 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForward Consistency Learning with Gated Context Aggregation for Video Anomaly Detection
Jan 26, 2026As a crucial element of public security, video anomaly detection (VAD) aims to measure deviations from normal patterns for various events in real-time surveillance systems. However, most existing VAD methods rely on large-scale models to pursue extreme accuracy, limiting their feasibility on resource-limited edge devices. Moreover, mainstream prediction-based VAD detects anomalies using only single-frame future prediction errors, overlooking the richer constraints from longer-term temporal forward information. In this paper, we introduce FoGA, a lightweight VAD model that performs Forward consistency learning with Gated context Aggregation, containing about 2M parameters and tailored for potential edge devices. Specifically, we propose a Unet-based method that performs feature extraction on consecutive frames to generate both immediate and forward predictions. Then, we introduce a gated context aggregation module into the skip connections to dynamically fuse encoder and decoder features at the same spatial scale. Finally, the model is jointly optimized with a novel forward consistency loss, and a hybrid anomaly measurement strategy is adopted to integrate errors from both immediate and forward frames for more accurate detection. Extensive experiments demonstrate the effectiveness of the proposed method, which substantially outperforms state-of-the-art competing methods, running up to 155 FPS. Hence, our FoGA achieves an excellent trade-off between performance and the efficiency metric.
VADMamba: Exploring State Space Models for Fast Video Anomaly Detection
Mar 27, 2025Video anomaly detection (VAD) methods are mostly CNN-based or Transformer-based, achieving impressive results, but the focus on detection accuracy often comes at the expense of inference speed. The emergence of state space models in computer vision, exemplified by the Mamba model, demonstrates improved computational efficiency through selective scans and showcases the great potential for long-range modeling. Our study pioneers the application of Mamba to VAD, dubbed VADMamba, which is based on multi-task learning for frame prediction and optical flow reconstruction. Specifically, we propose the VQ-Mamba Unet (VQ-MaU) framework, which incorporates a Vector Quantization (VQ) layer and Mamba-based Non-negative Visual State Space (NVSS) block. Furthermore, two individual VQ-MaU networks separately predict frames and reconstruct corresponding optical flows, further boosting accuracy through a clip-level fusion evaluation strategy. Experimental results validate the efficacy of the proposed VADMamba across three benchmark datasets, demonstrating superior performance in inference speed compared to previous work. Code is available at https://github.com/jLooo/VADMamba.
Appearance Blur-driven AutoEncoder and Motion-guided Memory Module for Video Anomaly Detection
Sep 26, 2024Video anomaly detection (VAD) often learns the distribution of normal samples and detects the anomaly through measuring significant deviations, but the undesired generalization may reconstruct a few anomalies thus suppressing the deviations. Meanwhile, most VADs cannot cope with cross-dataset validation for new target domains, and few-shot methods must laboriously rely on model-tuning from the target domain to complete domain adaptation. To address these problems, we propose a novel VAD method with a motion-guided memory module to achieve cross-dataset validation with zero-shot. First, we add Gaussian blur to the raw appearance images, thereby constructing the global pseudo-anomaly, which serves as the input to the network. Then, we propose multi-scale residual channel attention to deblur the pseudo-anomaly in normal samples. Next, memory items are obtained by recording the motion features in the training phase, which are used to retrieve the motion features from the raw information in the testing phase. Lastly, our method can ignore the blurred real anomaly through attention and rely on motion memory items to increase the normality gap between normal and abnormal motion. Extensive experiments on three benchmark datasets demonstrate the effectiveness of the proposed method. Compared with cross-domain methods, our method achieves competitive performance without adaptation during testing.
Bidirectional skip-frame prediction for video anomaly detection with intra-domain disparity-driven attention
Jul 23, 2024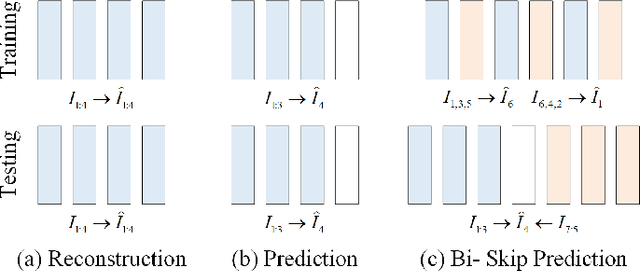
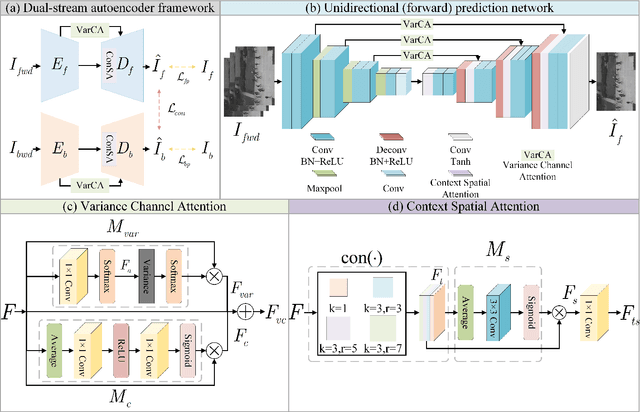

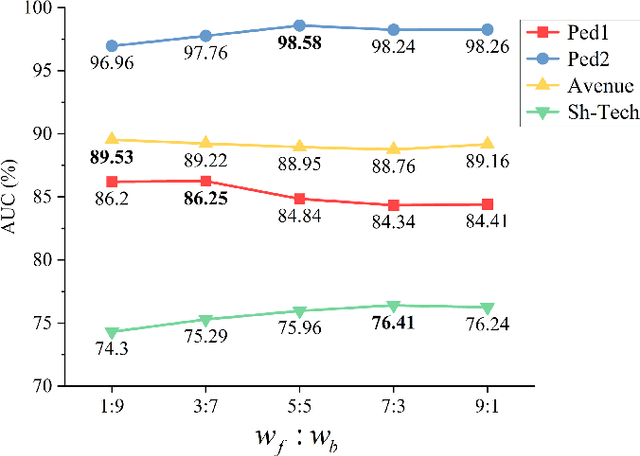
With the widespread deployment of video surveillance devices and the demand for intelligent system development, video anomaly detection (VAD) has become an important part of constructing intelligent surveillance systems. Expanding the discriminative boundary between normal and abnormal events to enhance performance is the common goal and challenge of VAD. To address this problem, we propose a Bidirectional Skip-frame Prediction (BiSP) network based on a dual-stream autoencoder, from the perspective of learning the intra-domain disparity between different features. The BiSP skips frames in the training phase to achieve the forward and backward frame prediction respectively, and in the testing phase, it utilizes bidirectional consecutive frames to co-predict the same intermediate frames, thus expanding the degree of disparity between normal and abnormal events. The BiSP designs the variance channel attention and context spatial attention from the perspectives of movement patterns and object scales, respectively, thus ensuring the maximization of the disparity between normal and abnormal in the feature extraction and delivery with different dimensions. Extensive experiments from four benchmark datasets demonstrate the effectiveness of the proposed BiSP, which substantially outperforms state-of-the-art competing methods.