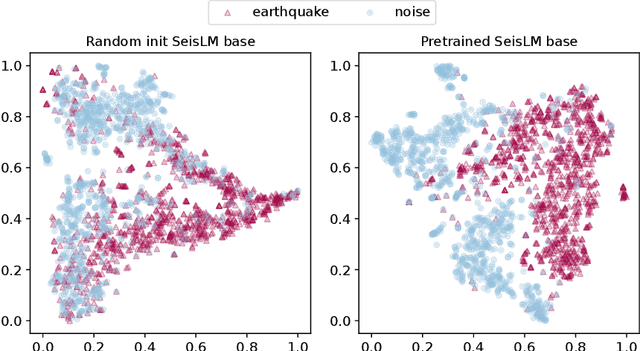
We introduce the Seismic Language Model (SeisLM), a foundational model designed to analyze seismic waveforms -- signals generated by Earth's vibrations such as the ones originating from earthquakes. SeisLM is pretrained on a large collection of open-source seismic datasets using a self-supervised contrastive loss, akin to BERT in language modeling. This approach allows the model to learn general seismic waveform patterns from unlabeled data without being tied to specific downstream tasks. When fine-tuned, SeisLM excels in seismological tasks like event detection, phase-picking, onset time regression, and foreshock-aftershock classification. The code has been made publicly available on https://github.com/liutianlin0121/seisLM.
Joint Graph Rewiring and Feature Denoising via Spectral Resonance
Aug 13, 2024



Graph neural networks (GNNs) take as input the graph structure and the feature vectors associated with the nodes. Both contain noisy information about the labels. Here we propose joint denoising and rewiring (JDR)--an algorithm to jointly denoise the graph structure and features, which can improve the performance of any downstream algorithm. We do this by defining and maximizing the alignment between the leading eigenspaces of graph and feature matrices. To approximately solve this computationally hard problem, we propose a heuristic that efficiently handles real-world graph datasets with many classes and different levels of homophily or heterophily. We experimentally verify the effectiveness of our approach on synthetic data and real-world graph datasets. The results show that JDR consistently outperforms existing rewiring methods on node classification tasks using GNNs as downstream models.
A spring-block theory of feature learning in deep neural networks
Jul 28, 2024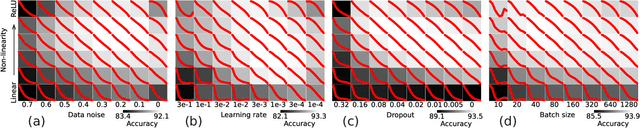
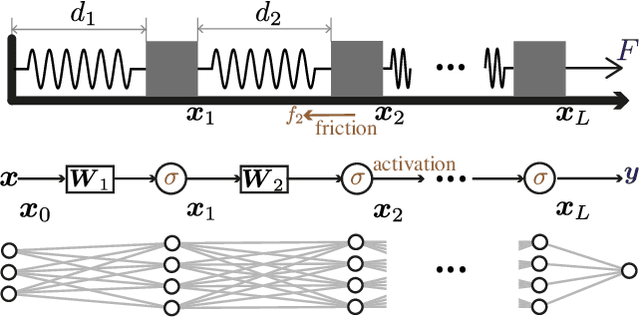
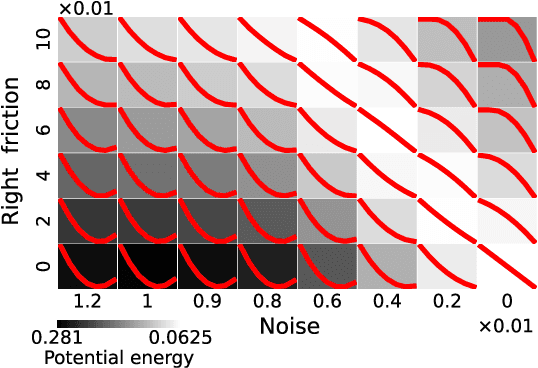
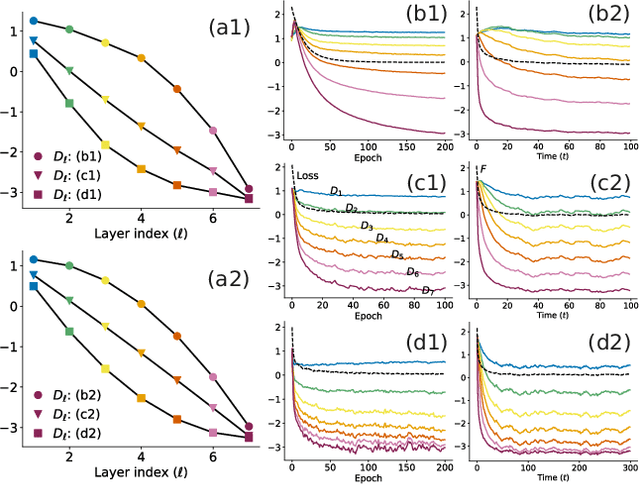
A central question in deep learning is how deep neural networks (DNNs) learn features. DNN layers progressively collapse data into a regular low-dimensional geometry. This collective effect of non-linearity, noise, learning rate, width, depth, and numerous other parameters, has eluded first-principles theories which are built from microscopic neuronal dynamics. Here we present a noise-non-linearity phase diagram that highlights where shallow or deep layers learn features more effectively. We then propose a macroscopic mechanical theory of feature learning that accurately reproduces this phase diagram, offering a clear intuition for why and how some DNNs are ``lazy'' and some are ``active'', and relating the distribution of feature learning over layers with test accuracy.
Ice-Tide: Implicit Cryo-ET Imaging and Deformation Estimation
Mar 04, 2024We introduce ICE-TIDE, a method for cryogenic electron tomography (cryo-ET) that simultaneously aligns observations and reconstructs a high-resolution volume. The alignment of tilt series in cryo-ET is a major problem limiting the resolution of reconstructions. ICE-TIDE relies on an efficient coordinate-based implicit neural representation of the volume which enables it to directly parameterize deformations and align the projections. Furthermore, the implicit network acts as an effective regularizer, allowing for high-quality reconstruction at low signal-to-noise ratios as well as partially restoring the missing wedge information. We compare the performance of ICE-TIDE to existing approaches on realistic simulated volumes where the significant gains in resolution and accuracy of recovering deformations can be precisely evaluated. Finally, we demonstrate ICE-TIDE's ability to perform on experimental data sets.