 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMTBench: A Multi-Scenario Cross-Modal Collaborative Evaluation Benchmark for In-Image Machine Translation
Mar 11, 2026End-to-end In-Image Machine Translation (IIMT) aims to convert text embedded within an image into a target language while preserving the original visual context, layout, and rendering style. However, existing IIMT benchmarks are largely synthetic and thus fail to reflect real-world complexity, while current evaluation protocols focus on single-modality metrics and overlook cross-modal faithfulness between rendered text and model outputs. To address these shortcomings, we present In-image Machine Translation Benchmark (IMTBench), a new benchmark of 2,500 image translation samples covering four practical scenarios and nine languages. IMTBench supports multi-aspect evaluation, including translation quality, background preservation, overall image quality, and a cross-modal alignment score that measures consistency between the translated text produced by the model and the text rendered in the translated image. We benchmark strong commercial cascade systems, and both closed- and open-source unified multi-modal models, and observe large performance gaps across scenarios and languages, especially on natural scenes and resource-limited languages, highlighting substantial headroom for end-to-end image text translation. We hope IMTBench establishes a standardized benchmark to accelerate progress in this emerging task.
Forward Consistency Learning with Gated Context Aggregation for Video Anomaly Detection
Jan 26, 2026As a crucial element of public security, video anomaly detection (VAD) aims to measure deviations from normal patterns for various events in real-time surveillance systems. However, most existing VAD methods rely on large-scale models to pursue extreme accuracy, limiting their feasibility on resource-limited edge devices. Moreover, mainstream prediction-based VAD detects anomalies using only single-frame future prediction errors, overlooking the richer constraints from longer-term temporal forward information. In this paper, we introduce FoGA, a lightweight VAD model that performs Forward consistency learning with Gated context Aggregation, containing about 2M parameters and tailored for potential edge devices. Specifically, we propose a Unet-based method that performs feature extraction on consecutive frames to generate both immediate and forward predictions. Then, we introduce a gated context aggregation module into the skip connections to dynamically fuse encoder and decoder features at the same spatial scale. Finally, the model is jointly optimized with a novel forward consistency loss, and a hybrid anomaly measurement strategy is adopted to integrate errors from both immediate and forward frames for more accurate detection. Extensive experiments demonstrate the effectiveness of the proposed method, which substantially outperforms state-of-the-art competing methods, running up to 155 FPS. Hence, our FoGA achieves an excellent trade-off between performance and the efficiency metric.
The Devil is in Fine-tuning and Long-tailed Problems:A New Benchmark for Scene Text Detection
May 21, 2025Scene text detection has seen the emergence of high-performing methods that excel on academic benchmarks. However, these detectors often fail to replicate such success in real-world scenarios. We uncover two key factors contributing to this discrepancy through extensive experiments. First, a \textit{Fine-tuning Gap}, where models leverage \textit{Dataset-Specific Optimization} (DSO) paradigm for one domain at the cost of reduced effectiveness in others, leads to inflated performances on academic benchmarks. Second, the suboptimal performance in practical settings is primarily attributed to the long-tailed distribution of texts, where detectors struggle with rare and complex categories as artistic or overlapped text. Given that the DSO paradigm might undermine the generalization ability of models, we advocate for a \textit{Joint-Dataset Learning} (JDL) protocol to alleviate the Fine-tuning Gap. Additionally, an error analysis is conducted to identify three major categories and 13 subcategories of challenges in long-tailed scene text, upon which we propose a Long-Tailed Benchmark (LTB). LTB facilitates a comprehensive evaluation of ability to handle a diverse range of long-tailed challenges. We further introduce MAEDet, a self-supervised learning-based method, as a strong baseline for LTB. The code is available at https://github.com/pd162/LTB.
VADMamba: Exploring State Space Models for Fast Video Anomaly Detection
Mar 27, 2025Video anomaly detection (VAD) methods are mostly CNN-based or Transformer-based, achieving impressive results, but the focus on detection accuracy often comes at the expense of inference speed. The emergence of state space models in computer vision, exemplified by the Mamba model, demonstrates improved computational efficiency through selective scans and showcases the great potential for long-range modeling. Our study pioneers the application of Mamba to VAD, dubbed VADMamba, which is based on multi-task learning for frame prediction and optical flow reconstruction. Specifically, we propose the VQ-Mamba Unet (VQ-MaU) framework, which incorporates a Vector Quantization (VQ) layer and Mamba-based Non-negative Visual State Space (NVSS) block. Furthermore, two individual VQ-MaU networks separately predict frames and reconstruct corresponding optical flows, further boosting accuracy through a clip-level fusion evaluation strategy. Experimental results validate the efficacy of the proposed VADMamba across three benchmark datasets, demonstrating superior performance in inference speed compared to previous work. Code is available at https://github.com/jLooo/VADMamba.
Arbitrary Reading Order Scene Text Spotter with Local Semantics Guidance
Dec 13, 2024Scene text spotting has attracted the enthusiasm of relative researchers in recent years. Most existing scene text spotters follow the detection-then-recognition paradigm, where the vanilla detection module hardly determines the reading order and leads to failure recognition. After rethinking the auto-regressive scene text recognition method, we find that a well-trained recognizer can implicitly perceive the local semantics of all characters in a complete word or a sentence without a character-level detection module. Local semantic knowledge not only includes text content but also spatial information in the right reading order. Motivated by the above analysis, we propose the Local Semantics Guided scene text Spotter (LSGSpotter), which auto-regressively decodes the position and content of characters guided by the local semantics. Specifically, two effective modules are proposed in LSGSpotter. On the one hand, we design a Start Point Localization Module (SPLM) for locating text start points to determine the right reading order. On the other hand, a Multi-scale Adaptive Attention Module (MAAM) is proposed to adaptively aggregate text features in a local area. In conclusion, LSGSpotter achieves the arbitrary reading order spotting task without the limitation of sophisticated detection, while alleviating the cost of computational resources with the grid sampling strategy. Extensive experiment results show LSGSpotter achieves state-of-the-art performance on the InverseText benchmark. Moreover, our spotter demonstrates superior performance on English benchmarks for arbitrary-shaped text, achieving improvements of 0.7\% and 2.5\% on Total-Text and SCUT-CTW1500, respectively. These results validate our text spotter is effective for scene texts in arbitrary reading order and shape.
Appearance Blur-driven AutoEncoder and Motion-guided Memory Module for Video Anomaly Detection
Sep 26, 2024Video anomaly detection (VAD) often learns the distribution of normal samples and detects the anomaly through measuring significant deviations, but the undesired generalization may reconstruct a few anomalies thus suppressing the deviations. Meanwhile, most VADs cannot cope with cross-dataset validation for new target domains, and few-shot methods must laboriously rely on model-tuning from the target domain to complete domain adaptation. To address these problems, we propose a novel VAD method with a motion-guided memory module to achieve cross-dataset validation with zero-shot. First, we add Gaussian blur to the raw appearance images, thereby constructing the global pseudo-anomaly, which serves as the input to the network. Then, we propose multi-scale residual channel attention to deblur the pseudo-anomaly in normal samples. Next, memory items are obtained by recording the motion features in the training phase, which are used to retrieve the motion features from the raw information in the testing phase. Lastly, our method can ignore the blurred real anomaly through attention and rely on motion memory items to increase the normality gap between normal and abnormal motion. Extensive experiments on three benchmark datasets demonstrate the effectiveness of the proposed method. Compared with cross-domain methods, our method achieves competitive performance without adaptation during testing.
Bidirectional skip-frame prediction for video anomaly detection with intra-domain disparity-driven attention
Jul 23, 2024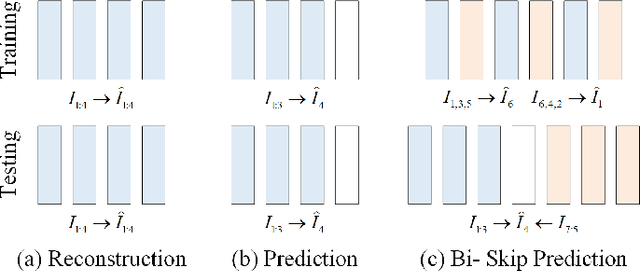
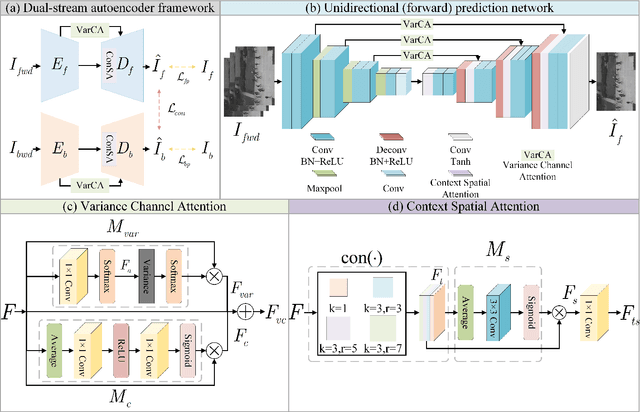

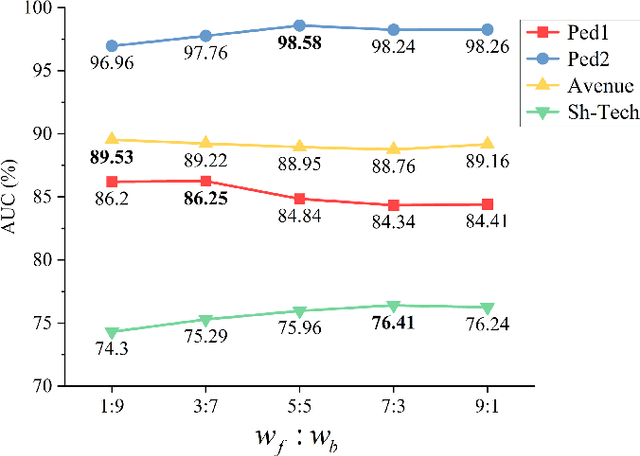
With the widespread deployment of video surveillance devices and the demand for intelligent system development, video anomaly detection (VAD) has become an important part of constructing intelligent surveillance systems. Expanding the discriminative boundary between normal and abnormal events to enhance performance is the common goal and challenge of VAD. To address this problem, we propose a Bidirectional Skip-frame Prediction (BiSP) network based on a dual-stream autoencoder, from the perspective of learning the intra-domain disparity between different features. The BiSP skips frames in the training phase to achieve the forward and backward frame prediction respectively, and in the testing phase, it utilizes bidirectional consecutive frames to co-predict the same intermediate frames, thus expanding the degree of disparity between normal and abnormal events. The BiSP designs the variance channel attention and context spatial attention from the perspectives of movement patterns and object scales, respectively, thus ensuring the maximization of the disparity between normal and abnormal in the feature extraction and delivery with different dimensions. Extensive experiments from four benchmark datasets demonstrate the effectiveness of the proposed BiSP, which substantially outperforms state-of-the-art competing methods.
TextBlockV2: Towards Precise-Detection-Free Scene Text Spotting with Pre-trained Language Model
Mar 15, 2024Existing scene text spotters are designed to locate and transcribe texts from images. However, it is challenging for a spotter to achieve precise detection and recognition of scene texts simultaneously. Inspired by the glimpse-focus spotting pipeline of human beings and impressive performances of Pre-trained Language Models (PLMs) on visual tasks, we ask: 1) "Can machines spot texts without precise detection just like human beings?", and if yes, 2) "Is text block another alternative for scene text spotting other than word or character?" To this end, our proposed scene text spotter leverages advanced PLMs to enhance performance without fine-grained detection. Specifically, we first use a simple detector for block-level text detection to obtain rough positional information. Then, we finetune a PLM using a large-scale OCR dataset to achieve accurate recognition. Benefiting from the comprehensive language knowledge gained during the pre-training phase, the PLM-based recognition module effectively handles complex scenarios, including multi-line, reversed, occluded, and incomplete-detection texts. Taking advantage of the fine-tuned language model on scene recognition benchmarks and the paradigm of text block detection, extensive experiments demonstrate the superior performance of our scene text spotter across multiple public benchmarks. Additionally, we attempt to spot texts directly from an entire scene image to demonstrate the potential of PLMs, even Large Language Models (LLMs).
Low-light Stereo Image Enhancement and De-noising in the Low-frequency Information Enhanced Image Space
Jan 15, 2024Unlike single image task, stereo image enhancement can use another view information, and its key stage is how to perform cross-view feature interaction to extract useful information from another view. However, complex noise in low-light image and its impact on subsequent feature encoding and interaction are ignored by the existing methods. In this paper, a method is proposed to perform enhancement and de-noising simultaneously. First, to reduce unwanted noise interference, a low-frequency information enhanced module (IEM) is proposed to suppress noise and produce a new image space. Additionally, a cross-channel and spatial context information mining module (CSM) is proposed to encode long-range spatial dependencies and to enhance inter-channel feature interaction. Relying on CSM, an encoder-decoder structure is constructed, incorporating cross-view and cross-scale feature interactions to perform enhancement in the new image space. Finally, the network is trained with the constraints of both spatial and frequency domain losses. Extensive experiments on both synthesized and real datasets show that our method obtains better detail recovery and noise removal compared with state-of-the-art methods. In addition, a real stereo image enhancement dataset is captured with stereo camera ZED2. The code and dataset are publicly available at: https://www.github.com/noportraits/LFENet.