 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdgeOL: Efficient in-situ Online Learning on Edge Devices
Jan 30, 2024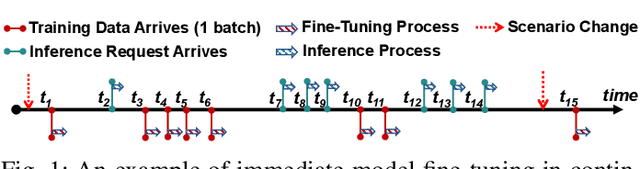
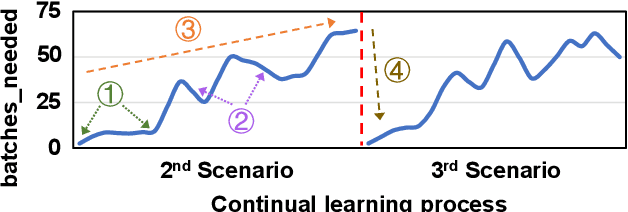
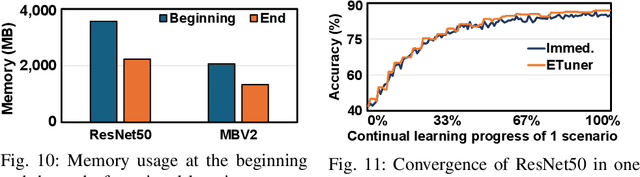
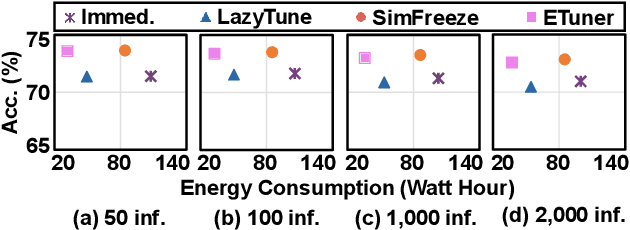
Emerging applications, such as robot-assisted eldercare and object recognition, generally employ deep learning neural networks (DNNs) models and naturally require: i) handling streaming-in inference requests and ii) adapting to possible deployment scenario changes. Online model fine-tuning is widely adopted to satisfy these needs. However, fine-tuning involves significant energy consumption, making it challenging to deploy on edge devices. In this paper, we propose EdgeOL, an edge online learning framework that optimizes inference accuracy, fine-tuning execution time, and energy efficiency through both inter-tuning and intra-tuning optimizations. Experimental results show that, on average, EdgeOL reduces overall fine-tuning execution time by 82%, energy consumption by 74%, and improves average inference accuracy by 1.70% over the immediate online learning strategy.
Sustainable AI Processing at the Edge
Jul 04, 2022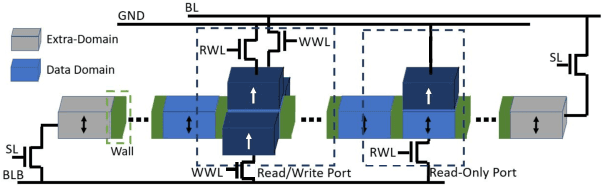
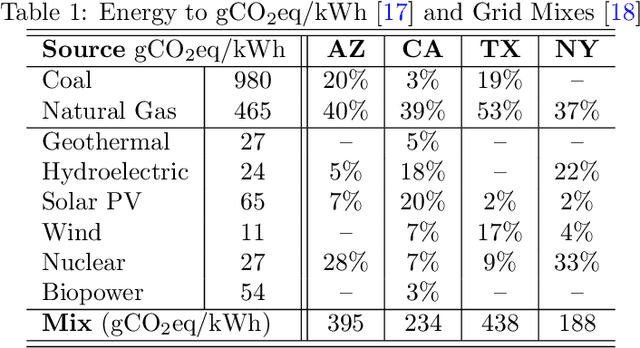
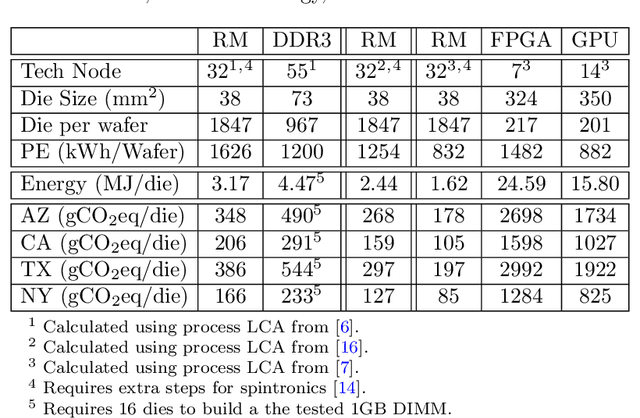
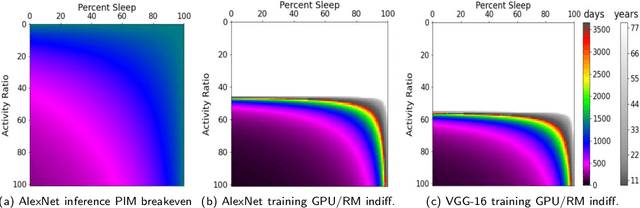
Edge computing is a popular target for accelerating machine learning algorithms supporting mobile devices without requiring the communication latencies to handle them in the cloud. Edge deployments of machine learning primarily consider traditional concerns such as SWaP constraints (Size, Weight, and Power) for their installations. However, such metrics are not entirely sufficient to consider environmental impacts from computing given the significant contributions from embodied energy and carbon. In this paper we explore the tradeoffs of convolutional neural network acceleration engines for both inference and on-line training. In particular, we explore the use of processing-in-memory (PIM) approaches, mobile GPU accelerators, and recently released FPGAs, and compare them with novel Racetrack memory PIM. Replacing PIM-enabled DDR3 with Racetrack memory PIM can recover its embodied energy as quickly as 1 year. For high activity ratios, mobile GPUs can be more sustainable but have higher embodied energy to overcome compared to PIM-enabled Racetrack memory.
Brain-inspired Cognition in Next Generation Racetrack Memories
Nov 03, 2021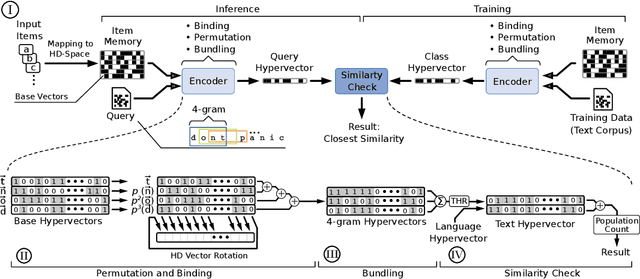
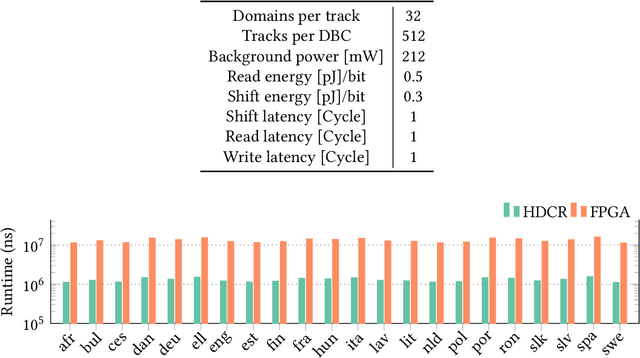
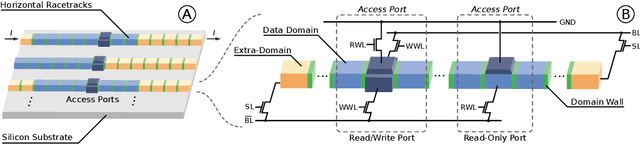
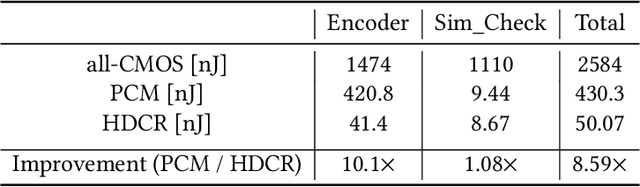
Hyperdimensional computing (HDC) is an emerging computational framework inspired by the brain that operates on vectors with thousands of dimensions to emulate cognition. Unlike conventional computational frameworks that operate on numbers, HDC, like the brain, uses high dimensional random vectors and is capable of one-shot learning. HDC is based on a well-defined set of arithmetic operations and is highly error-resilient. The core operations of HDC manipulate HD vectors in bulk bit-wise fashion, offering many opportunities to leverage parallelism. Unfortunately, on conventional Von-Neuman architectures, the continuous movement of HD vectors among the processor and the memory can make the cognition task prohibitively slow and energy-intensive. Hardware accelerators only marginally improve related metrics. On the contrary, only partial implementation of an HDC framework inside memory, using emerging memristive devices, has reported considerable performance/energy gains. This paper presents an architecture based on racetrack memory (RTM) to conduct and accelerate the entire HDC framework within the memory. The proposed solution requires minimal additional CMOS circuitry and uses a read operation across multiple domains in RTMs called transverse read (TR) to realize exclusive-or (XOR) and addition operations. To minimize the overhead the CMOS circuitry, we propose an RTM nanowires-based counting mechanism that leverages the TR operation and the standard RTM operations. Using language recognition as the use case demonstrates 7.8x and 5.3x reduction in the overall runtime and energy consumption compared to the FPGA design, respectively. Compared to the state-of-the-art in-memory implementation, the proposed HDC system reduces the energy consumption by 8.6x.