 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinguistics-aware Masked Image Modeling for Self-supervised Scene Text Recognition
Mar 24, 2025Text images are unique in their dual nature, encompassing both visual and linguistic information. The visual component encompasses structural and appearance-based features, while the linguistic dimension incorporates contextual and semantic elements. In scenarios with degraded visual quality, linguistic patterns serve as crucial supplements for comprehension, highlighting the necessity of integrating both aspects for robust scene text recognition (STR). Contemporary STR approaches often use language models or semantic reasoning modules to capture linguistic features, typically requiring large-scale annotated datasets. Self-supervised learning, which lacks annotations, presents challenges in disentangling linguistic features related to the global context. Typically, sequence contrastive learning emphasizes the alignment of local features, while masked image modeling (MIM) tends to exploit local structures to reconstruct visual patterns, resulting in limited linguistic knowledge. In this paper, we propose a Linguistics-aware Masked Image Modeling (LMIM) approach, which channels the linguistic information into the decoding process of MIM through a separate branch. Specifically, we design a linguistics alignment module to extract vision-independent features as linguistic guidance using inputs with different visual appearances. As features extend beyond mere visual structures, LMIM must consider the global context to achieve reconstruction. Extensive experiments on various benchmarks quantitatively demonstrate our state-of-the-art performance, and attention visualizations qualitatively show the simultaneous capture of both visual and linguistic information.
Focus, Distinguish, and Prompt: Unleashing CLIP for Efficient and Flexible Scene Text Retrieval
Aug 01, 2024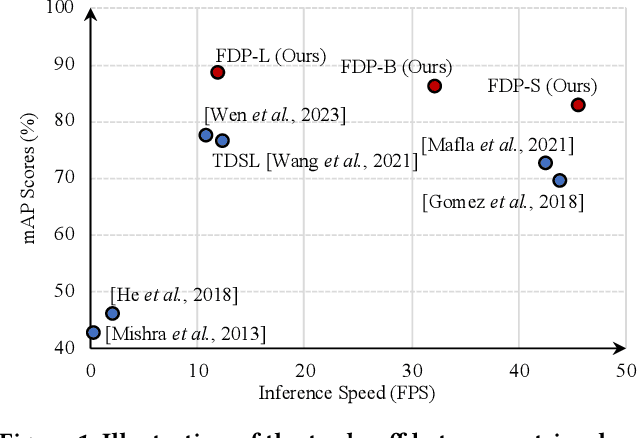
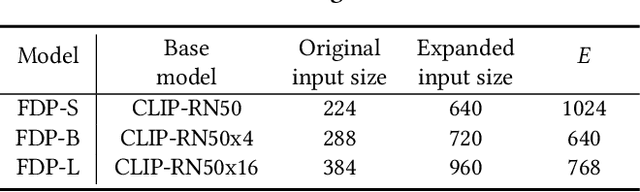


Scene text retrieval aims to find all images containing the query text from an image gallery. Current efforts tend to adopt an Optical Character Recognition (OCR) pipeline, which requires complicated text detection and/or recognition processes, resulting in inefficient and inflexible retrieval. Different from them, in this work we propose to explore the intrinsic potential of Contrastive Language-Image Pre-training (CLIP) for OCR-free scene text retrieval. Through empirical analysis, we observe that the main challenges of CLIP as a text retriever are: 1) limited text perceptual scale, and 2) entangled visual-semantic concepts. To this end, a novel model termed FDP (Focus, Distinguish, and Prompt) is developed. FDP first focuses on scene text via shifting the attention to the text area and probing the hidden text knowledge, and then divides the query text into content word and function word for processing, in which a semantic-aware prompting scheme and a distracted queries assistance module are utilized. Extensive experiments show that FDP significantly enhances the inference speed while achieving better or competitive retrieval accuracy compared to existing methods. Notably, on the IIIT-STR benchmark, FDP surpasses the state-of-the-art model by 4.37% with a 4 times faster speed. Furthermore, additional experiments under phrase-level and attribute-aware scene text retrieval settings validate FDP's particular advantages in handling diverse forms of query text. The source code will be publicly available at https://github.com/Gyann-z/FDP.
TextBlockV2: Towards Precise-Detection-Free Scene Text Spotting with Pre-trained Language Model
Mar 15, 2024Existing scene text spotters are designed to locate and transcribe texts from images. However, it is challenging for a spotter to achieve precise detection and recognition of scene texts simultaneously. Inspired by the glimpse-focus spotting pipeline of human beings and impressive performances of Pre-trained Language Models (PLMs) on visual tasks, we ask: 1) "Can machines spot texts without precise detection just like human beings?", and if yes, 2) "Is text block another alternative for scene text spotting other than word or character?" To this end, our proposed scene text spotter leverages advanced PLMs to enhance performance without fine-grained detection. Specifically, we first use a simple detector for block-level text detection to obtain rough positional information. Then, we finetune a PLM using a large-scale OCR dataset to achieve accurate recognition. Benefiting from the comprehensive language knowledge gained during the pre-training phase, the PLM-based recognition module effectively handles complex scenarios, including multi-line, reversed, occluded, and incomplete-detection texts. Taking advantage of the fine-tuned language model on scene recognition benchmarks and the paradigm of text block detection, extensive experiments demonstrate the superior performance of our scene text spotter across multiple public benchmarks. Additionally, we attempt to spot texts directly from an entire scene image to demonstrate the potential of PLMs, even Large Language Models (LLMs).
Precedence-Constrained Winter Value for Effective Graph Data Valuation
Feb 02, 2024



Data valuation is essential for quantifying data's worth, aiding in assessing data quality and determining fair compensation. While existing data valuation methods have proven effective in evaluating the value of Euclidean data, they face limitations when applied to the increasingly popular graph-structured data. Particularly, graph data valuation introduces unique challenges, primarily stemming from the intricate dependencies among nodes and the exponential growth in value estimation costs. To address the challenging problem of graph data valuation, we put forth an innovative solution, Precedence-Constrained Winter (PC-Winter) Value, to account for the complex graph structure. Furthermore, we develop a variety of strategies to address the computational challenges and enable efficient approximation of PC-Winter. Extensive experiments demonstrate the effectiveness of PC-Winter across diverse datasets and tasks.
Masked and Permuted Implicit Context Learning for Scene Text Recognition
May 25, 2023



Scene Text Recognition (STR) is a challenging task due to variations in text style, shape, and background. Incorporating linguistic information is an effective way to enhance the robustness of STR models. Existing methods rely on permuted language modeling (PLM) or masked language modeling (MLM) to learn contextual information implicitly, either through an ensemble of permuted autoregressive (AR) LMs training or iterative non-autoregressive (NAR) decoding procedure. However, these methods exhibit limitations: PLM's AR decoding results in the lack of information about future characters, while MLM provides global information of the entire text but neglects dependencies among each predicted character. In this paper, we propose a Masked and Permuted Implicit Context Learning Network for STR, which unifies PLM and MLM within a single decoding architecture, inheriting the advantages of both approaches. We utilize the training procedure of PLM, and to integrate MLM, we incorporate word length information into the decoding process by introducing specific numbers of mask tokens. Experimental results demonstrate that our proposed model achieves state-of-the-art performance on standard benchmarks using both AR and NAR decoding procedures.
PIMNet: A Parallel, Iterative and Mimicking Network for Scene Text Recognition
Sep 09, 2021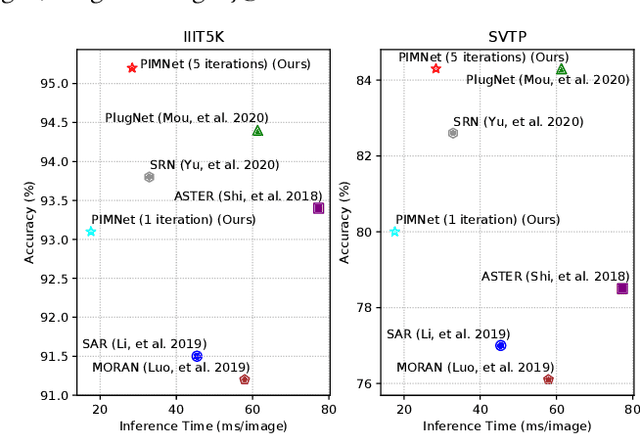
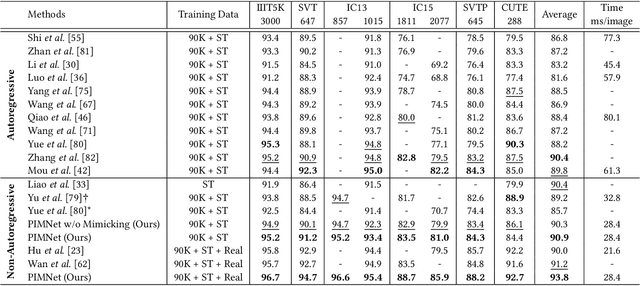
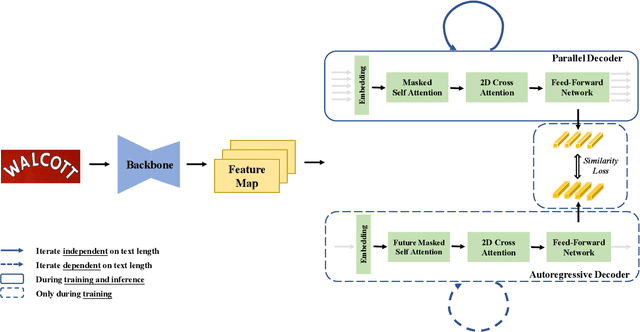

Nowadays, scene text recognition has attracted more and more attention due to its various applications. Most state-of-the-art methods adopt an encoder-decoder framework with attention mechanism, which generates text autoregressively from left to right. Despite the convincing performance, the speed is limited because of the one-by-one decoding strategy. As opposed to autoregressive models, non-autoregressive models predict the results in parallel with a much shorter inference time, but the accuracy falls behind the autoregressive counterpart considerably. In this paper, we propose a Parallel, Iterative and Mimicking Network (PIMNet) to balance accuracy and efficiency. Specifically, PIMNet adopts a parallel attention mechanism to predict the text faster and an iterative generation mechanism to make the predictions more accurate. In each iteration, the context information is fully explored. To improve learning of the hidden layer, we exploit the mimicking learning in the training phase, where an additional autoregressive decoder is adopted and the parallel decoder mimics the autoregressive decoder with fitting outputs of the hidden layer. With the shared backbone between the two decoders, the proposed PIMNet can be trained end-to-end without pre-training. During inference, the branch of the autoregressive decoder is removed for a faster speed. Extensive experiments on public benchmarks demonstrate the effectiveness and efficiency of PIMNet. Our code will be available at https://github.com/Pay20Y/PIMNet.
Domain Constraint Approximation based Semi Supervision
Feb 11, 2019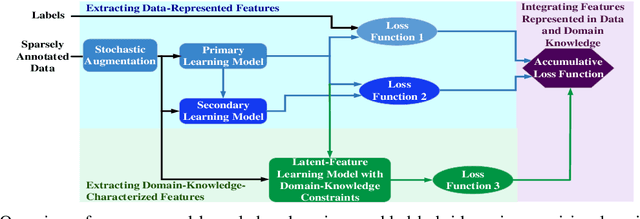
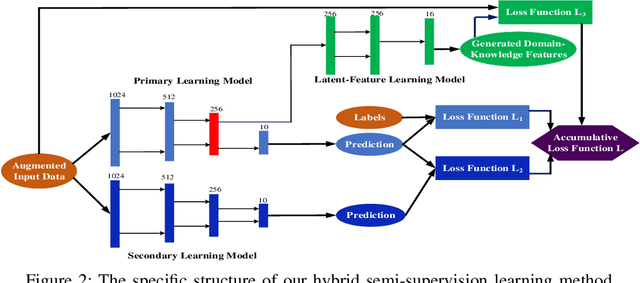
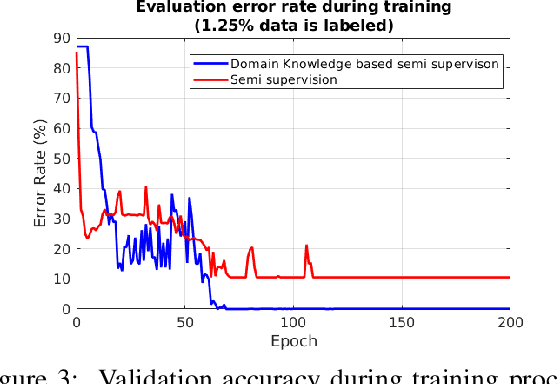
Deep learning for supervised learning has achieved astonishing performance in various machine learning applications. However, annotated data is expensive and rare. In practice, only a small portion of data samples are annotated. Pseudo-ensembling-based approaches have achieved state-of-the-art results in computer vision related tasks. However, it still relies on the quality of an initial model built by labeled data. Less labeled data may degrade model performance a lot. Domain constraint is another way regularize the posterior but has some limitation. In this paper, we proposed a fuzzy domain-constraint-based framework which loses the requirement of traditional constraint learning and enhances the model quality for semi supervision. Simulations results show the effectiveness of our design.
Blockchain as a Service: An Autonomous, Privacy Preserving, Decentralized Architecture for Deep Learning
Jul 05, 2018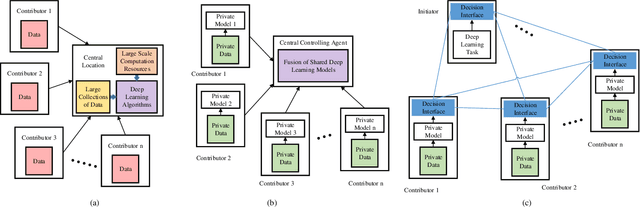
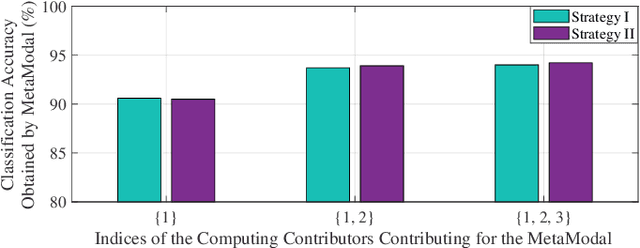


Deep learning algorithms have recently gained attention due to their inherent capabilities and the application opportunities that they provide. Two of the main reasons for the success of deep learning methods are the availability of processing power and big data. Both of these two are expensive and rare commodities that present limitations to the usage and implementation of deep learning. Decentralization of the processing and data is one of the most prevalent solutions for these issues. This paper proposes a cooperative decentralized deep learning architecture. The contributors can train deep learning models with private data and share them to the cooperative data-driven applications initiated elsewhere. Shared models are fused together to obtain a better model. In this work, the contributors can both design their own models or train the models provided by the initiator. In order to utilize an efficient decentralized learning algorithm, blockchain technology is incorporated as a method of creating an incentive-compatible market. In the proposed method, Ethereum blockchain's scripting capabilities are employed to devise a decentralized deep learning mechanism, which provides much higher, collective processing power and grants access to large amounts of data, which would be otherwise inaccessible. The technical description of the mechanism is described and the simulation results are presented.