 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMACE-Dance: Motion-Appearance Cascaded Experts for Music-Driven Dance Video Generation
Dec 20, 2025


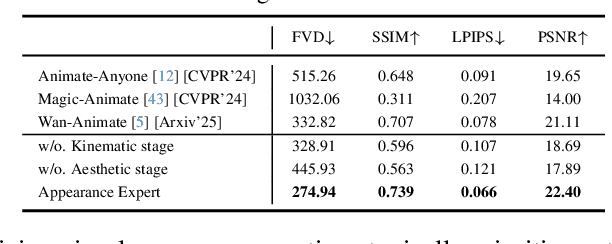
With the rise of online dance-video platforms and rapid advances in AI-generated content (AIGC), music-driven dance generation has emerged as a compelling research direction. Despite substantial progress in related domains such as music-driven 3D dance generation, pose-driven image animation, and audio-driven talking-head synthesis, existing methods cannot be directly adapted to this task. Moreover, the limited studies in this area still struggle to jointly achieve high-quality visual appearance and realistic human motion. Accordingly, we present MACE-Dance, a music-driven dance video generation framework with cascaded Mixture-of-Experts (MoE). The Motion Expert performs music-to-3D motion generation while enforcing kinematic plausibility and artistic expressiveness, whereas the Appearance Expert carries out motion- and reference-conditioned video synthesis, preserving visual identity with spatiotemporal coherence. Specifically, the Motion Expert adopts a diffusion model with a BiMamba-Transformer hybrid architecture and a Guidance-Free Training (GFT) strategy, achieving state-of-the-art (SOTA) performance in 3D dance generation. The Appearance Expert employs a decoupled kinematic-aesthetic fine-tuning strategy, achieving state-of-the-art (SOTA) performance in pose-driven image animation. To better benchmark this task, we curate a large-scale and diverse dataset and design a motion-appearance evaluation protocol. Based on this protocol, MACE-Dance also achieves state-of-the-art performance. Project page: https://macedance.github.io/
Rethinking the Potential of Layer Freezing for Efficient DNN Training
Aug 20, 2025With the growing size of deep neural networks and datasets, the computational costs of training have significantly increased. The layer-freezing technique has recently attracted great attention as a promising method to effectively reduce the cost of network training. However, in traditional layer-freezing methods, frozen layers are still required for forward propagation to generate feature maps for unfrozen layers, limiting the reduction of computation costs. To overcome this, prior works proposed a hypothetical solution, which caches feature maps from frozen layers as a new dataset, allowing later layers to train directly on stored feature maps. While this approach appears to be straightforward, it presents several major challenges that are severely overlooked by prior literature, such as how to effectively apply augmentations to feature maps and the substantial storage overhead introduced. If these overlooked challenges are not addressed, the performance of the caching method will be severely impacted and even make it infeasible. This paper is the first to comprehensively explore these challenges and provides a systematic solution. To improve training accuracy, we propose \textit{similarity-aware channel augmentation}, which caches channels with high augmentation sensitivity with a minimum additional storage cost. To mitigate storage overhead, we incorporate lossy data compression into layer freezing and design a \textit{progressive compression} strategy, which increases compression rates as more layers are frozen, effectively reducing storage costs. Finally, our solution achieves significant reductions in training cost while maintaining model accuracy, with a minor time overhead. Additionally, we conduct a comprehensive evaluation of freezing and compression strategies, providing insights into optimizing their application for efficient DNN training.
MEGADance: Mixture-of-Experts Architecture for Genre-Aware 3D Dance Generation
May 23, 2025



Music-driven 3D dance generation has attracted increasing attention in recent years, with promising applications in choreography, virtual reality, and creative content creation. Previous research has generated promising realistic dance movement from audio signals. However, traditional methods underutilize genre conditioning, often treating it as auxiliary modifiers rather than core semantic drivers. This oversight compromises music-motion synchronization and disrupts dance genre continuity, particularly during complex rhythmic transitions, thereby leading to visually unsatisfactory effects. To address the challenge, we propose MEGADance, a novel architecture for music-driven 3D dance generation. By decoupling choreographic consistency into dance generality and genre specificity, MEGADance demonstrates significant dance quality and strong genre controllability. It consists of two stages: (1) High-Fidelity Dance Quantization Stage (HFDQ), which encodes dance motions into a latent representation by Finite Scalar Quantization (FSQ) and reconstructs them with kinematic-dynamic constraints, and (2) Genre-Aware Dance Generation Stage (GADG), which maps music into the latent representation by synergistic utilization of Mixture-of-Experts (MoE) mechanism with Mamba-Transformer hybrid backbone. Extensive experiments on the FineDance and AIST++ dataset demonstrate the state-of-the-art performance of MEGADance both qualitatively and quantitatively. Code will be released upon acceptance.
MatchDance: Collaborative Mamba-Transformer Architecture Matching for High-Quality 3D Dance Synthesis
May 21, 2025Music-to-dance generation represents a challenging yet pivotal task at the intersection of choreography, virtual reality, and creative content generation. Despite its significance, existing methods face substantial limitation in achieving choreographic consistency. To address the challenge, we propose MatchDance, a novel framework for music-to-dance generation that constructs a latent representation to enhance choreographic consistency. MatchDance employs a two-stage design: (1) a Kinematic-Dynamic-based Quantization Stage (KDQS), which encodes dance motions into a latent representation by Finite Scalar Quantization (FSQ) with kinematic-dynamic constraints and reconstructs them with high fidelity, and (2) a Hybrid Music-to-Dance Generation Stage(HMDGS), which uses a Mamba-Transformer hybrid architecture to map music into the latent representation, followed by the KDQS decoder to generate 3D dance motions. Additionally, a music-dance retrieval framework and comprehensive metrics are introduced for evaluation. Extensive experiments on the FineDance dataset demonstrate state-of-the-art performance. Code will be released upon acceptance.
SELECT: A Submodular Approach for Active LiDAR Semantic Segmentation
May 06, 2025



LiDAR-based semantic segmentation plays a vital role in autonomous driving by enabling detailed understanding of 3D environments. However, annotating LiDAR point clouds is extremely costly and requires assigning semantic labels to millions of points with complex geometric structures. Active Learning (AL) has emerged as a promising approach to reduce labeling costs by querying only the most informative samples. Yet, existing AL methods face critical challenges when applied to large-scale 3D data: outdoor scenes contain an overwhelming number of points and suffer from severe class imbalance, where rare classes have far fewer points than dominant classes. To address these issues, we propose SELECT, a voxel-centric submodular approach tailored for active LiDAR semantic segmentation. Our method targets both scalability problems and class imbalance through three coordinated stages. First, we perform Voxel-Level Submodular Subset Selection, which efficiently identifies representative voxels without pairwise comparisons, ensuring scalability. Second, we estimate Voxel-Level Model Uncertainty using Monte Carlo dropout, aggregating point-wise uncertainties to identify informative voxels. Finally, we introduce Submodular Maximization for Point-Level Class Balancing, which selects a subset of points that enhances label diversity, explicitly mitigating class imbalance. Experiments on SemanticPOSS, SemanticKITTI, and nuScenes benchmarks demonstrate that SELECT achieves superior performance compared to prior active learning approaches for 3D semantic segmentation.
CoheDancers: Enhancing Interactive Group Dance Generation through Music-Driven Coherence Decomposition
Dec 26, 2024



Dance generation is crucial and challenging, particularly in domains like dance performance and virtual gaming. In the current body of literature, most methodologies focus on Solo Music2Dance. While there are efforts directed towards Group Music2Dance, these often suffer from a lack of coherence, resulting in aesthetically poor dance performances. Thus, we introduce CoheDancers, a novel framework for Music-Driven Interactive Group Dance Generation. CoheDancers aims to enhance group dance generation coherence by decomposing it into three key aspects: synchronization, naturalness, and fluidity. Correspondingly, we develop a Cycle Consistency based Dance Synchronization strategy to foster music-dance correspondences, an Auto-Regressive-based Exposure Bias Correction strategy to enhance the fluidity of the generated dances, and an Adversarial Training Strategy to augment the naturalness of the group dance output. Collectively, these strategies enable CohdeDancers to produce highly coherent group dances with superior quality. Furthermore, to establish better benchmarks for Group Music2Dance, we construct the most diverse and comprehensive open-source dataset to date, I-Dancers, featuring rich dancer interactions, and create comprehensive evaluation metrics. Experimental evaluations on I-Dancers and other extant datasets substantiate that CoheDancers achieves unprecedented state-of-the-art performance. Code will be released.
The Stabilizer Bootstrap of Quantum Machine Learning with up to 10000 qubits
Dec 16, 2024Quantum machine learning is considered one of the flagship applications of quantum computers, where variational quantum circuits could be the leading paradigm both in the near-term quantum devices and the early fault-tolerant quantum computers. However, it is not clear how to identify the regime of quantum advantages from these circuits, and there is no explicit theory to guide the practical design of variational ansatze to achieve better performance. We address these challenges with the stabilizer bootstrap, a method that uses stabilizer-based techniques to optimize quantum neural networks before their quantum execution, together with theoretical proofs and high-performance computing with 10000 qubits or random datasets up to 1000 data. We find that, in a general setup of variational ansatze, the possibility of improvements from the stabilizer bootstrap depends on the structure of the observables and the size of the datasets. The results reveal that configurations exhibit two distinct behaviors: some maintain a constant probability of circuit improvement, while others show an exponential decay in improvement probability as qubit numbers increase. These patterns are termed strong stabilizer enhancement and weak stabilizer enhancement, respectively, with most situations falling in between. Our work seamlessly bridges techniques from fault-tolerant quantum computing with applications of variational quantum algorithms. Not only does it offer practical insights for designing variational circuits tailored to large-scale machine learning challenges, but it also maps out a clear trajectory for defining the boundaries of feasible and practical quantum advantages.
SmartFRZ: An Efficient Training Framework using Attention-Based Layer Freezing
Jan 30, 2024

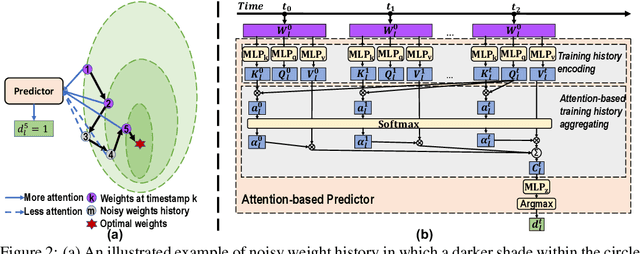

There has been a proliferation of artificial intelligence applications, where model training is key to promising high-quality services for these applications. However, the model training process is both time-intensive and energy-intensive, inevitably affecting the user's demand for application efficiency. Layer freezing, an efficient model training technique, has been proposed to improve training efficiency. Although existing layer freezing methods demonstrate the great potential to reduce model training costs, they still remain shortcomings such as lacking generalizability and compromised accuracy. For instance, existing layer freezing methods either require the freeze configurations to be manually defined before training, which does not apply to different networks, or use heuristic freezing criteria that is hard to guarantee decent accuracy in different scenarios. Therefore, there lacks a generic and smart layer freezing method that can automatically perform ``in-situation'' layer freezing for different networks during training processes. To this end, we propose a generic and efficient training framework (SmartFRZ). The core proposed technique in SmartFRZ is attention-guided layer freezing, which can automatically select the appropriate layers to freeze without compromising accuracy. Experimental results show that SmartFRZ effectively reduces the amount of computation in training and achieves significant training acceleration, and outperforms the state-of-the-art layer freezing approaches.
EdgeOL: Efficient in-situ Online Learning on Edge Devices
Jan 30, 2024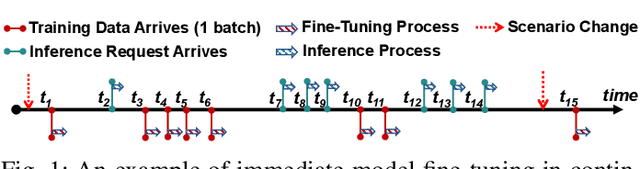
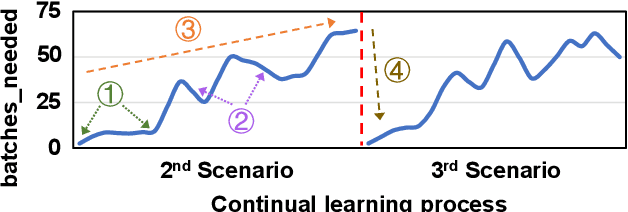
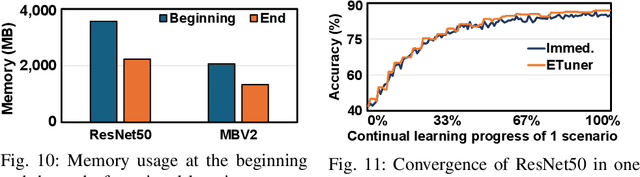
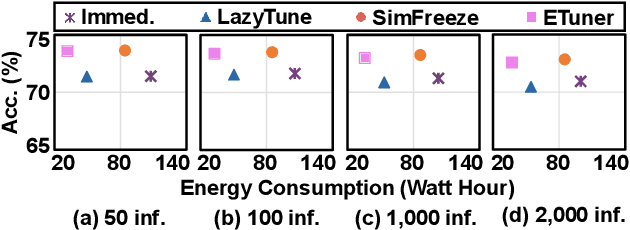
Emerging applications, such as robot-assisted eldercare and object recognition, generally employ deep learning neural networks (DNNs) models and naturally require: i) handling streaming-in inference requests and ii) adapting to possible deployment scenario changes. Online model fine-tuning is widely adopted to satisfy these needs. However, fine-tuning involves significant energy consumption, making it challenging to deploy on edge devices. In this paper, we propose EdgeOL, an edge online learning framework that optimizes inference accuracy, fine-tuning execution time, and energy efficiency through both inter-tuning and intra-tuning optimizations. Experimental results show that, on average, EdgeOL reduces overall fine-tuning execution time by 82%, energy consumption by 74%, and improves average inference accuracy by 1.70% over the immediate online learning strategy.
BeatDance: A Beat-Based Model-Agnostic Contrastive Learning Framework for Music-Dance Retrieval
Oct 16, 2023
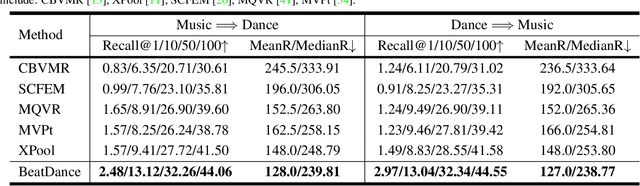
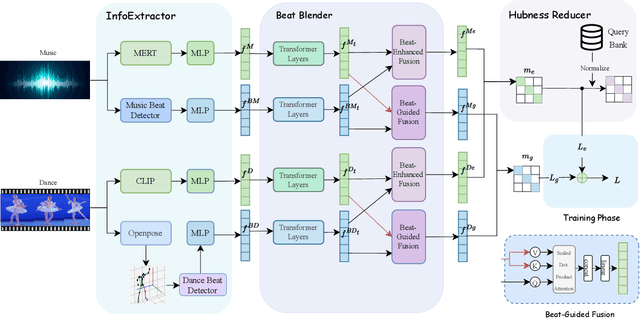
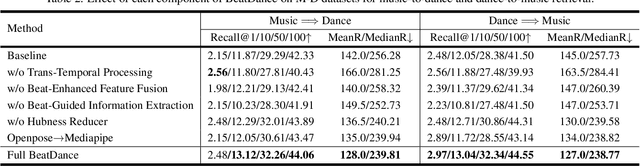
Dance and music are closely related forms of expression, with mutual retrieval between dance videos and music being a fundamental task in various fields like education, art, and sports. However, existing methods often suffer from unnatural generation effects or fail to fully explore the correlation between music and dance. To overcome these challenges, we propose BeatDance, a novel beat-based model-agnostic contrastive learning framework. BeatDance incorporates a Beat-Aware Music-Dance InfoExtractor, a Trans-Temporal Beat Blender, and a Beat-Enhanced Hubness Reducer to improve dance-music retrieval performance by utilizing the alignment between music beats and dance movements. We also introduce the Music-Dance (MD) dataset, a large-scale collection of over 10,000 music-dance video pairs for training and testing. Experimental results on the MD dataset demonstrate the superiority of our method over existing baselines, achieving state-of-the-art performance. The code and dataset will be made public available upon acceptance.