 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Diminishing Returns of Early-Exit Decoding in Modern LLMs
Mar 24, 2026In Large Language Model (LLM) inference, early-exit refers to stopping computation at an intermediate layer once the prediction is sufficiently confident, thereby reducing latency and cost. However, recent LLMs adopt improved pretraining recipes and architectures that reduce layer redundancy, potentially limiting early-exit opportunities. We re-evaluate layer-wise early-exit in modern LLMs and analyze how intermediate representations evolve during training. We introduce a metric to quantify a model's intrinsic suitability for early-exit and propose a benchmark for researchers to explore the potential early-exit benefits on different models and workloads. Our results show a diminishing trend in early-exit effectiveness across newer model generations. We further find that dense transformers generally offer greater early-exit potential than Mixture-of-Experts and State Space Models. In addition, larger models, particularly those with more than 20 billion parameters, and base pretrained models without specialized tuning tend to exhibit higher early-exit potential.
RLHFless: Serverless Computing for Efficient RLHF
Feb 26, 2026Reinforcement Learning from Human Feedback (RLHF) has been widely applied to Large Language Model (LLM) post-training to align model outputs with human preferences. Recent models, such as DeepSeek-R1, have also shown RLHF's potential to improve LLM reasoning on complex tasks. In RL, inference and training co-exist, creating dynamic resource demands throughout the workflow. Compared to traditional RL, RLHF further challenges training efficiency due to expanding model sizes and resource consumption. Several RLHF frameworks aim to balance flexible abstraction and efficient execution. However, they rely on serverful infrastructures, which struggle with fine-grained resource variability. As a result, during synchronous RLHF training, idle time between or within RL components often causes overhead and resource wastage. To address these issues, we present RLHFless, the first scalable training framework for synchronous RLHF, built on serverless computing environments. RLHFless adapts to dynamic resource demands throughout the RLHF pipeline, pre-computes shared prefixes to avoid repeated computation, and uses a cost-aware actor scaling strategy that accounts for response length variation to find sweet spots with lower cost and higher speed. In addition, RLHFless assigns workloads efficiently to reduce intra-function imbalance and idle time. Experiments on both physical testbeds and a large-scale simulated cluster show that RLHFless achieves up to 1.35x speedup and 44.8% cost reduction compared to the state-of-the-art baseline.
Qompose: A Technique to Select Optimal Algorithm- Specific Layout for Neutral Atom Quantum Architectures
Sep 29, 2024As quantum computing architecture matures, it is important to investigate new technologies that lend unique advantages. In this work, we propose, Qompose, a neutral atom quantum computing framework for efficiently composing quantum circuits on 2-D topologies of neutral atoms. Qompose selects an efficient topology for any given circuit in order to optimize for length of execution through efficient parallelism and for overall fidelity. our extensive evaluation demonstrates the Qompose is effective for a large collection of randomly-generated quantum circuits and a range of real-world benchmarks including VQE, ISING, and QAOA.
OrganiQ: Mitigating Classical Resource Bottlenecks of Quantum Generative Adversarial Networks on NISQ-Era Machines
Sep 29, 2024
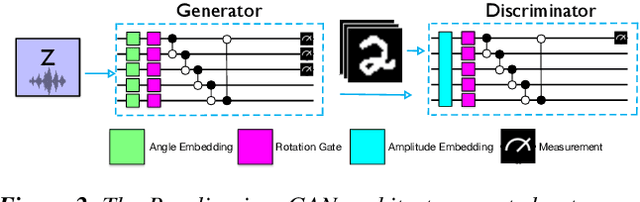


Driven by swift progress in hardware capabilities, quantum machine learning has emerged as a research area of interest. Recently, quantum image generation has produced promising results. However, prior quantum image generation techniques rely on classical neural networks, limiting their quantum potential and image quality. To overcome this, we introduce OrganiQ, the first quantum GAN capable of producing high-quality images without using classical neural networks.
LLM Inference Serving: Survey of Recent Advances and Opportunities
Jul 17, 2024This survey offers a comprehensive overview of recent advancements in Large Language Model (LLM) serving systems, focusing on research since the year 2023. We specifically examine system-level enhancements that improve performance and efficiency without altering the core LLM decoding mechanisms. By selecting and reviewing high-quality papers from prestigious ML and system venues, we highlight key innovations and practical considerations for deploying and scaling LLMs in real-world production environments. This survey serves as a valuable resource for LLM practitioners seeking to stay abreast of the latest developments in this rapidly evolving field.
Toward Sustainable GenAI using Generation Directives for Carbon-Friendly Large Language Model Inference
Mar 19, 2024The rapid advancement of Generative Artificial Intelligence (GenAI) across diverse sectors raises significant environmental concerns, notably the carbon emissions from their cloud and high performance computing (HPC) infrastructure. This paper presents Sprout, an innovative framework designed to address these concerns by reducing the carbon footprint of generative Large Language Model (LLM) inference services. Sprout leverages the innovative concept of "generation directives" to guide the autoregressive generation process, thereby enhancing carbon efficiency. Our proposed method meticulously balances the need for ecological sustainability with the demand for high-quality generation outcomes. Employing a directive optimizer for the strategic assignment of generation directives to user prompts and an original offline quality evaluator, Sprout demonstrates a significant reduction in carbon emissions by over 40% in real-world evaluations using the Llama2 LLM and global electricity grid data. This research marks a critical step toward aligning AI technology with sustainable practices, highlighting the potential for mitigating environmental impacts in the rapidly expanding domain of generative artificial intelligence.
Sustainable Supercomputing for AI: GPU Power Capping at HPC Scale
Feb 25, 2024

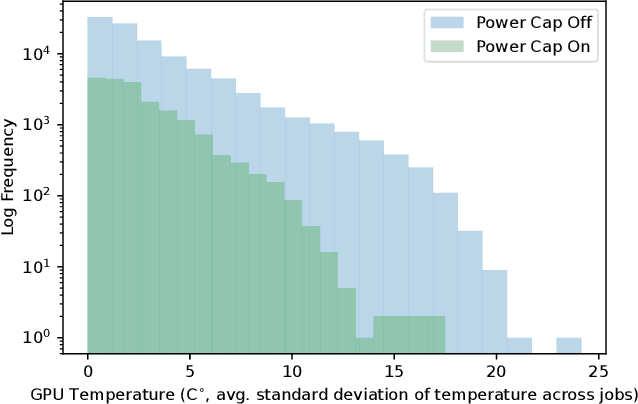
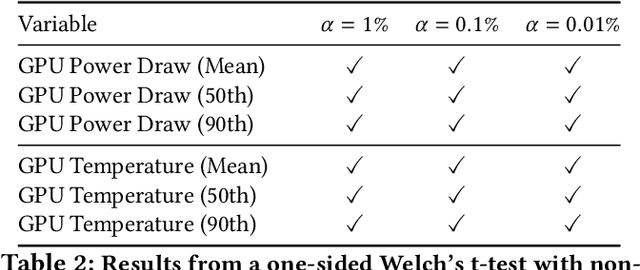
As research and deployment of AI grows, the computational burden to support and sustain its progress inevitably does too. To train or fine-tune state-of-the-art models in NLP, computer vision, etc., some form of AI hardware acceleration is virtually a requirement. Recent large language models require considerable resources to train and deploy, resulting in significant energy usage, potential carbon emissions, and massive demand for GPUs and other hardware accelerators. However, this surge carries large implications for energy sustainability at the HPC/datacenter level. In this paper, we study the aggregate effect of power-capping GPUs on GPU temperature and power draw at a research supercomputing center. With the right amount of power-capping, we show significant decreases in both temperature and power draw, reducing power consumption and potentially improving hardware life-span with minimal impact on job performance. While power-capping reduces power draw by design, the aggregate system-wide effect on overall energy consumption is less clear; for instance, if users notice job performance degradation from GPU power-caps, they may request additional GPU-jobs to compensate, negating any energy savings or even worsening energy consumption. To our knowledge, our work is the first to conduct and make available a detailed analysis of the effects of GPU power-capping at the supercomputing scale. We hope our work will inspire HPCs/datacenters to further explore, evaluate, and communicate the impact of power-capping AI hardware accelerators for more sustainable AI.
From Words to Watts: Benchmarking the Energy Costs of Large Language Model Inference
Oct 04, 2023
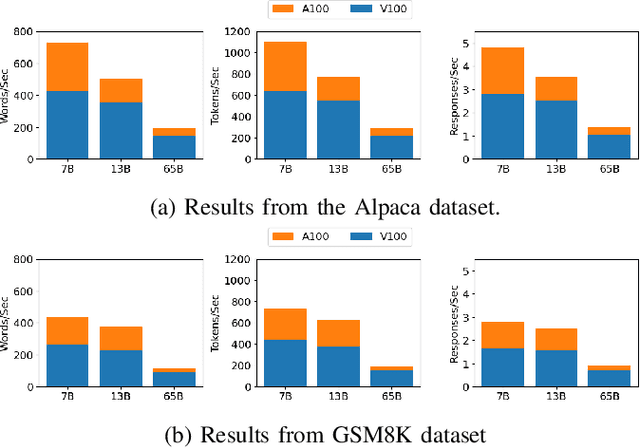
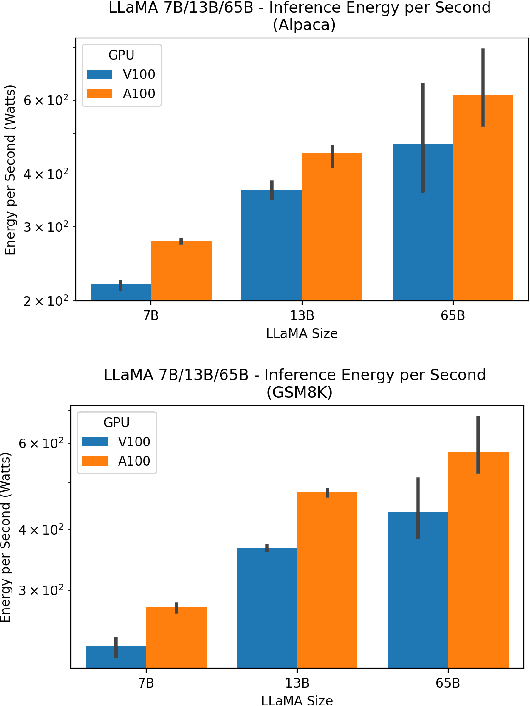
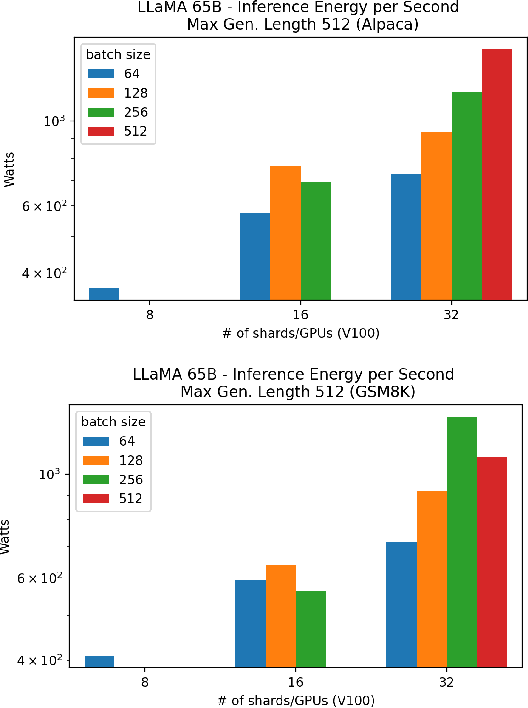
Large language models (LLMs) have exploded in popularity due to their new generative capabilities that go far beyond prior state-of-the-art. These technologies are increasingly being leveraged in various domains such as law, finance, and medicine. However, these models carry significant computational challenges, especially the compute and energy costs required for inference. Inference energy costs already receive less attention than the energy costs of training LLMs -- despite how often these large models are called on to conduct inference in reality (e.g., ChatGPT). As these state-of-the-art LLMs see increasing usage and deployment in various domains, a better understanding of their resource utilization is crucial for cost-savings, scaling performance, efficient hardware usage, and optimal inference strategies. In this paper, we describe experiments conducted to study the computational and energy utilization of inference with LLMs. We benchmark and conduct a preliminary analysis of the inference performance and inference energy costs of different sizes of LLaMA -- a recent state-of-the-art LLM -- developed by Meta AI on two generations of popular GPUs (NVIDIA V100 \& A100) and two datasets (Alpaca and GSM8K) to reflect the diverse set of tasks/benchmarks for LLMs in research and practice. We present the results of multi-node, multi-GPU inference using model sharding across up to 32 GPUs. To our knowledge, our work is the one of the first to study LLM inference performance from the perspective of computational and energy resources at this scale.
SLIQ: Quantum Image Similarity Networks on Noisy Quantum Computers
Sep 26, 2023

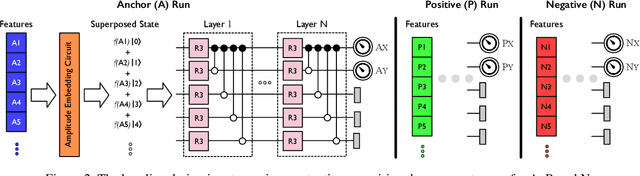

Exploration into quantum machine learning has grown tremendously in recent years due to the ability of quantum computers to speed up classical programs. However, these efforts have yet to solve unsupervised similarity detection tasks due to the challenge of porting them to run on quantum computers. To overcome this challenge, we propose SLIQ, the first open-sourced work for resource-efficient quantum similarity detection networks, built with practical and effective quantum learning and variance-reducing algorithms.
QUILT: Effective Multi-Class Classification on Quantum Computers Using an Ensemble of Diverse Quantum Classifiers
Sep 26, 2023



Quantum computers can theoretically have significant acceleration over classical computers; but, the near-future era of quantum computing is limited due to small number of qubits that are also error prone. Quilt is a framework for performing multi-class classification task designed to work effectively on current error-prone quantum computers. Quilt is evaluated with real quantum machines as well as with projected noise levels as quantum machines become more noise-free. Quilt demonstrates up to 85% multi-class classification accuracy with the MNIST dataset on a five-qubit system.