 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA spring-block theory of feature learning in deep neural networks
Paper and Code
Jul 28, 2024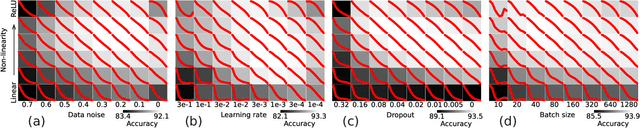
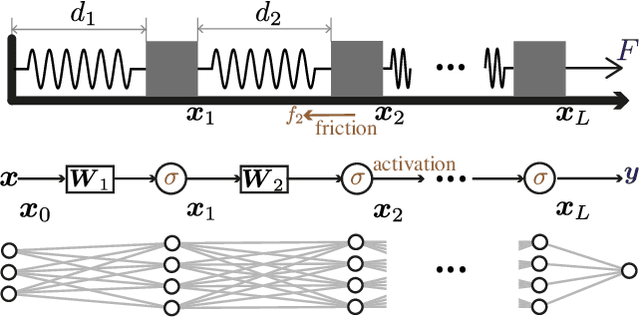
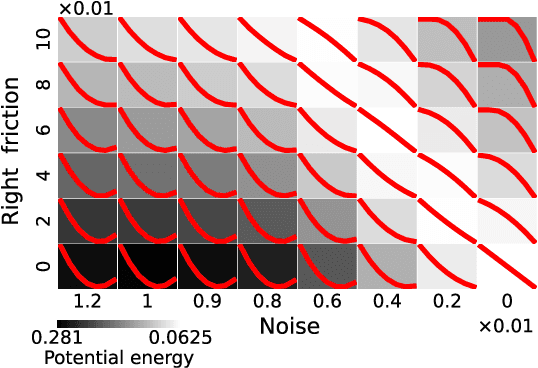
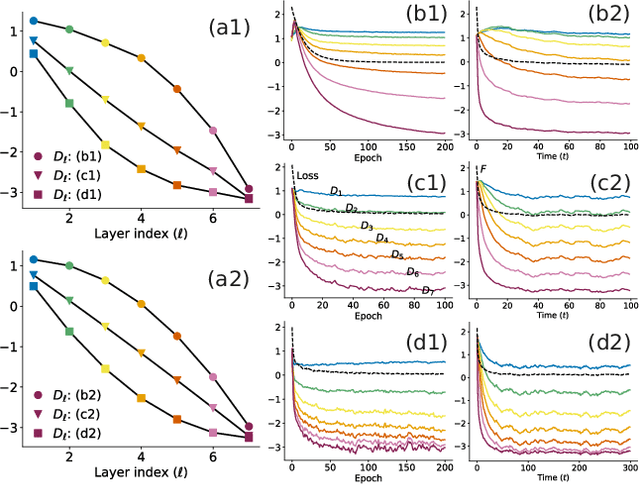
A central question in deep learning is how deep neural networks (DNNs) learn features. DNN layers progressively collapse data into a regular low-dimensional geometry. This collective effect of non-linearity, noise, learning rate, width, depth, and numerous other parameters, has eluded first-principles theories which are built from microscopic neuronal dynamics. Here we present a noise-non-linearity phase diagram that highlights where shallow or deep layers learn features more effectively. We then propose a macroscopic mechanical theory of feature learning that accurately reproduces this phase diagram, offering a clear intuition for why and how some DNNs are ``lazy'' and some are ``active'', and relating the distribution of feature learning over layers with test accuracy.