 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViThinker: Active Vision-Language Reasoning via Dynamic Perceptual Querying
Feb 02, 2026Chain-of-Thought (CoT) reasoning excels in language models but struggles in vision-language models due to premature visual-to-text conversion that discards continuous information such as geometry and spatial layout. While recent methods enhance CoT through static enumeration or attention-based selection, they remain passive, i.e., processing pre-computed inputs rather than actively seeking task-relevant details. Inspired by human active perception, we introduce ViThinker, a framework that enables vision-language models to autonomously generate decision (query) tokens triggering the synthesis of expert-aligned visual features on demand. ViThinker internalizes vision-expert capabilities during training, performing generative mental simulation during inference without external tool calls. Through a two-stage curriculum: first distilling frozen experts into model parameters, then learning task-driven querying via sparsity penalties, i.e., ViThinker discovers minimal sufficient perception for each reasoning step. Evaluations across vision-centric benchmarks demonstrate consistent improvements, validating that active query generation outperforms passive approaches in both perceptual grounding and reasoning accuracy.
Q-realign: Piggybacking Realignment on Quantization for Safe and Efficient LLM Deployment
Jan 13, 2026Public large language models (LLMs) are typically safety-aligned during pretraining, yet task-specific fine-tuning required for deployment often erodes this alignment and introduces safety risks. Existing defenses either embed safety recovery into fine-tuning or rely on fine-tuning-derived priors for post-hoc correction, leaving safety recovery tightly coupled with training and incurring high computational overhead and a complex workflow. To address these challenges, we propose \texttt{Q-realign}, a post-hoc defense method based on post-training quantization, guided by an analysis of representational structure. By reframing quantization as a dual-objective procedure for compression and safety, \texttt{Q-realign} decouples safety alignment from fine-tuning and naturally piggybacks into modern deployment pipelines. Experiments across multiple models and datasets demonstrate that our method substantially reduces unsafe behaviors while preserving task performance, with significant reductions in memory usage and GPU hours. Notably, our approach can recover the safety alignment of a fine-tuned 7B LLM on a single RTX 4090 within 40 minutes. Overall, our work provides a practical, turnkey solution for safety-aware deployment.
From Bits to Chips: An LLM-based Hardware-Aware Quantization Agent for Streamlined Deployment of LLMs
Jan 07, 2026Deploying models, especially large language models (LLMs), is becoming increasingly attractive to a broader user base, including those without specialized expertise. However, due to the resource constraints of certain hardware, maintaining high accuracy with larger model while meeting the hardware requirements remains a significant challenge. Model quantization technique helps mitigate memory and compute bottlenecks, yet the added complexities of tuning and deploying quantized models further exacerbates these challenges, making the process unfriendly to most of the users. We introduce the Hardware-Aware Quantization Agent (HAQA), an automated framework that leverages LLMs to streamline the entire quantization and deployment process by enabling efficient hyperparameter tuning and hardware configuration, thereby simultaneously improving deployment quality and ease of use for a broad range of users. Our results demonstrate up to a 2.3x speedup in inference, along with increased throughput and improved accuracy compared to unoptimized models on Llama. Additionally, HAQA is designed to implement adaptive quantization strategies across diverse hardware platforms, as it automatically finds optimal settings even when they appear counterintuitive, thereby reducing extensive manual effort and demonstrating superior adaptability. Code will be released.
Rethinking the Potential of Layer Freezing for Efficient DNN Training
Aug 20, 2025With the growing size of deep neural networks and datasets, the computational costs of training have significantly increased. The layer-freezing technique has recently attracted great attention as a promising method to effectively reduce the cost of network training. However, in traditional layer-freezing methods, frozen layers are still required for forward propagation to generate feature maps for unfrozen layers, limiting the reduction of computation costs. To overcome this, prior works proposed a hypothetical solution, which caches feature maps from frozen layers as a new dataset, allowing later layers to train directly on stored feature maps. While this approach appears to be straightforward, it presents several major challenges that are severely overlooked by prior literature, such as how to effectively apply augmentations to feature maps and the substantial storage overhead introduced. If these overlooked challenges are not addressed, the performance of the caching method will be severely impacted and even make it infeasible. This paper is the first to comprehensively explore these challenges and provides a systematic solution. To improve training accuracy, we propose \textit{similarity-aware channel augmentation}, which caches channels with high augmentation sensitivity with a minimum additional storage cost. To mitigate storage overhead, we incorporate lossy data compression into layer freezing and design a \textit{progressive compression} strategy, which increases compression rates as more layers are frozen, effectively reducing storage costs. Finally, our solution achieves significant reductions in training cost while maintaining model accuracy, with a minor time overhead. Additionally, we conduct a comprehensive evaluation of freezing and compression strategies, providing insights into optimizing their application for efficient DNN training.
TSLA: A Task-Specific Learning Adaptation for Semantic Segmentation on Autonomous Vehicles Platform
Aug 17, 2025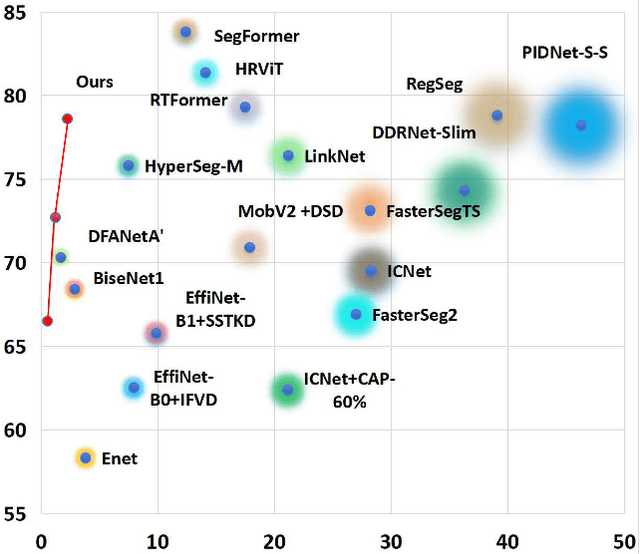
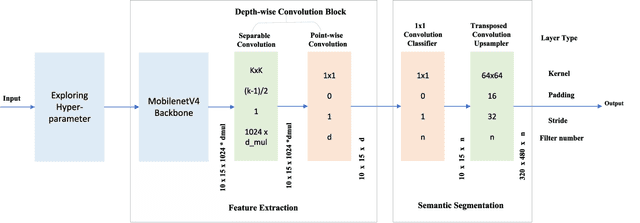
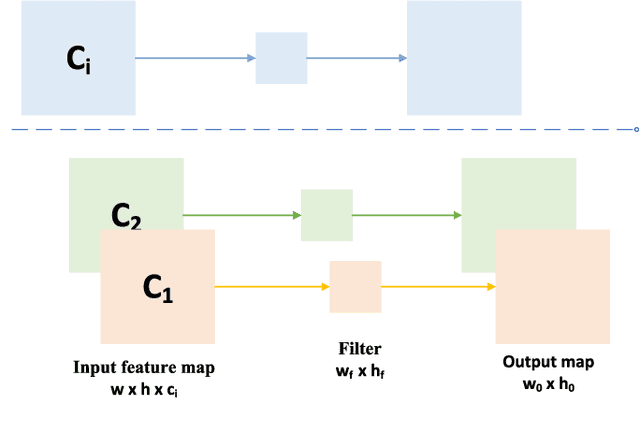
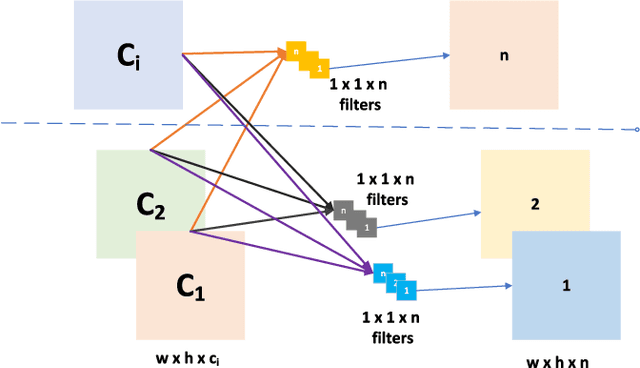
Autonomous driving platforms encounter diverse driving scenarios, each with varying hardware resources and precision requirements. Given the computational limitations of embedded devices, it is crucial to consider computing costs when deploying on target platforms like the NVIDIA\textsuperscript{\textregistered} DRIVE PX 2. Our objective is to customize the semantic segmentation network according to the computing power and specific scenarios of autonomous driving hardware. We implement dynamic adaptability through a three-tier control mechanism -- width multiplier, classifier depth, and classifier kernel -- allowing fine-grained control over model components based on hardware constraints and task requirements. This adaptability facilitates broad model scaling, targeted refinement of the final layers, and scenario-specific optimization of kernel sizes, leading to improved resource allocation and performance. Additionally, we leverage Bayesian Optimization with surrogate modeling to efficiently explore hyperparameter spaces under tight computational budgets. Our approach addresses scenario-specific and task-specific requirements through automatic parameter search, accommodating the unique computational complexity and accuracy needs of autonomous driving. It scales its Multiply-Accumulate Operations (MACs) for Task-Specific Learning Adaptation (TSLA), resulting in alternative configurations tailored to diverse self-driving tasks. These TSLA customizations maximize computational capacity and model accuracy, optimizing hardware utilization.
RCR-Router: Efficient Role-Aware Context Routing for Multi-Agent LLM Systems with Structured Memory
Aug 06, 2025Multi-agent large language model (LLM) systems have shown strong potential in complex reasoning and collaborative decision-making tasks. However, most existing coordination schemes rely on static or full-context routing strategies, which lead to excessive token consumption, redundant memory exposure, and limited adaptability across interaction rounds. We introduce RCR-Router, a modular and role-aware context routing framework designed to enable efficient, adaptive collaboration in multi-agent LLMs. To our knowledge, this is the first routing approach that dynamically selects semantically relevant memory subsets for each agent based on its role and task stage, while adhering to a strict token budget. A lightweight scoring policy guides memory selection, and agent outputs are iteratively integrated into a shared memory store to facilitate progressive context refinement. To better evaluate model behavior, we further propose an Answer Quality Score metric that captures LLM-generated explanations beyond standard QA accuracy. Experiments on three multi-hop QA benchmarks -- HotPotQA, MuSiQue, and 2WikiMultihop -- demonstrate that RCR-Router reduces token usage (up to 30%) while improving or maintaining answer quality. These results highlight the importance of structured memory routing and output-aware evaluation in advancing scalable multi-agent LLM systems.
ACE: Exploring Activation Cosine Similarity and Variance for Accurate and Calibration-Efficient LLM Pruning
May 28, 2025



With the rapid expansion of large language models (LLMs), the demand for memory and computational resources has grown significantly. Recent advances in LLM pruning aim to reduce the size and computational cost of these models. However, existing methods often suffer from either suboptimal pruning performance or low time efficiency during the pruning process. In this work, we propose an efficient and effective pruning method that simultaneously achieves high pruning performance and fast pruning speed with improved calibration efficiency. Our approach introduces two key innovations: (1) An activation cosine similarity loss-guided pruning metric, which considers the angular deviation of the output activation between the dense and pruned models. (2) An activation variance-guided pruning metric, which helps preserve semantic distinctions in output activations after pruning, enabling effective pruning with shorter input sequences. These two components can be readily combined to enhance LLM pruning in both accuracy and efficiency. Experimental results show that our method achieves up to an 18% reduction in perplexity and up to 63% decrease in pruning time on prevalent LLMs such as LLaMA, LLaMA-2, and OPT.
KerZOO: Kernel Function Informed Zeroth-Order Optimization for Accurate and Accelerated LLM Fine-Tuning
May 24, 2025Large language models (LLMs) have demonstrated impressive capabilities across numerous NLP tasks. Nevertheless, conventional first-order fine-tuning techniques impose heavy memory demands, creating practical obstacles to real-world applications. Zeroth-order (ZO) optimization has recently emerged as a promising memory-efficient alternative, as it circumvents the need for backpropagation by estimating gradients solely through forward passes--making it particularly suitable for resource-limited environments. Despite its efficiency, ZO optimization suffers from gradient estimation bias, which significantly hinders convergence speed. To address this, we analytically identify and characterize the lower-order bias introduced during ZO-based gradient estimation in LLM fine-tuning. Motivated by tools in mathematical physics, we introduce a kernel-function-based ZO framework aimed at mitigating this bias and improving optimization stability. KerZOO achieves comparable or superior performance to existing ZO baselines in both full-parameter and parameter-efficient fine-tuning settings of LLMs, while significantly reducing the number of iterations required to reach convergence. For example, KerZOO reduces total GPU training hours by as much as 74% and 44% on WSC and MultiRC datasets in fine-tuning OPT-2.7B model and can exceed the MeZO baseline by 2.9% and 2.6% in accuracy. We show that the kernel function is an effective avenue for reducing estimation bias in ZO methods.
Structured Agent Distillation for Large Language Model
May 20, 2025



Large language models (LLMs) exhibit strong capabilities as decision-making agents by interleaving reasoning and actions, as seen in ReAct-style frameworks. Yet, their practical deployment is constrained by high inference costs and large model sizes. We propose Structured Agent Distillation, a framework that compresses large LLM-based agents into smaller student models while preserving both reasoning fidelity and action consistency. Unlike standard token-level distillation, our method segments trajectories into {[REASON]} and {[ACT]} spans, applying segment-specific losses to align each component with the teacher's behavior. This structure-aware supervision enables compact agents to better replicate the teacher's decision process. Experiments on ALFWorld, HotPotQA-ReAct, and WebShop show that our approach consistently outperforms token-level and imitation learning baselines, achieving significant compression with minimal performance drop. Scaling and ablation results further highlight the importance of span-level alignment for efficient and deployable agents.
Perturbation-efficient Zeroth-order Optimization for Hardware-friendly On-device Training
Apr 28, 2025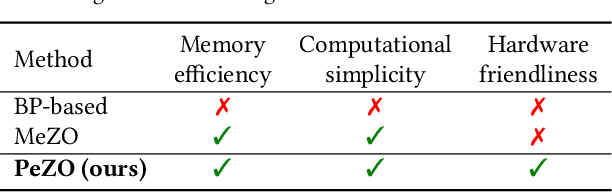
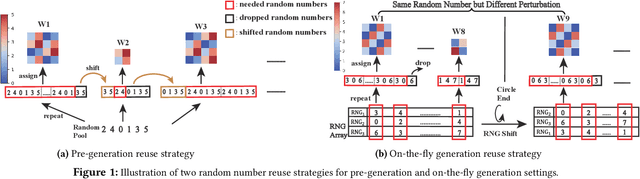
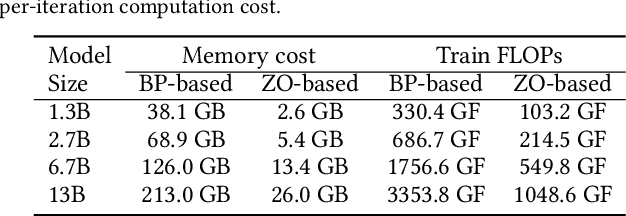
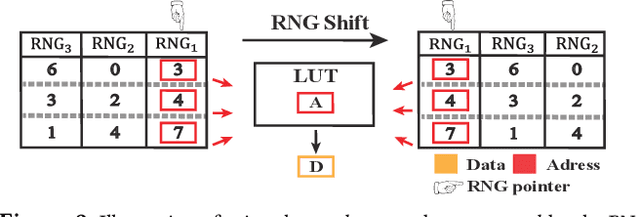
Zeroth-order (ZO) optimization is an emerging deep neural network (DNN) training paradigm that offers computational simplicity and memory savings. However, this seemingly promising approach faces a significant and long-ignored challenge. ZO requires generating a substantial number of Gaussian random numbers, which poses significant difficulties and even makes it infeasible for hardware platforms, such as FPGAs and ASICs. In this paper, we identify this critical issue, which arises from the mismatch between algorithm and hardware designers. To address this issue, we proposed PeZO, a perturbation-efficient ZO framework. Specifically, we design random number reuse strategies to significantly reduce the demand for random number generation and introduce a hardware-friendly adaptive scaling method to replace the costly Gaussian distribution with a uniform distribution. Our experiments show that PeZO reduces the required LUTs and FFs for random number generation by 48.6\% and 12.7\%, and saves at maximum 86\% power consumption, all without compromising training performance, making ZO optimization feasible for on-device training. To the best of our knowledge, we are the first to explore the potential of on-device ZO optimization, providing valuable insights for future research.