 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVADMamba++: Efficient Video Anomaly Detection via Hybrid Modeling in Grayscale Space
Apr 01, 2026VADMamba pioneered the introduction of Mamba to Video Anomaly Detection (VAD), achieving high accuracy and fast inference through hybrid proxy tasks. Nevertheless, its heavy reliance on optical flow as auxiliary input and inter-task fusion scoring constrains its applicability to a single proxy task. In this paper, we introduce VADMamba++, an efficient VAD method based on the Gray-to-RGB paradigm that enforces a Single-Channel to Three-Channel reconstruction mapping, designed for a single proxy task and operating without auxiliary inputs. This paradigm compels inferring color appearances from grayscale structures, allowing anomalies to be more effectively revealed through dual inconsistencies between structure and chromatic cues. Specifically, VADMamba++ reconstructs grayscale frames into the RGB space to simultaneously discriminate structural geometry and chromatic fidelity, thereby enhancing sensitivity to explicit visual anomalies. We further design a hybrid modeling backbone that integrates Mamba, CNN, and Transformer modules to capture diverse normal patterns while suppressing the appearance of anomalies. Furthermore, an intra-task fusion scoring strategy integrates explicit future-frame prediction errors with implicit quantized feature errors, further improving accuracy under a single task setting. Extensive experiments on three benchmark datasets demonstrate that VADMamba++ outperforms state-of-the-art methods while meeting performance and efficiency, especially under a strict single-task setting with only frame-level inputs.
WeaveTime: Stream from Earlier Frames into Emergent Memory in VideoLLMs
Feb 25, 2026Recent advances in Multimodal Large Language Models have greatly improved visual understanding and reasoning, yet their quadratic attention and offline training protocols make them ill-suited for streaming settings where frames arrive sequentially and future observations are inaccessible. We diagnose a core limitation of current Video-LLMs, namely Time-Agnosticism, in which videos are treated as an unordered bag of evidence rather than a causally ordered sequence, yielding two failures in streams: temporal order ambiguity, in which the model cannot follow or reason over the correct chronological order, and past-current focus blindness where it fails to distinguish present observations from accumulated history. We present WeaveTime, a simple, efficient, and model agnostic framework that first teaches order and then uses order. We introduce a lightweight Temporal Reconstruction objective-our Streaming Order Perception enhancement-that instills order aware representations with minimal finetuning and no specialized streaming data. At inference, a Past-Current Dynamic Focus Cache performs uncertainty triggered, coarse-to-fine retrieval, expanding history only when needed. Plugged into exsiting Video-LLM without architectural changes, WeaveTime delivers consistent gains on representative streaming benchmarks, improving accuracy while reducing latency. These results establish WeaveTime as a practical path toward time aware stream Video-LLMs under strict online, time causal constraints. Code and weights will be made publicly available. Project Page: https://zhangyl4.github.io/publications/weavetime/
Vision Transformers Need More Than Registers
Feb 25, 2026Vision Transformers (ViTs), when pre-trained on large-scale data, provide general-purpose representations for diverse downstream tasks. However, artifacts in ViTs are widely observed across different supervision paradigms and downstream tasks. Through systematic analysis of artifacts in ViTs, we find that their fundamental mechanisms have yet to be sufficiently elucidated. In this paper, through systematic analysis, we conclude that these artifacts originate from a lazy aggregation behavior: ViT uses semantically irrelevant background patches as shortcuts to represent global semantics, driven by global attention and Coarse-grained semantic supervision. Our solution selectively integrates patch features into the CLS token, reducing the influence of background-dominated shortcuts and consistently improving performance across 12 benchmarks under label-, text-, and self-supervision. We hope this work offers a new perspective on ViT behavior.
Forward Consistency Learning with Gated Context Aggregation for Video Anomaly Detection
Jan 26, 2026As a crucial element of public security, video anomaly detection (VAD) aims to measure deviations from normal patterns for various events in real-time surveillance systems. However, most existing VAD methods rely on large-scale models to pursue extreme accuracy, limiting their feasibility on resource-limited edge devices. Moreover, mainstream prediction-based VAD detects anomalies using only single-frame future prediction errors, overlooking the richer constraints from longer-term temporal forward information. In this paper, we introduce FoGA, a lightweight VAD model that performs Forward consistency learning with Gated context Aggregation, containing about 2M parameters and tailored for potential edge devices. Specifically, we propose a Unet-based method that performs feature extraction on consecutive frames to generate both immediate and forward predictions. Then, we introduce a gated context aggregation module into the skip connections to dynamically fuse encoder and decoder features at the same spatial scale. Finally, the model is jointly optimized with a novel forward consistency loss, and a hybrid anomaly measurement strategy is adopted to integrate errors from both immediate and forward frames for more accurate detection. Extensive experiments demonstrate the effectiveness of the proposed method, which substantially outperforms state-of-the-art competing methods, running up to 155 FPS. Hence, our FoGA achieves an excellent trade-off between performance and the efficiency metric.
Inverse Knowledge Search over Verifiable Reasoning: Synthesizing a Scientific Encyclopedia from a Long Chains-of-Thought Knowledge Base
Oct 30, 2025



Most scientific materials compress reasoning, presenting conclusions while omitting the derivational chains that justify them. This compression hinders verification by lacking explicit, step-wise justifications and inhibits cross-domain links by collapsing the very pathways that establish the logical and causal connections between concepts. We introduce a scalable framework that decompresses scientific reasoning, constructing a verifiable Long Chain-of-Thought (LCoT) knowledge base and projecting it into an emergent encyclopedia, SciencePedia. Our pipeline operationalizes an endpoint-driven, reductionist strategy: a Socratic agent, guided by a curriculum of around 200 courses, generates approximately 3 million first-principles questions. To ensure high fidelity, multiple independent solver models generate LCoTs, which are then rigorously filtered by prompt sanitization and cross-model answer consensus, retaining only those with verifiable endpoints. This verified corpus powers the Brainstorm Search Engine, which performs inverse knowledge search -- retrieving diverse, first-principles derivations that culminate in a target concept. This engine, in turn, feeds the Plato synthesizer, which narrates these verified chains into coherent articles. The initial SciencePedia comprises approximately 200,000 fine-grained entries spanning mathematics, physics, chemistry, biology, engineering, and computation. In evaluations across six disciplines, Plato-synthesized articles (conditioned on retrieved LCoTs) exhibit substantially higher knowledge-point density and significantly lower factual error rates than an equally-prompted baseline without retrieval (as judged by an external LLM). Built on this verifiable LCoT knowledge base, this reasoning-centric approach enables trustworthy, cross-domain scientific synthesis at scale and establishes the foundation for an ever-expanding encyclopedia.
Rethinking Query-based Transformer for Continual Image Segmentation
Jul 10, 2025Class-incremental/Continual image segmentation (CIS) aims to train an image segmenter in stages, where the set of available categories differs at each stage. To leverage the built-in objectness of query-based transformers, which mitigates catastrophic forgetting of mask proposals, current methods often decouple mask generation from the continual learning process. This study, however, identifies two key issues with decoupled frameworks: loss of plasticity and heavy reliance on input data order. To address these, we conduct an in-depth investigation of the built-in objectness and find that highly aggregated image features provide a shortcut for queries to generate masks through simple feature alignment. Based on this, we propose SimCIS, a simple yet powerful baseline for CIS. Its core idea is to directly select image features for query assignment, ensuring "perfect alignment" to preserve objectness, while simultaneously allowing queries to select new classes to promote plasticity. To further combat catastrophic forgetting of categories, we introduce cross-stage consistency in selection and an innovative "visual query"-based replay mechanism. Experiments demonstrate that SimCIS consistently outperforms state-of-the-art methods across various segmentation tasks, settings, splits, and input data orders. All models and codes will be made publicly available at https://github.com/SooLab/SimCIS.
Appearance Blur-driven AutoEncoder and Motion-guided Memory Module for Video Anomaly Detection
Sep 26, 2024Video anomaly detection (VAD) often learns the distribution of normal samples and detects the anomaly through measuring significant deviations, but the undesired generalization may reconstruct a few anomalies thus suppressing the deviations. Meanwhile, most VADs cannot cope with cross-dataset validation for new target domains, and few-shot methods must laboriously rely on model-tuning from the target domain to complete domain adaptation. To address these problems, we propose a novel VAD method with a motion-guided memory module to achieve cross-dataset validation with zero-shot. First, we add Gaussian blur to the raw appearance images, thereby constructing the global pseudo-anomaly, which serves as the input to the network. Then, we propose multi-scale residual channel attention to deblur the pseudo-anomaly in normal samples. Next, memory items are obtained by recording the motion features in the training phase, which are used to retrieve the motion features from the raw information in the testing phase. Lastly, our method can ignore the blurred real anomaly through attention and rely on motion memory items to increase the normality gap between normal and abnormal motion. Extensive experiments on three benchmark datasets demonstrate the effectiveness of the proposed method. Compared with cross-domain methods, our method achieves competitive performance without adaptation during testing.
Joint Graph Rewiring and Feature Denoising via Spectral Resonance
Aug 13, 2024



Graph neural networks (GNNs) take as input the graph structure and the feature vectors associated with the nodes. Both contain noisy information about the labels. Here we propose joint denoising and rewiring (JDR)--an algorithm to jointly denoise the graph structure and features, which can improve the performance of any downstream algorithm. We do this by defining and maximizing the alignment between the leading eigenspaces of graph and feature matrices. To approximately solve this computationally hard problem, we propose a heuristic that efficiently handles real-world graph datasets with many classes and different levels of homophily or heterophily. We experimentally verify the effectiveness of our approach on synthetic data and real-world graph datasets. The results show that JDR consistently outperforms existing rewiring methods on node classification tasks using GNNs as downstream models.
A spring-block theory of feature learning in deep neural networks
Jul 28, 2024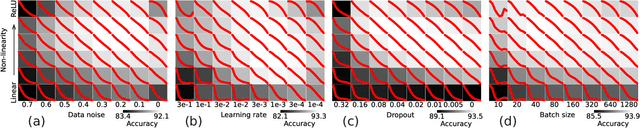
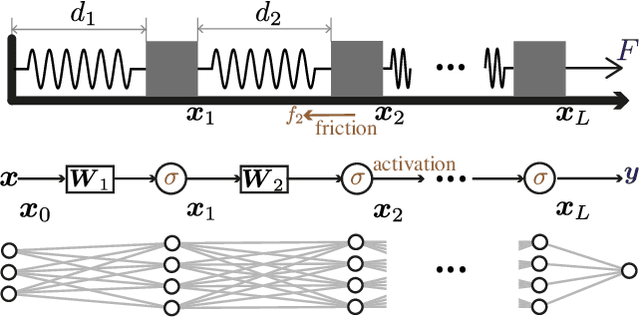
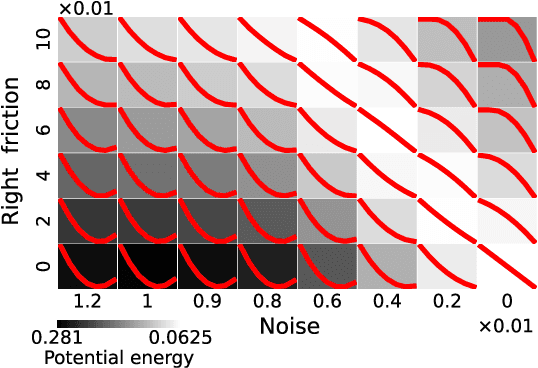
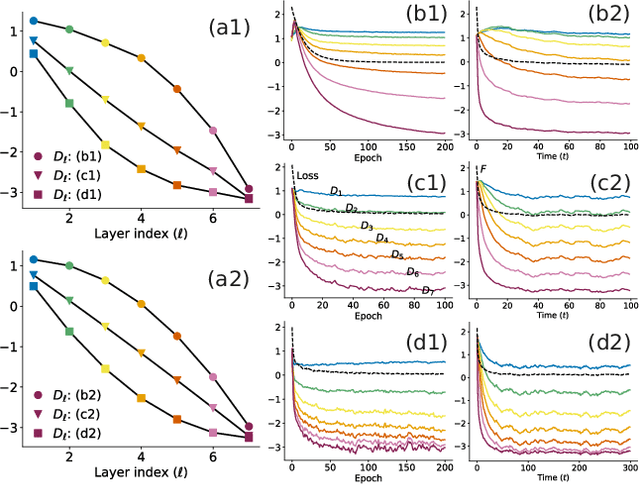
A central question in deep learning is how deep neural networks (DNNs) learn features. DNN layers progressively collapse data into a regular low-dimensional geometry. This collective effect of non-linearity, noise, learning rate, width, depth, and numerous other parameters, has eluded first-principles theories which are built from microscopic neuronal dynamics. Here we present a noise-non-linearity phase diagram that highlights where shallow or deep layers learn features more effectively. We then propose a macroscopic mechanical theory of feature learning that accurately reproduces this phase diagram, offering a clear intuition for why and how some DNNs are ``lazy'' and some are ``active'', and relating the distribution of feature learning over layers with test accuracy.
Bidirectional skip-frame prediction for video anomaly detection with intra-domain disparity-driven attention
Jul 23, 2024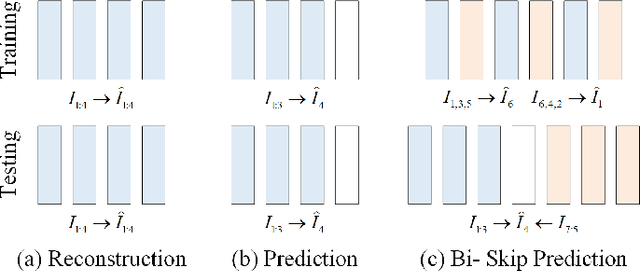
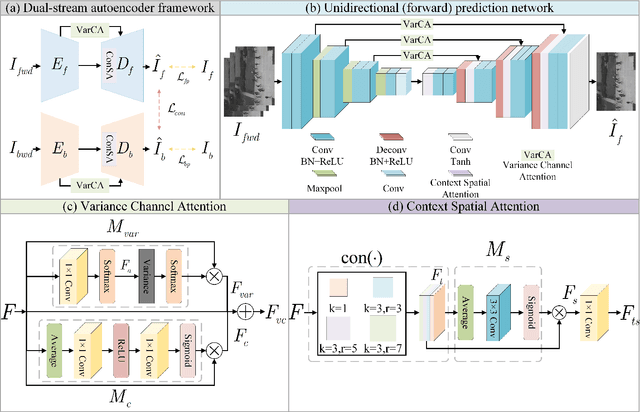

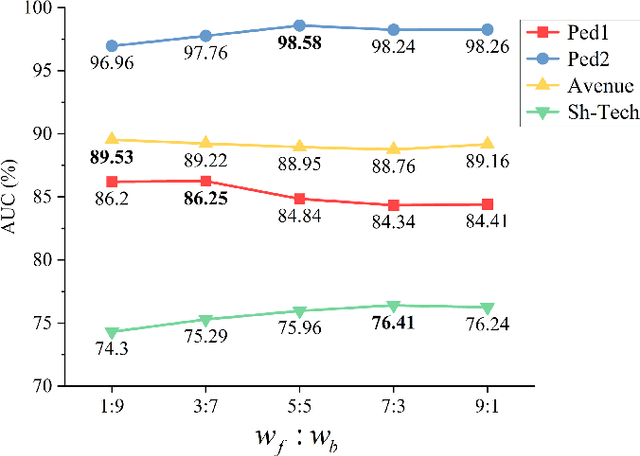
With the widespread deployment of video surveillance devices and the demand for intelligent system development, video anomaly detection (VAD) has become an important part of constructing intelligent surveillance systems. Expanding the discriminative boundary between normal and abnormal events to enhance performance is the common goal and challenge of VAD. To address this problem, we propose a Bidirectional Skip-frame Prediction (BiSP) network based on a dual-stream autoencoder, from the perspective of learning the intra-domain disparity between different features. The BiSP skips frames in the training phase to achieve the forward and backward frame prediction respectively, and in the testing phase, it utilizes bidirectional consecutive frames to co-predict the same intermediate frames, thus expanding the degree of disparity between normal and abnormal events. The BiSP designs the variance channel attention and context spatial attention from the perspectives of movement patterns and object scales, respectively, thus ensuring the maximization of the disparity between normal and abnormal in the feature extraction and delivery with different dimensions. Extensive experiments from four benchmark datasets demonstrate the effectiveness of the proposed BiSP, which substantially outperforms state-of-the-art competing methods.