 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplexity of One-Dimensional ReLU DNNs
Dec 08, 2025We study the expressivity of one-dimensional (1D) ReLU deep neural networks through the lens of their linear regions. For randomly initialized, fully connected 1D ReLU networks (He scaling with nonzero bias) in the infinite-width limit, we prove that the expected number of linear regions grows as $\sum_{i = 1}^L n_i + \mathop{o}\left(\sum_{i = 1}^L{n_i}\right) + 1$, where $n_\ell$ denotes the number of neurons in the $\ell$-th hidden layer. We also propose a function-adaptive notion of sparsity that compares the expected regions used by the network to the minimal number needed to approximate a target within a fixed tolerance.
Accelerating AI Development with Cyber Arenas
Sep 10, 2025
AI development requires high fidelity testing environments to effectively transition from the laboratory to operations. The flexibility offered by cyber arenas presents a novel opportunity to test new artificial intelligence (AI) capabilities with users. Cyber arenas are designed to expose end-users to real-world situations and must rapidly incorporate evolving capabilities to meet their core objectives. To explore this concept the MIT/IEEE/Amazon Graph Challenge Anonymized Network Sensor was deployed in a cyber arena during a National Guard exercise.
Testing RadiX-Nets: Advances in Viable Sparse Topologies
Nov 06, 2023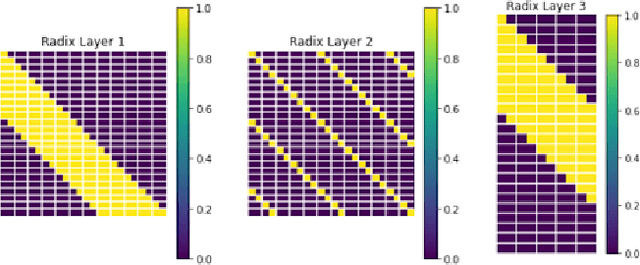
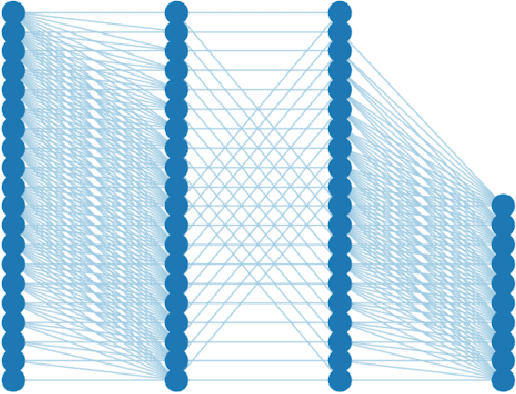
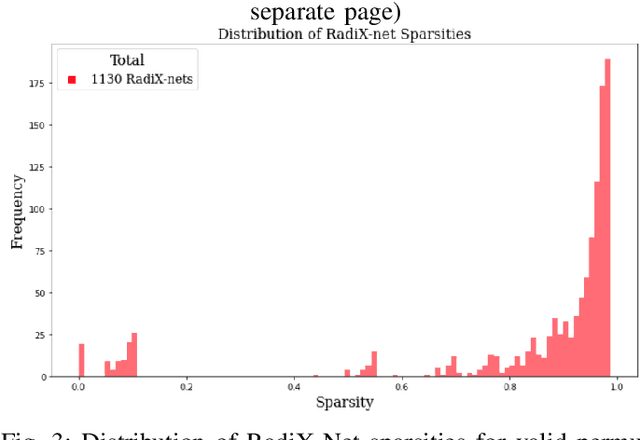
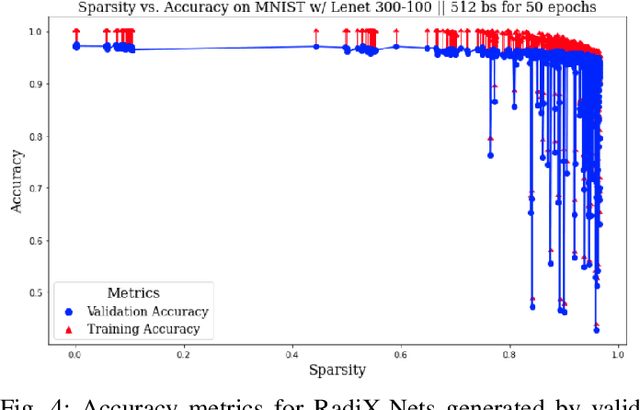
The exponential growth of data has sparked computational demands on ML research and industry use. Sparsification of hyper-parametrized deep neural networks (DNNs) creates simpler representations of complex data. Past research has shown that some sparse networks achieve similar performance as dense ones, reducing runtime and storage. RadiX-Nets, a subgroup of sparse DNNs, maintain uniformity which counteracts their lack of neural connections. Generation, independent of a dense network, yields faster asymptotic training and removes the need for costly pruning. However, little work has been done on RadiX-Nets, making testing challenging. This paper presents a testing suite for RadiX-Nets in TensorFlow. We test RadiX-Net performance to streamline processing in scalable models, revealing relationships between network topology, initialization, and training behavior. We also encounter "strange models" that train inconsistently and to lower accuracy while models of similar sparsity train well.
Lincoln AI Computing Survey (LAICS) Update
Oct 13, 2023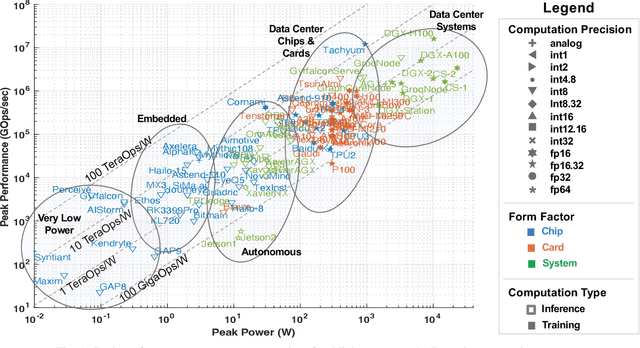
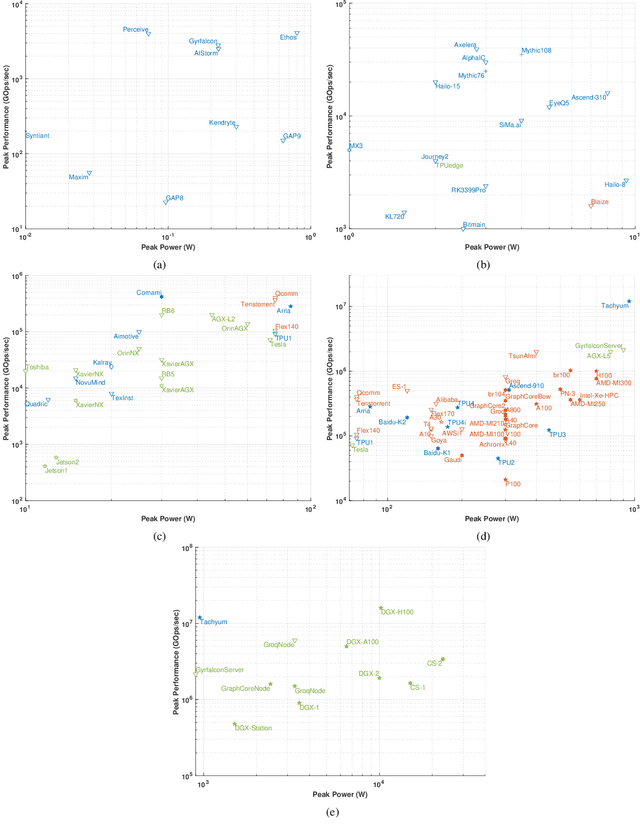
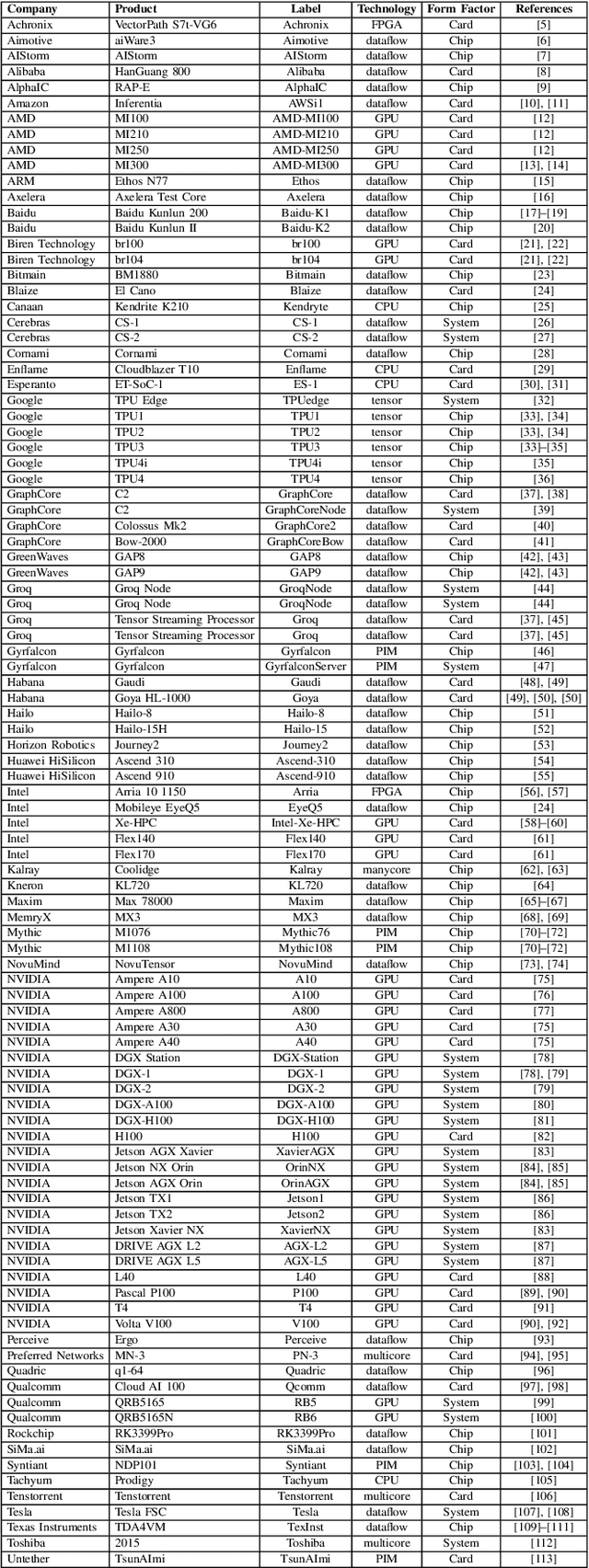
This paper is an update of the survey of AI accelerators and processors from past four years, which is now called the Lincoln AI Computing Survey - LAICS (pronounced "lace"). As in past years, this paper collects and summarizes the current commercial accelerators that have been publicly announced with peak performance and peak power consumption numbers. The performance and power values are plotted on a scatter graph, and a number of dimensions and observations from the trends on this plot are again discussed and analyzed. Market segments are highlighted on the scatter plot, and zoomed plots of each segment are also included. Finally, a brief description of each of the new accelerators that have been added in the survey this year is included.
From Words to Watts: Benchmarking the Energy Costs of Large Language Model Inference
Oct 04, 2023
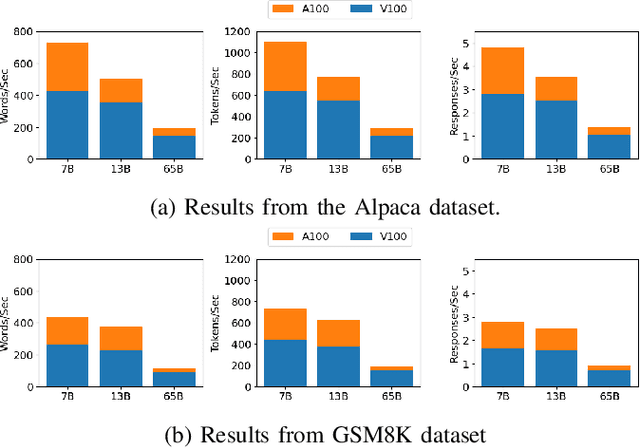
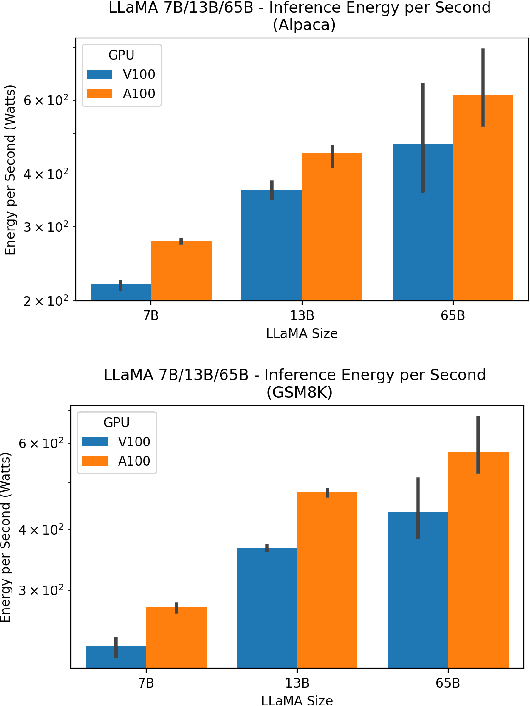
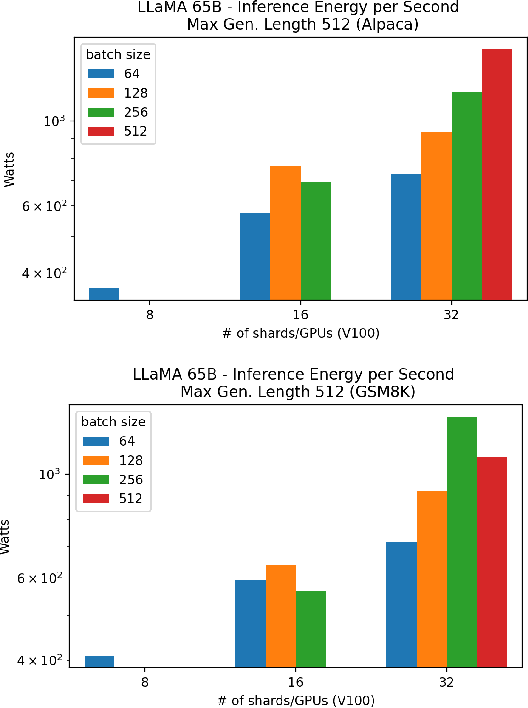
Large language models (LLMs) have exploded in popularity due to their new generative capabilities that go far beyond prior state-of-the-art. These technologies are increasingly being leveraged in various domains such as law, finance, and medicine. However, these models carry significant computational challenges, especially the compute and energy costs required for inference. Inference energy costs already receive less attention than the energy costs of training LLMs -- despite how often these large models are called on to conduct inference in reality (e.g., ChatGPT). As these state-of-the-art LLMs see increasing usage and deployment in various domains, a better understanding of their resource utilization is crucial for cost-savings, scaling performance, efficient hardware usage, and optimal inference strategies. In this paper, we describe experiments conducted to study the computational and energy utilization of inference with LLMs. We benchmark and conduct a preliminary analysis of the inference performance and inference energy costs of different sizes of LLaMA -- a recent state-of-the-art LLM -- developed by Meta AI on two generations of popular GPUs (NVIDIA V100 \& A100) and two datasets (Alpaca and GSM8K) to reflect the diverse set of tasks/benchmarks for LLMs in research and practice. We present the results of multi-node, multi-GPU inference using model sharding across up to 32 GPUs. To our knowledge, our work is the one of the first to study LLM inference performance from the perspective of computational and energy resources at this scale.
Are ChatGPT and Other Similar Systems the Modern Lernaean Hydras of AI?
Jun 15, 2023The rise of Generative Artificial Intelligence systems (``AI systems'') has created unprecedented social engagement. AI code generation systems provide responses (output) to questions or requests by accessing the vast library of open-source code created by developers over decades. However, they do so by allegedly stealing the open-source code stored in virtual libraries, known as repositories. How all this happens and whether there is a solution short of years of litigation that can protect innovation is the focus of this article. We also peripherally touch upon the array of issues raised by the relationship between AI and copyright. Looking ahead, we propose the following: (a) immediate changes to the licenses for open-source code created by developers that will allow access and/or use of any open-source code to humans only; (b) we suggest revisions to the Massachusetts Institute of Technology (``MIT'') license so that AI systems procure appropriate licenses from open-source code developers, which we believe will harmonize standards and build social consensus for the benefit of all of humanity rather than profit-driven centers of innovation; (c) We call for urgent legislative action to protect the future of AI systems while also promoting innovation; and (d) we propose that there is a shift in the burden of proof to AI systems in obfuscation cases.
AI Enabled Maneuver Identification via the Maneuver Identification Challenge
Nov 28, 2022



Artificial intelligence (AI) has enormous potential to improve Air Force pilot training by providing actionable feedback to pilot trainees on the quality of their maneuvers and enabling instructor-less flying familiarization for early-stage trainees in low-cost simulators. Historically, AI challenges consisting of data, problem descriptions, and example code have been critical to fueling AI breakthroughs. The Department of the Air Force-Massachusetts Institute of Technology AI Accelerator (DAF-MIT AI Accelerator) developed such an AI challenge using real-world Air Force flight simulator data. The Maneuver ID challenge assembled thousands of virtual reality simulator flight recordings collected by actual Air Force student pilots at Pilot Training Next (PTN). This dataset has been publicly released at Maneuver-ID.mit.edu and represents the first of its kind public release of USAF flight training data. Using this dataset, we have applied a variety of AI methods to separate "good" vs "bad" simulator data and categorize and characterize maneuvers. These data, algorithms, and software are being released as baselines of model performance for others to build upon to enable the AI ecosystem for flight simulator training.
Developing a Series of AI Challenges for the United States Department of the Air Force
Jul 14, 2022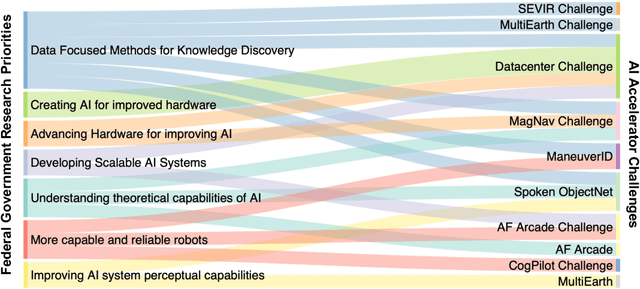

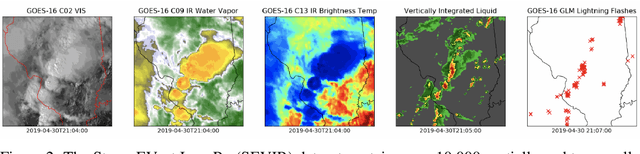
Through a series of federal initiatives and orders, the U.S. Government has been making a concerted effort to ensure American leadership in AI. These broad strategy documents have influenced organizations such as the United States Department of the Air Force (DAF). The DAF-MIT AI Accelerator is an initiative between the DAF and MIT to bridge the gap between AI researchers and DAF mission requirements. Several projects supported by the DAF-MIT AI Accelerator are developing public challenge problems that address numerous Federal AI research priorities. These challenges target priorities by making large, AI-ready datasets publicly available, incentivizing open-source solutions, and creating a demand signal for dual use technologies that can stimulate further research. In this article, we describe these public challenges being developed and how their application contributes to scientific advances.
The MIT Supercloud Workload Classification Challenge
Apr 13, 2022

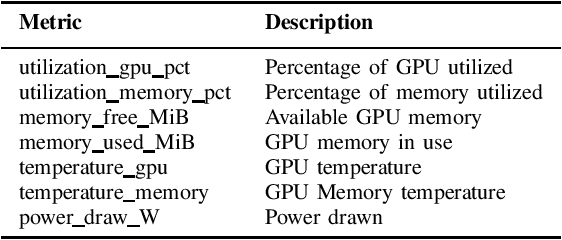
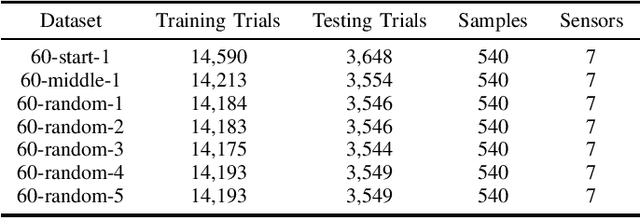
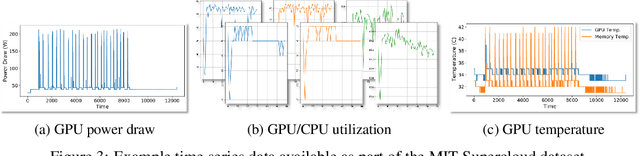
High-Performance Computing (HPC) centers and cloud providers support an increasingly diverse set of applications on heterogenous hardware. As Artificial Intelligence (AI) and Machine Learning (ML) workloads have become an increasingly larger share of the compute workloads, new approaches to optimized resource usage, allocation, and deployment of new AI frameworks are needed. By identifying compute workloads and their utilization characteristics, HPC systems may be able to better match available resources with the application demand. By leveraging datacenter instrumentation, it may be possible to develop AI-based approaches that can identify workloads and provide feedback to researchers and datacenter operators for improving operational efficiency. To enable this research, we released the MIT Supercloud Dataset, which provides detailed monitoring logs from the MIT Supercloud cluster. This dataset includes CPU and GPU usage by jobs, memory usage, and file system logs. In this paper, we present a workload classification challenge based on this dataset. We introduce a labelled dataset that can be used to develop new approaches to workload classification and present initial results based on existing approaches. The goal of this challenge is to foster algorithmic innovations in the analysis of compute workloads that can achieve higher accuracy than existing methods. Data and code will be made publicly available via the Datacenter Challenge website : https://dcc.mit.edu.
Naming Schema for a Human Brain-Scale Neural Network
Sep 22, 2021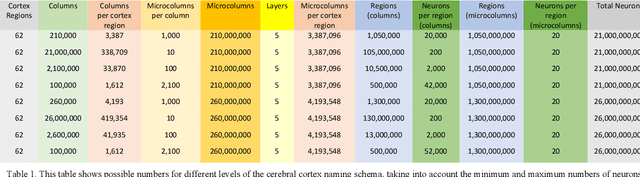
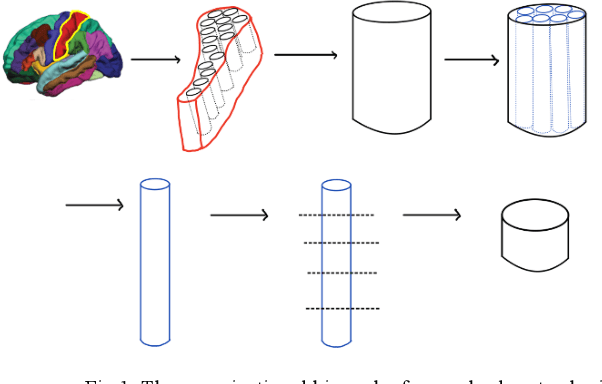
Deep neural networks have become increasingly large and sparse, allowing for the storage of large-scale neural networks with decreased costs of storage and computation. Storage of a neural network with as many connections as the human brain is possible with current versions of the high-performance Apache Accumulo database and the Distributed Dimensional Data Model (D4M) software. Neural networks of such large scale may be of particular interest to scientists within the human brain Connectome community. To aid in research and understanding of artificial neural networks that parallel existing neural networks like the brain, a naming schema can be developed to label groups of neurons in the artificial network that parallel those in the brain. Groups of artificial neurons are able to be specifically labeled in small regions for future study.