 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Words to Watts: Benchmarking the Energy Costs of Large Language Model Inference
Oct 04, 2023
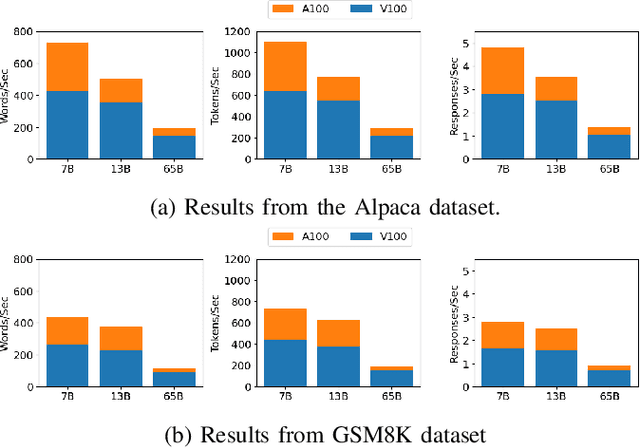
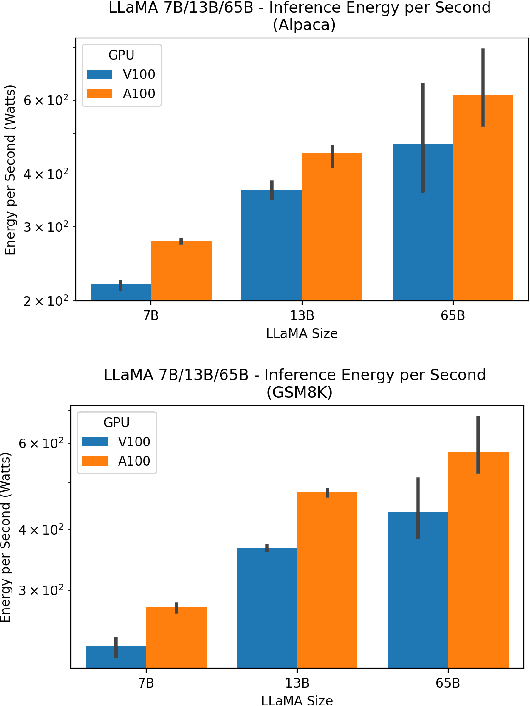
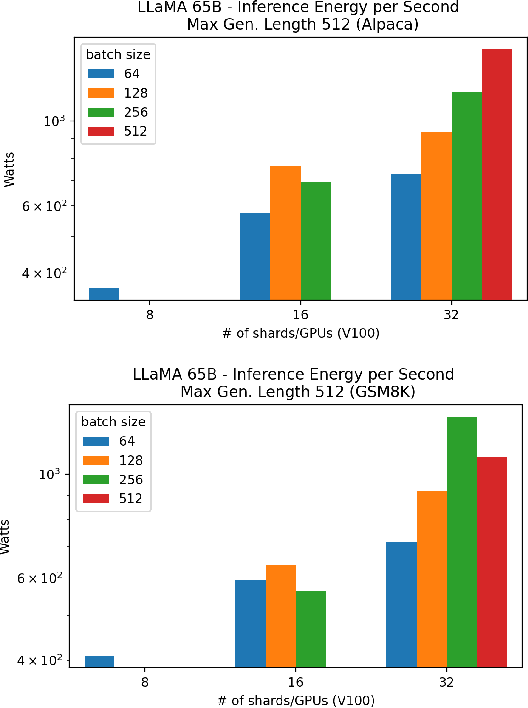
Large language models (LLMs) have exploded in popularity due to their new generative capabilities that go far beyond prior state-of-the-art. These technologies are increasingly being leveraged in various domains such as law, finance, and medicine. However, these models carry significant computational challenges, especially the compute and energy costs required for inference. Inference energy costs already receive less attention than the energy costs of training LLMs -- despite how often these large models are called on to conduct inference in reality (e.g., ChatGPT). As these state-of-the-art LLMs see increasing usage and deployment in various domains, a better understanding of their resource utilization is crucial for cost-savings, scaling performance, efficient hardware usage, and optimal inference strategies. In this paper, we describe experiments conducted to study the computational and energy utilization of inference with LLMs. We benchmark and conduct a preliminary analysis of the inference performance and inference energy costs of different sizes of LLaMA -- a recent state-of-the-art LLM -- developed by Meta AI on two generations of popular GPUs (NVIDIA V100 \& A100) and two datasets (Alpaca and GSM8K) to reflect the diverse set of tasks/benchmarks for LLMs in research and practice. We present the results of multi-node, multi-GPU inference using model sharding across up to 32 GPUs. To our knowledge, our work is the one of the first to study LLM inference performance from the perspective of computational and energy resources at this scale.
The MIT Supercloud Workload Classification Challenge
Apr 13, 2022

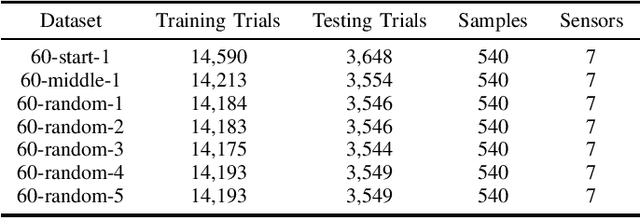
High-Performance Computing (HPC) centers and cloud providers support an increasingly diverse set of applications on heterogenous hardware. As Artificial Intelligence (AI) and Machine Learning (ML) workloads have become an increasingly larger share of the compute workloads, new approaches to optimized resource usage, allocation, and deployment of new AI frameworks are needed. By identifying compute workloads and their utilization characteristics, HPC systems may be able to better match available resources with the application demand. By leveraging datacenter instrumentation, it may be possible to develop AI-based approaches that can identify workloads and provide feedback to researchers and datacenter operators for improving operational efficiency. To enable this research, we released the MIT Supercloud Dataset, which provides detailed monitoring logs from the MIT Supercloud cluster. This dataset includes CPU and GPU usage by jobs, memory usage, and file system logs. In this paper, we present a workload classification challenge based on this dataset. We introduce a labelled dataset that can be used to develop new approaches to workload classification and present initial results based on existing approaches. The goal of this challenge is to foster algorithmic innovations in the analysis of compute workloads that can achieve higher accuracy than existing methods. Data and code will be made publicly available via the Datacenter Challenge website : https://dcc.mit.edu.
The MIT Supercloud Dataset
Aug 04, 2021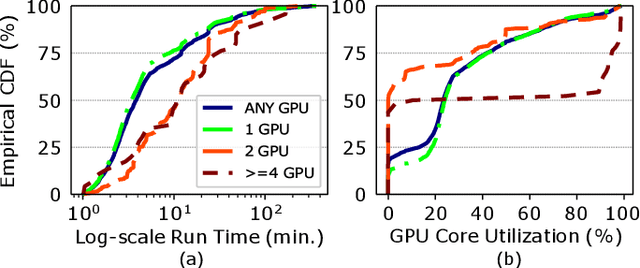
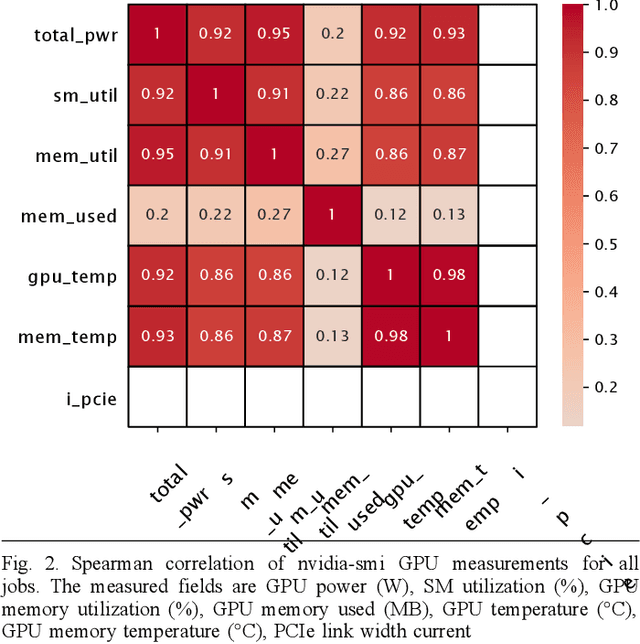
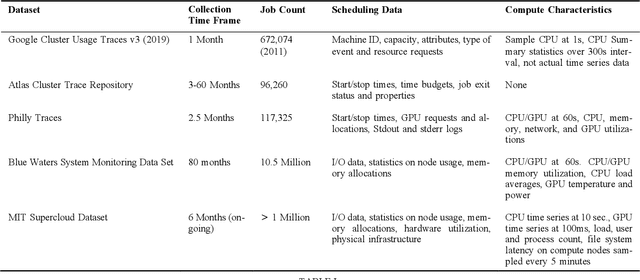

Artificial intelligence (AI) and Machine learning (ML) workloads are an increasingly larger share of the compute workloads in traditional High-Performance Computing (HPC) centers and commercial cloud systems. This has led to changes in deployment approaches of HPC clusters and the commercial cloud, as well as a new focus on approaches to optimized resource usage, allocations and deployment of new AI frame- works, and capabilities such as Jupyter notebooks to enable rapid prototyping and deployment. With these changes, there is a need to better understand cluster/datacenter operations with the goal of developing improved scheduling policies, identifying inefficiencies in resource utilization, energy/power consumption, failure prediction, and identifying policy violations. In this paper we introduce the MIT Supercloud Dataset which aims to foster innovative AI/ML approaches to the analysis of large scale HPC and datacenter/cloud operations. We provide detailed monitoring logs from the MIT Supercloud system, which include CPU and GPU usage by jobs, memory usage, file system logs, and physical monitoring data. This paper discusses the details of the dataset, collection methodology, data availability, and discusses potential challenge problems being developed using this data. Datasets and future challenge announcements will be available via https://dcc.mit.edu.