 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Should a Robot Think? Resource-Aware Reasoning via Reinforcement Learning for Embodied Robotic Decision-Making
Mar 17, 2026Embodied robotic systems increasingly rely on large language model (LLM)-based agents to support high-level reasoning, planning, and decision-making during interactions with the environment. However, invoking LLM reasoning introduces substantial computational latency and resource overhead, which can interrupt action execution and reduce system reliability. Excessive reasoning may delay actions, while insufficient reasoning often leads to incorrect decisions and task failures. This raises a fundamental question for embodied agents: when should the agent reason, and when should it act? In this work, we propose RARRL (Resource-Aware Reasoning via Reinforcement Learning), a hierarchical framework for resource-aware orchestration of embodied agents. Rather than learning low-level control policies, RARRL learns a high-level orchestration policy that operates at the agent's decision-making layer. This policy enables the agent to adaptively determine whether to invoke reasoning, which reasoning role to employ, and how much computational budget to allocate based on current observations, execution history, and remaining resources. Extensive experiments, including evaluations with empirical latency profiles derived from the ALFRED benchmark, show that RARRL consistently improves task success rates while reducing execution latency and enhancing robustness compared with fixed or heuristic reasoning strategies. These results demonstrate that adaptive reasoning control is essential for building reliable and efficient embodied robotic agents.
A Very Big Video Reasoning Suite
Feb 24, 2026Rapid progress in video models has largely focused on visual quality, leaving their reasoning capabilities underexplored. Video reasoning grounds intelligence in spatiotemporally consistent visual environments that go beyond what text can naturally capture, enabling intuitive reasoning over spatiotemporal structure such as continuity, interaction, and causality. However, systematically studying video reasoning and its scaling behavior is hindered by the lack of large-scale training data. To address this gap, we introduce the Very Big Video Reasoning (VBVR) Dataset, an unprecedentedly large-scale resource spanning 200 curated reasoning tasks following a principled taxonomy and over one million video clips, approximately three orders of magnitude larger than existing datasets. We further present VBVR-Bench, a verifiable evaluation framework that moves beyond model-based judging by incorporating rule-based, human-aligned scorers, enabling reproducible and interpretable diagnosis of video reasoning capabilities. Leveraging the VBVR suite, we conduct one of the first large-scale scaling studies of video reasoning and observe early signs of emergent generalization to unseen reasoning tasks. Together, VBVR lays a foundation for the next stage of research in generalizable video reasoning. The data, benchmark toolkit, and models are publicly available at https://video-reason.com/ .
Effective MoE-based LLM Compression by Exploiting Heterogeneous Inter-Group Experts Routing Frequency and Information Density
Feb 11, 2026Mixture-of-Experts (MoE) based Large Language Models (LLMs) have achieved superior performance, yet the massive memory overhead caused by storing multiple expert networks severely hinders their practical deployment. Singular Value Decomposition (SVD)-based compression has emerged as a promising post-training technique; however, most existing methods apply uniform rank allocation or rely solely on static weight properties. This overlooks the substantial heterogeneity in expert utilization observed in MoE models, where frequent routing patterns and intrinsic information density vary significantly across experts. In this work, we propose RFID-MoE, an effective framework for MoE compression by exploiting heterogeneous Routing Frequency and Information Density. We first introduce a fused metric that combines expert activation frequency with effective rank to measure expert importance, adaptively allocating higher ranks to critical expert groups under a fixed budget. Moreover, instead of discarding compression residuals, we reconstruct them via a parameter-efficient sparse projection mechanism to recover lost information with minimal parameter overhead. Extensive experiments on representative MoE LLMs (e.g., Qwen3, DeepSeekMoE) across multiple compression ratios demonstrate that RFID-MoE consistently outperforms state-of-the-art methods like MoBE and D2-MoE. Notably, RFID-MoE achieves a perplexity of 16.92 on PTB with the Qwen3-30B model at a 60% compression ratio, reducing perplexity by over 8.0 compared to baselines, and improves zero-shot accuracy on HellaSwag by approximately 8%.
S2DiT: Sandwich Diffusion Transformer for Mobile Streaming Video Generation
Jan 19, 2026Diffusion Transformers (DiTs) have recently improved video generation quality. However, their heavy computational cost makes real-time or on-device generation infeasible. In this work, we introduce S2DiT, a Streaming Sandwich Diffusion Transformer designed for efficient, high-fidelity, and streaming video generation on mobile hardware. S2DiT generates more tokens but maintains efficiency with novel efficient attentions: a mixture of LinConv Hybrid Attention (LCHA) and Stride Self-Attention (SSA). Based on this, we uncover the sandwich design via a budget-aware dynamic programming search, achieving superior quality and efficiency. We further propose a 2-in-1 distillation framework that transfers the capacity of large teacher models (e.g., Wan 2.2-14B) to the compact few-step sandwich model. Together, S2DiT achieves quality on par with state-of-the-art server video models, while streaming at over 10 FPS on an iPhone.
Q-realign: Piggybacking Realignment on Quantization for Safe and Efficient LLM Deployment
Jan 13, 2026Public large language models (LLMs) are typically safety-aligned during pretraining, yet task-specific fine-tuning required for deployment often erodes this alignment and introduces safety risks. Existing defenses either embed safety recovery into fine-tuning or rely on fine-tuning-derived priors for post-hoc correction, leaving safety recovery tightly coupled with training and incurring high computational overhead and a complex workflow. To address these challenges, we propose \texttt{Q-realign}, a post-hoc defense method based on post-training quantization, guided by an analysis of representational structure. By reframing quantization as a dual-objective procedure for compression and safety, \texttt{Q-realign} decouples safety alignment from fine-tuning and naturally piggybacks into modern deployment pipelines. Experiments across multiple models and datasets demonstrate that our method substantially reduces unsafe behaviors while preserving task performance, with significant reductions in memory usage and GPU hours. Notably, our approach can recover the safety alignment of a fine-tuned 7B LLM on a single RTX 4090 within 40 minutes. Overall, our work provides a practical, turnkey solution for safety-aware deployment.
From Bits to Chips: An LLM-based Hardware-Aware Quantization Agent for Streamlined Deployment of LLMs
Jan 07, 2026Deploying models, especially large language models (LLMs), is becoming increasingly attractive to a broader user base, including those without specialized expertise. However, due to the resource constraints of certain hardware, maintaining high accuracy with larger model while meeting the hardware requirements remains a significant challenge. Model quantization technique helps mitigate memory and compute bottlenecks, yet the added complexities of tuning and deploying quantized models further exacerbates these challenges, making the process unfriendly to most of the users. We introduce the Hardware-Aware Quantization Agent (HAQA), an automated framework that leverages LLMs to streamline the entire quantization and deployment process by enabling efficient hyperparameter tuning and hardware configuration, thereby simultaneously improving deployment quality and ease of use for a broad range of users. Our results demonstrate up to a 2.3x speedup in inference, along with increased throughput and improved accuracy compared to unoptimized models on Llama. Additionally, HAQA is designed to implement adaptive quantization strategies across diverse hardware platforms, as it automatically finds optimal settings even when they appear counterintuitive, thereby reducing extensive manual effort and demonstrating superior adaptability. Code will be released.
Open-Source Multimodal Moxin Models with Moxin-VLM and Moxin-VLA
Dec 22, 2025Recently, Large Language Models (LLMs) have undergone a significant transformation, marked by a rapid rise in both their popularity and capabilities. Leading this evolution are proprietary LLMs like GPT-4 and GPT-o1, which have captured widespread attention in the AI community due to their remarkable performance and versatility. Simultaneously, open-source LLMs, such as LLaMA and Mistral, have made great contributions to the ever-increasing popularity of LLMs due to the ease to customize and deploy the models across diverse applications. Moxin 7B is introduced as a fully open-source LLM developed in accordance with the Model Openness Framework, which moves beyond the simple sharing of model weights to embrace complete transparency in training, datasets, and implementation detail, thus fostering a more inclusive and collaborative research environment that can sustain a healthy open-source ecosystem. To further equip Moxin with various capabilities in different tasks, we develop three variants based on Moxin, including Moxin-VLM, Moxin-VLA, and Moxin-Chinese, which target the vision-language, vision-language-action, and Chinese capabilities, respectively. Experiments show that our models achieve superior performance in various evaluations. We adopt open-source framework and open data for the training. We release our models, along with the available data and code to derive these models.
ZeroSim: Zero-Shot Analog Circuit Evaluation with Unified Transformer Embeddings
Nov 10, 2025Although recent advancements in learning-based analog circuit design automation have tackled tasks such as topology generation, device sizing, and layout synthesis, efficient performance evaluation remains a major bottleneck. Traditional SPICE simulations are time-consuming, while existing machine learning methods often require topology-specific retraining or manual substructure segmentation for fine-tuning, hindering scalability and adaptability. In this work, we propose ZeroSim, a transformer-based performance modeling framework designed to achieve robust in-distribution generalization across trained topologies under novel parameter configurations and zero-shot generalization to unseen topologies without any fine-tuning. We apply three key enabling strategies: (1) a diverse training corpus of 3.6 million instances covering over 60 amplifier topologies, (2) unified topology embeddings leveraging global-aware tokens and hierarchical attention to robustly generalize to novel circuits, and (3) a topology-conditioned parameter mapping approach that maintains consistent structural representations independent of parameter variations. Our experimental results demonstrate that ZeroSim significantly outperforms baseline models such as multilayer perceptrons, graph neural networks and transformers, delivering accurate zero-shot predictions across different amplifier topologies. Additionally, when integrated into a reinforcement learning-based parameter optimization pipeline, ZeroSim achieves a remarkable speedup (13x) compared to conventional SPICE simulations, underscoring its practical value for a wide range of analog circuit design automation tasks.
CircuitSense: A Hierarchical Circuit System Benchmark Bridging Visual Comprehension and Symbolic Reasoning in Engineering Design Process
Sep 26, 2025Engineering design operates through hierarchical abstraction from system specifications to component implementations, requiring visual understanding coupled with mathematical reasoning at each level. While Multi-modal Large Language Models (MLLMs) excel at natural image tasks, their ability to extract mathematical models from technical diagrams remains unexplored. We present \textbf{CircuitSense}, a comprehensive benchmark evaluating circuit understanding across this hierarchy through 8,006+ problems spanning component-level schematics to system-level block diagrams. Our benchmark uniquely examines the complete engineering workflow: Perception, Analysis, and Design, with a particular emphasis on the critical but underexplored capability of deriving symbolic equations from visual inputs. We introduce a hierarchical synthetic generation pipeline consisting of a grid-based schematic generator and a block diagram generator with auto-derived symbolic equation labels. Comprehensive evaluation of six state-of-the-art MLLMs, including both closed-source and open-source models, reveals fundamental limitations in visual-to-mathematical reasoning. Closed-source models achieve over 85\% accuracy on perception tasks involving component recognition and topology identification, yet their performance on symbolic derivation and analytical reasoning falls below 19\%, exposing a critical gap between visual parsing and symbolic reasoning. Models with stronger symbolic reasoning capabilities consistently achieve higher design task accuracy, confirming the fundamental role of mathematical understanding in circuit synthesis and establishing symbolic reasoning as the key metric for engineering competence.
TSLA: A Task-Specific Learning Adaptation for Semantic Segmentation on Autonomous Vehicles Platform
Aug 17, 2025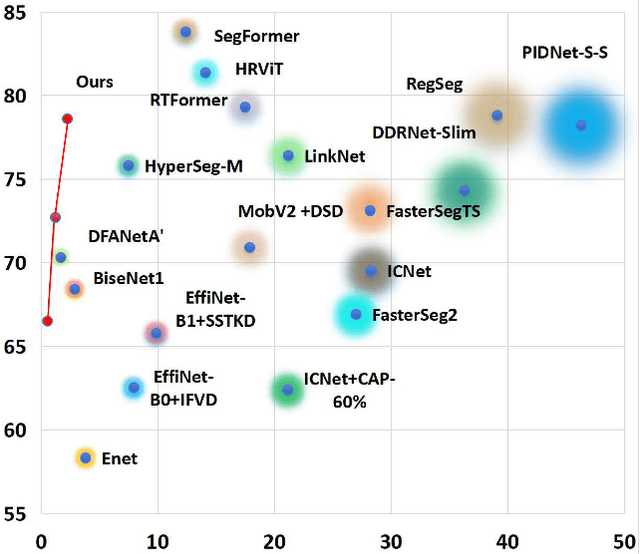
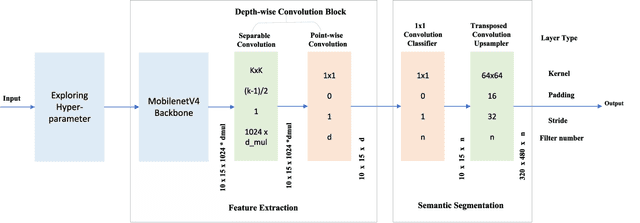
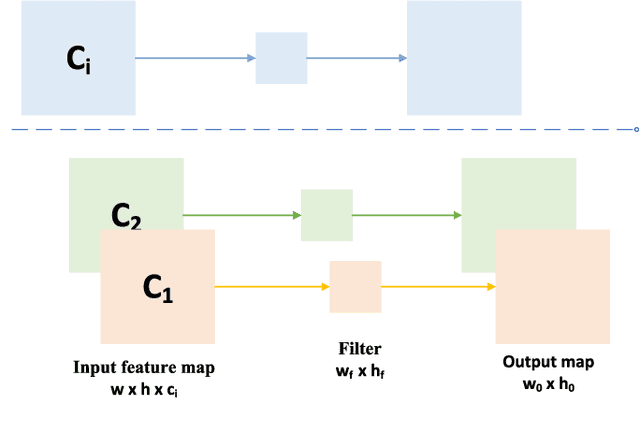
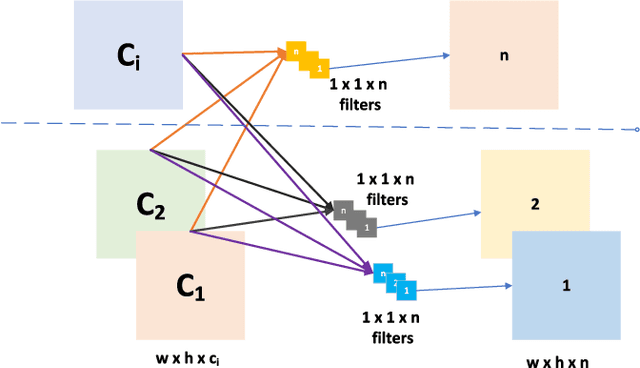
Autonomous driving platforms encounter diverse driving scenarios, each with varying hardware resources and precision requirements. Given the computational limitations of embedded devices, it is crucial to consider computing costs when deploying on target platforms like the NVIDIA\textsuperscript{\textregistered} DRIVE PX 2. Our objective is to customize the semantic segmentation network according to the computing power and specific scenarios of autonomous driving hardware. We implement dynamic adaptability through a three-tier control mechanism -- width multiplier, classifier depth, and classifier kernel -- allowing fine-grained control over model components based on hardware constraints and task requirements. This adaptability facilitates broad model scaling, targeted refinement of the final layers, and scenario-specific optimization of kernel sizes, leading to improved resource allocation and performance. Additionally, we leverage Bayesian Optimization with surrogate modeling to efficiently explore hyperparameter spaces under tight computational budgets. Our approach addresses scenario-specific and task-specific requirements through automatic parameter search, accommodating the unique computational complexity and accuracy needs of autonomous driving. It scales its Multiply-Accumulate Operations (MACs) for Task-Specific Learning Adaptation (TSLA), resulting in alternative configurations tailored to diverse self-driving tasks. These TSLA customizations maximize computational capacity and model accuracy, optimizing hardware utilization.