 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Subspace Clustering Methods
May 11, 2025To further utilize the unsupervised features and pairwise information, we propose a general Bilevel Clustering Optimization (BCO) framework to improve the performance of clustering. And then we introduce three special cases on subspace clustering with two different types of masks. At first, we reformulate the original subspace clustering as a Basic Masked Subspace Clustering (BMSC), which reformulate the diagonal constraints to a hard mask. Then, we provide a General Masked Subspace Clustering (GMSC) method to integrate different clustering via a soft mask. Furthermore, based on BCO and GMSC, we induce a learnable soft mask and design a Recursive Masked Subspace Clustering (RMSC) method that can alternately update the affinity matrix and the soft mask. Numerical experiments show that our models obtain significant improvement compared with the baselines on several commonly used datasets, such as MNIST, USPS, ORL, COIL20 and COIL100.
Fast and Scalable Semi-Supervised Learning for Multi-View Subspace Clustering
Aug 11, 2024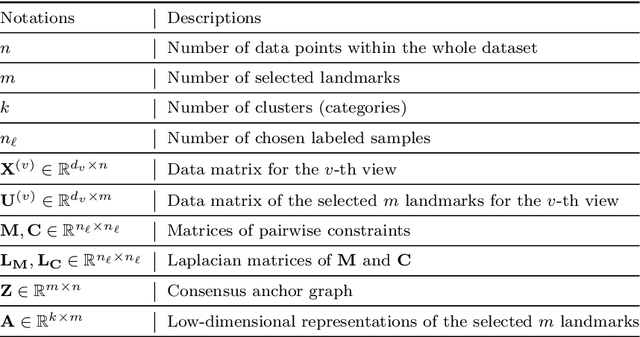
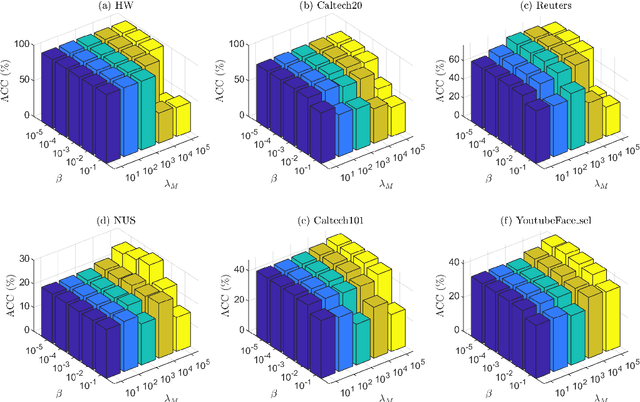
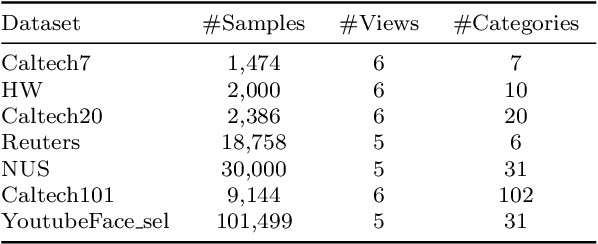
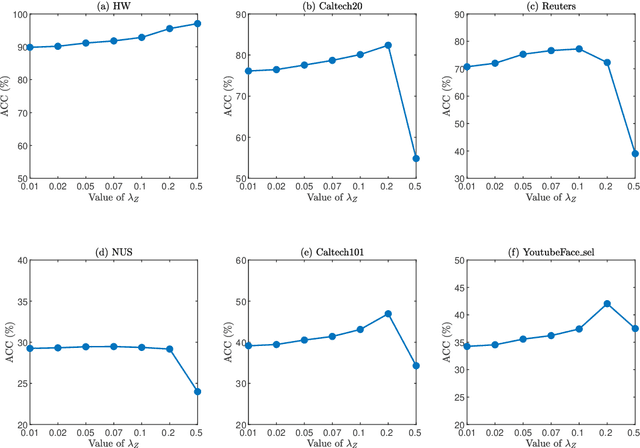
In this paper, we introduce a Fast and Scalable Semi-supervised Multi-view Subspace Clustering (FSSMSC) method, a novel solution to the high computational complexity commonly found in existing approaches. FSSMSC features linear computational and space complexity relative to the size of the data. The method generates a consensus anchor graph across all views, representing each data point as a sparse linear combination of chosen landmarks. Unlike traditional methods that manage the anchor graph construction and the label propagation process separately, this paper proposes a unified optimization model that facilitates simultaneous learning of both. An effective alternating update algorithm with convergence guarantees is proposed to solve the unified optimization model. Additionally, the method employs the obtained anchor graph and landmarks' low-dimensional representations to deduce low-dimensional representations for raw data. Following this, a straightforward clustering approach is conducted on these low-dimensional representations to achieve the final clustering results. The effectiveness and efficiency of FSSMSC are validated through extensive experiments on multiple benchmark datasets of varying scales.
PCNN: Pattern-based Fine-Grained Regular Pruning towards Optimizing CNN Accelerators
Feb 11, 2020
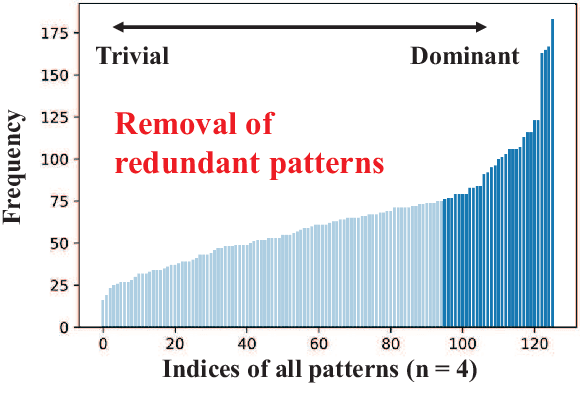
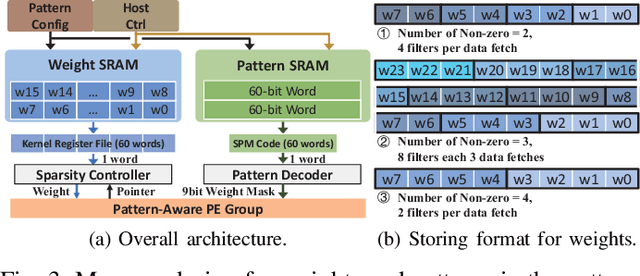
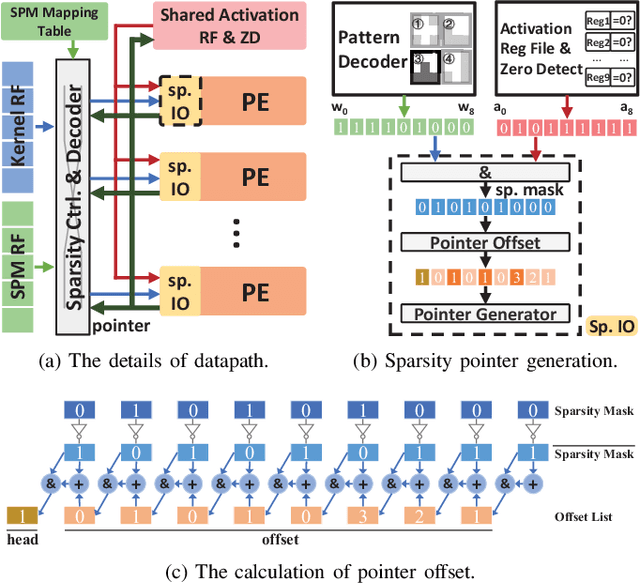
Weight pruning is a powerful technique to realize model compression. We propose PCNN, a fine-grained regular 1D pruning method. A novel index format called Sparsity Pattern Mask (SPM) is presented to encode the sparsity in PCNN. Leveraging SPM with limited pruning patterns and non-zero sequences with equal length, PCNN can be efficiently employed in hardware. Evaluated on VGG-16 and ResNet-18, our PCNN achieves the compression rate up to 8.4X with only 0.2% accuracy loss. We also implement a pattern-aware architecture in 55nm process, achieving up to 9.0X speedup and 28.39 TOPS/W efficiency with only 3.1% on-chip memory overhead of indices.
Light-weight Calibrator: a Separable Component for Unsupervised Domain Adaptation
Nov 28, 2019
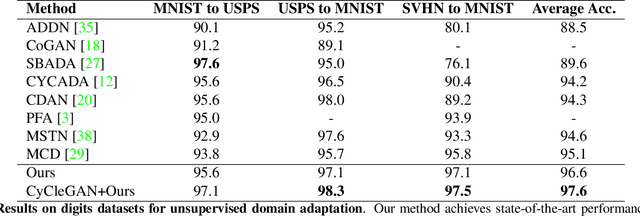
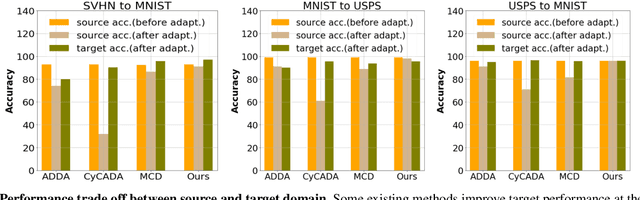

Existing domain adaptation methods aim at learning features that can be generalized among domains. These methods commonly require to update source classifier to adapt to the target domain and do not properly handle the trade off between the source domain and the target domain. In this work, instead of training a classifier to adapt to the target domain, we use a separable component called data calibrator to help the fixed source classifier recover discrimination power in the target domain, while preserving the source domain's performance. When the difference between two domains is small, the source classifier's representation is sufficient to perform well in the target domain and outperforms GAN-based methods in digits. Otherwise, the proposed method can leverage synthetic images generated by GANs to boost performance and achieve state-of-the-art performance in digits datasets and driving scene semantic segmentation. Our method empirically reveals that certain intriguing hints, which can be mitigated by adversarial attack to domain discriminators, are one of the sources for performance degradation under the domain shift. Code release is at https://github.com/yeshaokai/Calibrator-Domain-Adaptation.
SCAN: A Scalable Neural Networks Framework Towards Compact and Efficient Models
May 27, 2019
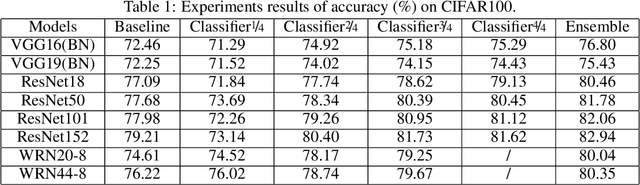
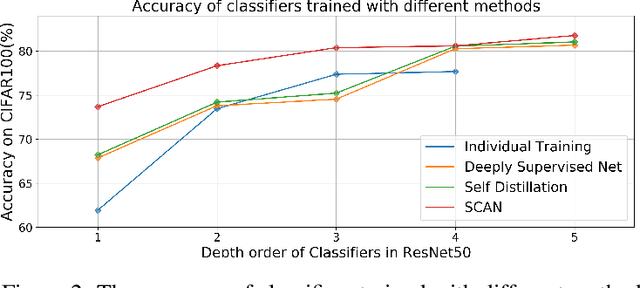
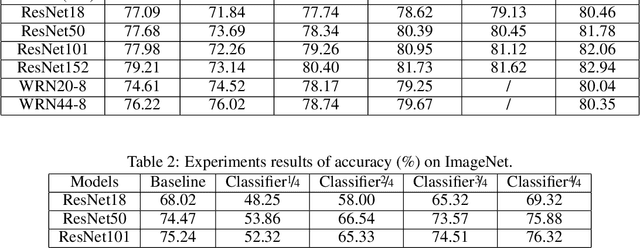
Remarkable achievements have been attained by deep neural networks in various applications. However, the increasing depth and width of such models also lead to explosive growth in both storage and computation, which has restricted the deployment of deep neural networks on resource-limited edge devices. To address this problem, we propose the so-called SCAN framework for networks training and inference, which is orthogonal and complementary to existing acceleration and compression methods. The proposed SCAN firstly divides neural networks into multiple sections according to their depth and constructs shallow classifiers upon the intermediate features of different sections. Moreover, attention modules and knowledge distillation are utilized to enhance the accuracy of shallow classifiers. Based on this architecture, we further propose a threshold controlled scalable inference mechanism to approach human-like sample-specific inference. Experimental results show that SCAN can be easily equipped on various neural networks without any adjustment on hyper-parameters or neural networks architectures, yielding significant performance gain on CIFAR100 and ImageNet. Codes will be released on github soon.
Be Your Own Teacher: Improve the Performance of Convolutional Neural Networks via Self Distillation
May 17, 2019



Convolutional neural networks have been widely deployed in various application scenarios. In order to extend the applications' boundaries to some accuracy-crucial domains, researchers have been investigating approaches to boost accuracy through either deeper or wider network structures, which brings with them the exponential increment of the computational and storage cost, delaying the responding time. In this paper, we propose a general training framework named self distillation, which notably enhances the performance (accuracy) of convolutional neural networks through shrinking the size of the network rather than aggrandizing it. Different from traditional knowledge distillation - a knowledge transformation methodology among networks, which forces student neural networks to approximate the softmax layer outputs of pre-trained teacher neural networks, the proposed self distillation framework distills knowledge within network itself. The networks are firstly divided into several sections. Then the knowledge in the deeper portion of the networks is squeezed into the shallow ones. Experiments further prove the generalization of the proposed self distillation framework: enhancement of accuracy at average level is 2.65%, varying from 0.61% in ResNeXt as minimum to 4.07% in VGG19 as maximum. In addition, it can also provide flexibility of depth-wise scalable inference on resource-limited edge devices.Our codes will be released on github soon.