 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRCR-Router: Efficient Role-Aware Context Routing for Multi-Agent LLM Systems with Structured Memory
Aug 06, 2025Multi-agent large language model (LLM) systems have shown strong potential in complex reasoning and collaborative decision-making tasks. However, most existing coordination schemes rely on static or full-context routing strategies, which lead to excessive token consumption, redundant memory exposure, and limited adaptability across interaction rounds. We introduce RCR-Router, a modular and role-aware context routing framework designed to enable efficient, adaptive collaboration in multi-agent LLMs. To our knowledge, this is the first routing approach that dynamically selects semantically relevant memory subsets for each agent based on its role and task stage, while adhering to a strict token budget. A lightweight scoring policy guides memory selection, and agent outputs are iteratively integrated into a shared memory store to facilitate progressive context refinement. To better evaluate model behavior, we further propose an Answer Quality Score metric that captures LLM-generated explanations beyond standard QA accuracy. Experiments on three multi-hop QA benchmarks -- HotPotQA, MuSiQue, and 2WikiMultihop -- demonstrate that RCR-Router reduces token usage (up to 30%) while improving or maintaining answer quality. These results highlight the importance of structured memory routing and output-aware evaluation in advancing scalable multi-agent LLM systems.
Large Scalable Cross-Domain Graph Neural Networks for Personalized Notification at LinkedIn
Jun 15, 2025



Notification recommendation systems are critical to driving user engagement on professional platforms like LinkedIn. Designing such systems involves integrating heterogeneous signals across domains, capturing temporal dynamics, and optimizing for multiple, often competing, objectives. Graph Neural Networks (GNNs) provide a powerful framework for modeling complex interactions in such environments. In this paper, we present a cross-domain GNN-based system deployed at LinkedIn that unifies user, content, and activity signals into a single, large-scale graph. By training on this cross-domain structure, our model significantly outperforms single-domain baselines on key tasks, including click-through rate (CTR) prediction and professional engagement. We introduce architectural innovations including temporal modeling and multi-task learning, which further enhance performance. Deployed in LinkedIn's notification system, our approach led to a 0.10% lift in weekly active users and a 0.62% improvement in CTR. We detail our graph construction process, model design, training pipeline, and both offline and online evaluations. Our work demonstrates the scalability and effectiveness of cross-domain GNNs in real-world, high-impact applications.
Structured Agent Distillation for Large Language Model
May 20, 2025



Large language models (LLMs) exhibit strong capabilities as decision-making agents by interleaving reasoning and actions, as seen in ReAct-style frameworks. Yet, their practical deployment is constrained by high inference costs and large model sizes. We propose Structured Agent Distillation, a framework that compresses large LLM-based agents into smaller student models while preserving both reasoning fidelity and action consistency. Unlike standard token-level distillation, our method segments trajectories into {[REASON]} and {[ACT]} spans, applying segment-specific losses to align each component with the teacher's behavior. This structure-aware supervision enables compact agents to better replicate the teacher's decision process. Experiments on ALFWorld, HotPotQA-ReAct, and WebShop show that our approach consistently outperforms token-level and imitation learning baselines, achieving significant compression with minimal performance drop. Scaling and ablation results further highlight the importance of span-level alignment for efficient and deployable agents.
LokiTalk: Learning Fine-Grained and Generalizable Correspondences to Enhance NeRF-based Talking Head Synthesis
Nov 29, 2024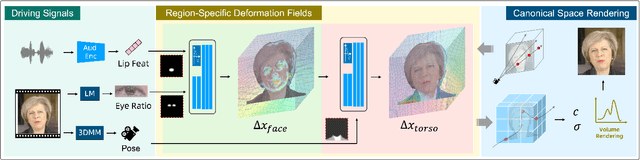
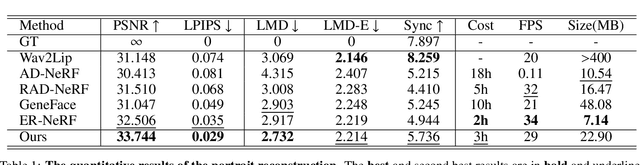
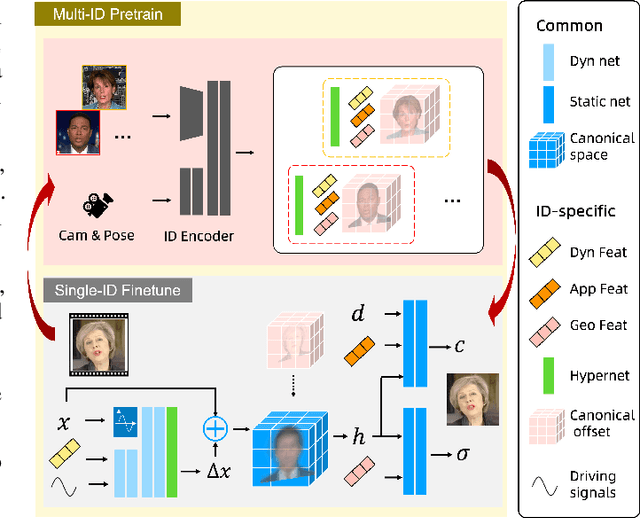

Despite significant progress in talking head synthesis since the introduction of Neural Radiance Fields (NeRF), visual artifacts and high training costs persist as major obstacles to large-scale commercial adoption. We propose that identifying and establishing fine-grained and generalizable correspondences between driving signals and generated results can simultaneously resolve both problems. Here we present LokiTalk, a novel framework designed to enhance NeRF-based talking heads with lifelike facial dynamics and improved training efficiency. To achieve fine-grained correspondences, we introduce Region-Specific Deformation Fields, which decompose the overall portrait motion into lip movements, eye blinking, head pose, and torso movements. By hierarchically modeling the driving signals and their associated regions through two cascaded deformation fields, we significantly improve dynamic accuracy and minimize synthetic artifacts. Furthermore, we propose ID-Aware Knowledge Transfer, a plug-and-play module that learns generalizable dynamic and static correspondences from multi-identity videos, while simultaneously extracting ID-specific dynamic and static features to refine the depiction of individual characters. Comprehensive evaluations demonstrate that LokiTalk delivers superior high-fidelity results and training efficiency compared to previous methods. The code will be released upon acceptance.
Ditto: Motion-Space Diffusion for Controllable Realtime Talking Head Synthesis
Nov 29, 2024Recent advances in diffusion models have revolutionized audio-driven talking head synthesis. Beyond precise lip synchronization, diffusion-based methods excel in generating subtle expressions and natural head movements that are well-aligned with the audio signal. However, these methods are confronted by slow inference speed, insufficient fine-grained control over facial motions, and occasional visual artifacts largely due to an implicit latent space derived from Variational Auto-Encoders (VAE), which prevent their adoption in realtime interaction applications. To address these issues, we introduce Ditto, a diffusion-based framework that enables controllable realtime talking head synthesis. Our key innovation lies in bridging motion generation and photorealistic neural rendering through an explicit identity-agnostic motion space, replacing conventional VAE representations. This design substantially reduces the complexity of diffusion learning while enabling precise control over the synthesized talking heads. We further propose an inference strategy that jointly optimizes three key components: audio feature extraction, motion generation, and video synthesis. This optimization enables streaming processing, realtime inference, and low first-frame delay, which are the functionalities crucial for interactive applications such as AI assistants. Extensive experimental results demonstrate that Ditto generates compelling talking head videos and substantially outperforms existing methods in both motion control and realtime performance.
Learning Transferable Negative Prompts for Out-of-Distribution Detection
Apr 04, 2024Existing prompt learning methods have shown certain capabilities in Out-of-Distribution (OOD) detection, but the lack of OOD images in the target dataset in their training can lead to mismatches between OOD images and In-Distribution (ID) categories, resulting in a high false positive rate. To address this issue, we introduce a novel OOD detection method, named 'NegPrompt', to learn a set of negative prompts, each representing a negative connotation of a given class label, for delineating the boundaries between ID and OOD images. It learns such negative prompts with ID data only, without any reliance on external outlier data. Further, current methods assume the availability of samples of all ID classes, rendering them ineffective in open-vocabulary learning scenarios where the inference stage can contain novel ID classes not present during training. In contrast, our learned negative prompts are transferable to novel class labels. Experiments on various ImageNet benchmarks show that NegPrompt surpasses state-of-the-art prompt-learning-based OOD detection methods and maintains a consistent lead in hard OOD detection in closed- and open-vocabulary classification scenarios. Code is available at https://github.com/mala-lab/negprompt.
Learning Dynamic Tetrahedra for High-Quality Talking Head Synthesis
Feb 27, 2024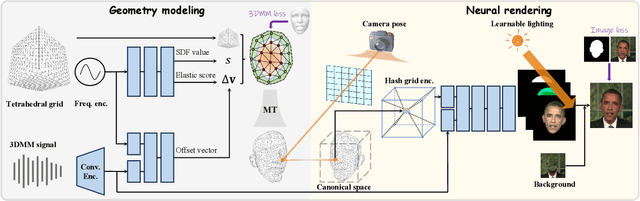
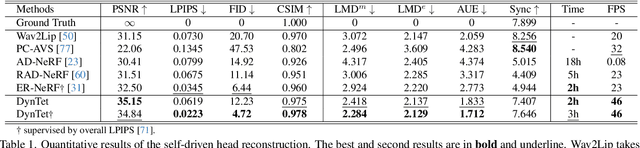

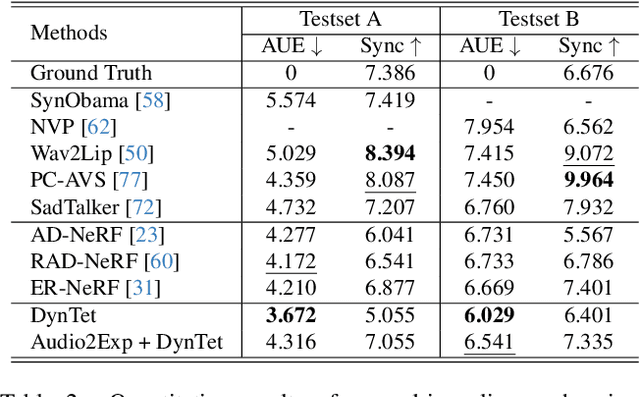
Recent works in implicit representations, such as Neural Radiance Fields (NeRF), have advanced the generation of realistic and animatable head avatars from video sequences. These implicit methods are still confronted by visual artifacts and jitters, since the lack of explicit geometric constraints poses a fundamental challenge in accurately modeling complex facial deformations. In this paper, we introduce Dynamic Tetrahedra (DynTet), a novel hybrid representation that encodes explicit dynamic meshes by neural networks to ensure geometric consistency across various motions and viewpoints. DynTet is parameterized by the coordinate-based networks which learn signed distance, deformation, and material texture, anchoring the training data into a predefined tetrahedra grid. Leveraging Marching Tetrahedra, DynTet efficiently decodes textured meshes with a consistent topology, enabling fast rendering through a differentiable rasterizer and supervision via a pixel loss. To enhance training efficiency, we incorporate classical 3D Morphable Models to facilitate geometry learning and define a canonical space for simplifying texture learning. These advantages are readily achievable owing to the effective geometric representation employed in DynTet. Compared with prior works, DynTet demonstrates significant improvements in fidelity, lip synchronization, and real-time performance according to various metrics. Beyond producing stable and visually appealing synthesis videos, our method also outputs the dynamic meshes which is promising to enable many emerging applications.
Out-of-Distribution Detection in Long-Tailed Recognition with Calibrated Outlier Class Learning
Dec 19, 2023Existing out-of-distribution (OOD) methods have shown great success on balanced datasets but become ineffective in long-tailed recognition (LTR) scenarios where 1) OOD samples are often wrongly classified into head classes and/or 2) tail-class samples are treated as OOD samples. To address these issues, current studies fit a prior distribution of auxiliary/pseudo OOD data to the long-tailed in-distribution (ID) data. However, it is difficult to obtain such an accurate prior distribution given the unknowingness of real OOD samples and heavy class imbalance in LTR. A straightforward solution to avoid the requirement of this prior is to learn an outlier class to encapsulate the OOD samples. The main challenge is then to tackle the aforementioned confusion between OOD samples and head/tail-class samples when learning the outlier class. To this end, we introduce a novel calibrated outlier class learning (COCL) approach, in which 1) a debiased large margin learning method is introduced in the outlier class learning to distinguish OOD samples from both head and tail classes in the representation space and 2) an outlier-class-aware logit calibration method is defined to enhance the long-tailed classification confidence. Extensive empirical results on three popular benchmarks CIFAR10-LT, CIFAR100-LT, and ImageNet-LT demonstrate that COCL substantially outperforms state-of-the-art OOD detection methods in LTR while being able to improve the classification accuracy on ID data. Code is available at https://github.com/mala-lab/COCL.
Learning Adversarial Semantic Embeddings for Zero-Shot Recognition in Open Worlds
Jul 07, 2023Zero-Shot Learning (ZSL) focuses on classifying samples of unseen classes with only their side semantic information presented during training. It cannot handle real-life, open-world scenarios where there are test samples of unknown classes for which neither samples (e.g., images) nor their side semantic information is known during training. Open-Set Recognition (OSR) is dedicated to addressing the unknown class issue, but existing OSR methods are not designed to model the semantic information of the unseen classes. To tackle this combined ZSL and OSR problem, we consider the case of "Zero-Shot Open-Set Recognition" (ZS-OSR), where a model is trained under the ZSL setting but it is required to accurately classify samples from the unseen classes while being able to reject samples from the unknown classes during inference. We perform large experiments on combining existing state-of-the-art ZSL and OSR models for the ZS-OSR task on four widely used datasets adapted from the ZSL task, and reveal that ZS-OSR is a non-trivial task as the simply combined solutions perform badly in distinguishing the unseen-class and unknown-class samples. We further introduce a novel approach specifically designed for ZS-OSR, in which our model learns to generate adversarial semantic embeddings of the unknown classes to train an unknowns-informed ZS-OSR classifier. Extensive empirical results show that our method 1) substantially outperforms the combined solutions in detecting the unknown classes while retaining the classification accuracy on the unseen classes and 2) achieves similar superiority under generalized ZS-OSR settings.
Emergent Cooperative Behavior in Distributed Target Tracking with Unknown Occlusions
Apr 21, 2023



Tracking multiple moving objects of interest (OOI) with multiple robot systems (MRS) has been addressed by active sensing that maintains a shared belief of OOIs and plans the motion of robots to maximize the information quality. Mobility of robots enables the behavior of pursuing better visibility, which is constrained by sensor field of view (FoV) and occlusion objects. We first extend prior work to detect, maintain and share occlusion information explicitly, allowing us to generate occlusion-aware planning even if a priori semantic occlusion information is unavailable. The efficacy of active sensing approaches is often evaluated according to estimation error and information gain metrics. However, these metrics do not directly explain the level of cooperative behavior engendered by the active sensing algorithms. Next, we extract different emergent cooperative behaviors that stem from the same underlying algorithms but manifest differently under differing scenarios. In particular, we highlight and demonstrate three emergent behavior patterns in active sensing MRS: (i) Change of tracking responsibility between agents when tracking trajectories with divergent directions or due to a re-allocation of the resource among heterogeneous agents; (ii) Awareness of occlusions to a trajectory and temporal leave-and-return of the sensing agent; (iii) Sharing of local occlusion objects in MRS that subsequently improves the awareness of occlusion.