 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Cascade Mitigation in Power Systems Using Influence Graph Improved by Reinforcement Learning
Jun 10, 2025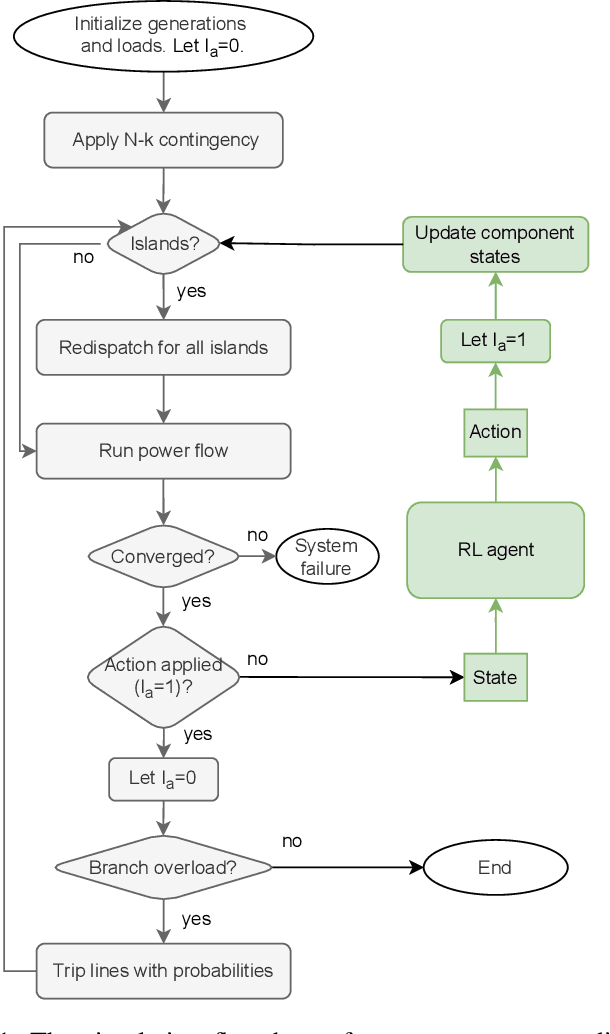
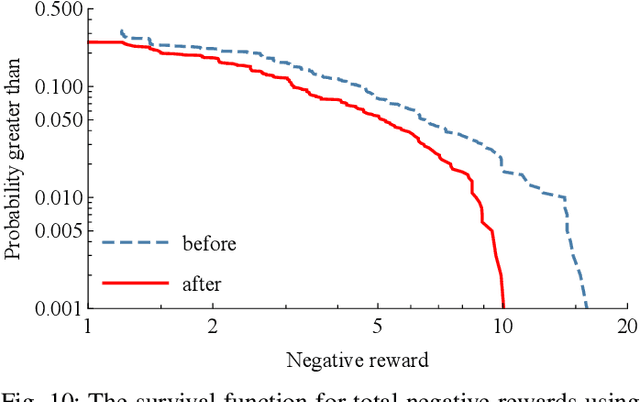
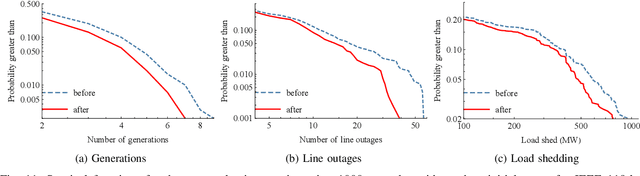
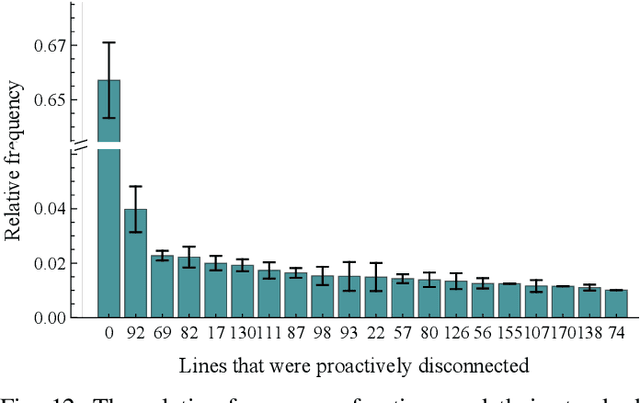
Despite high reliability, modern power systems with growing renewable penetration face an increasing risk of cascading outages. Real-time cascade mitigation requires fast, complex operational decisions under uncertainty. In this work, we extend the influence graph into a Markov decision process model (MDP) for real-time mitigation of cascading outages in power transmission systems, accounting for uncertainties in generation, load, and initial contingencies. The MDP includes a do-nothing action to allow for conservative decision-making and is solved using reinforcement learning. We present a policy gradient learning algorithm initialized with a policy corresponding to the unmitigated case and designed to handle invalid actions. The proposed learning method converges faster than the conventional algorithm. Through careful reward design, we learn a policy that takes conservative actions without deteriorating system conditions. The model is validated on the IEEE 14-bus and IEEE 118-bus systems. The results show that proactive line disconnections can effectively reduce cascading risk, and certain lines consistently emerge as critical in mitigating cascade propagation.
Zero-shot Large Language Models for Long Clinical Text Summarization with Temporal Reasoning
Jan 30, 2025



Recent advancements in large language models (LLMs) have shown potential for transforming data processing in healthcare, particularly in understanding complex clinical narratives. This study evaluates the efficacy of zero-shot LLMs in summarizing long clinical texts that require temporal reasoning, a critical aspect for comprehensively capturing patient histories and treatment trajectories. We applied a series of advanced zero-shot LLMs to extensive clinical documents, assessing their ability to integrate and accurately reflect temporal dynamics without prior task-specific training. While the models efficiently identified key temporal events, they struggled with chronological coherence over prolonged narratives. The evaluation, combining quantitative and qualitative methods, highlights the strengths and limitations of zero-shot LLMs in clinical text summarization. The results suggest that while promising, zero-shot LLMs require further refinement to effectively support clinical decision-making processes, underscoring the need for enhanced model training approaches that better capture the nuances of temporal information in long context medical documents.
PCNN: Pattern-based Fine-Grained Regular Pruning towards Optimizing CNN Accelerators
Feb 11, 2020
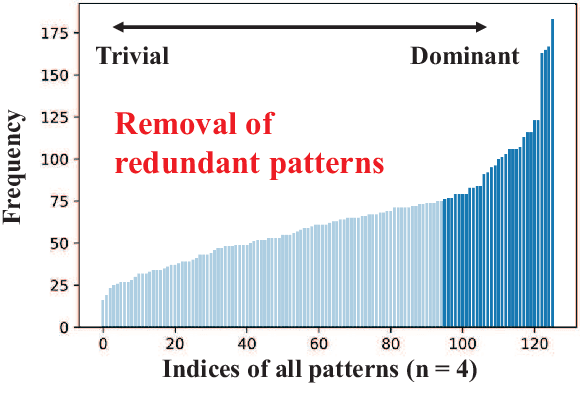
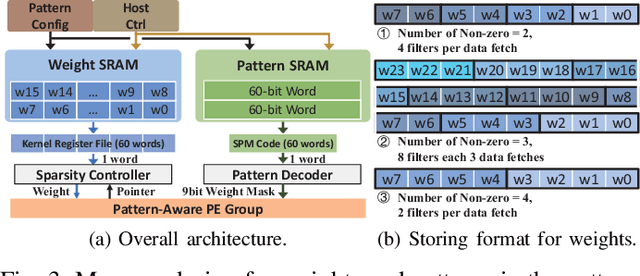
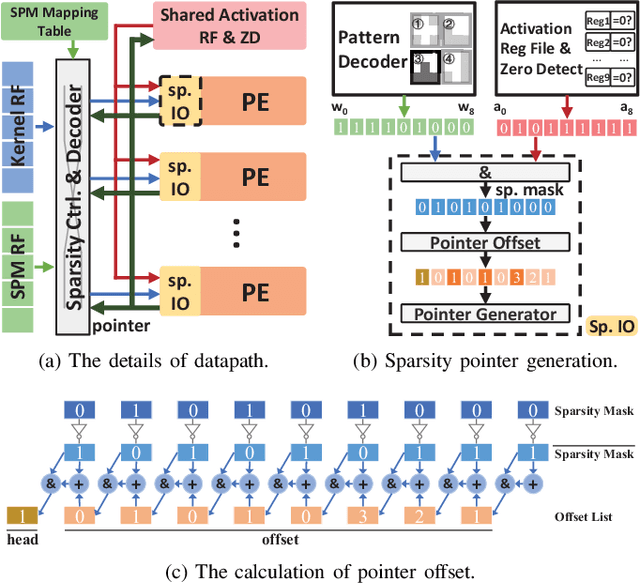
Weight pruning is a powerful technique to realize model compression. We propose PCNN, a fine-grained regular 1D pruning method. A novel index format called Sparsity Pattern Mask (SPM) is presented to encode the sparsity in PCNN. Leveraging SPM with limited pruning patterns and non-zero sequences with equal length, PCNN can be efficiently employed in hardware. Evaluated on VGG-16 and ResNet-18, our PCNN achieves the compression rate up to 8.4X with only 0.2% accuracy loss. We also implement a pattern-aware architecture in 55nm process, achieving up to 9.0X speedup and 28.39 TOPS/W efficiency with only 3.1% on-chip memory overhead of indices.
Domain Constraint Approximation based Semi Supervision
Feb 11, 2019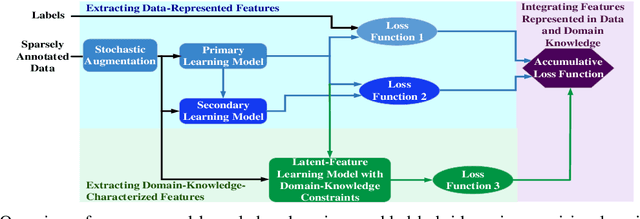
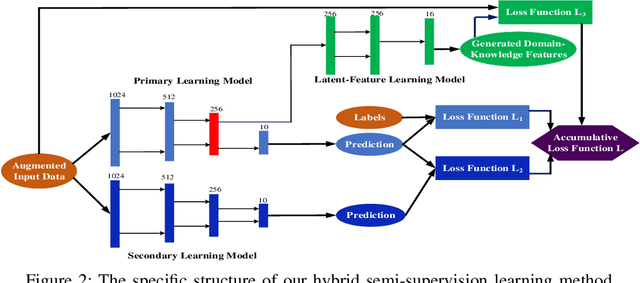
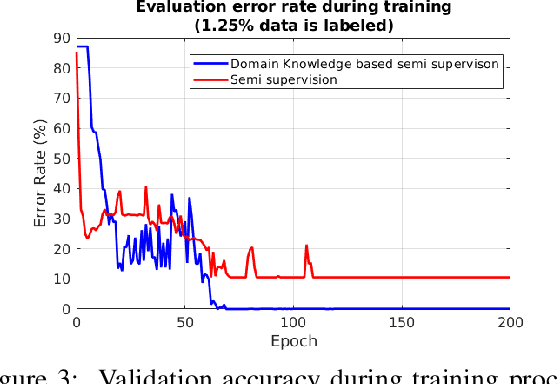
Deep learning for supervised learning has achieved astonishing performance in various machine learning applications. However, annotated data is expensive and rare. In practice, only a small portion of data samples are annotated. Pseudo-ensembling-based approaches have achieved state-of-the-art results in computer vision related tasks. However, it still relies on the quality of an initial model built by labeled data. Less labeled data may degrade model performance a lot. Domain constraint is another way regularize the posterior but has some limitation. In this paper, we proposed a fuzzy domain-constraint-based framework which loses the requirement of traditional constraint learning and enhances the model quality for semi supervision. Simulations results show the effectiveness of our design.