 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model-Guided Prediction Toward Quantum Materials Synthesis
Oct 28, 2024



The synthesis of inorganic crystalline materials is essential for modern technology, especially in quantum materials development. However, designing efficient synthesis workflows remains a significant challenge due to the precise experimental conditions and extensive trial and error. Here, we present a framework using large language models (LLMs) to predict synthesis pathways for inorganic materials, including quantum materials. Our framework contains three models: LHS2RHS, predicting products from reactants; RHS2LHS, predicting reactants from products; and TGT2CEQ, generating full chemical equations for target compounds. Fine-tuned on a text-mined synthesis database, our model raises accuracy from under 40% with pretrained models, to under 80% using conventional fine-tuning, and further to around 90% with our proposed generalized Tanimoto similarity, while maintaining robust to additional synthesis steps. Our model further demonstrates comparable performance across materials with varying degrees of quantumness quantified using quantum weight, indicating that LLMs offer a powerful tool to predict balanced chemical equations for quantum materials discovery.
Testing RadiX-Nets: Advances in Viable Sparse Topologies
Nov 06, 2023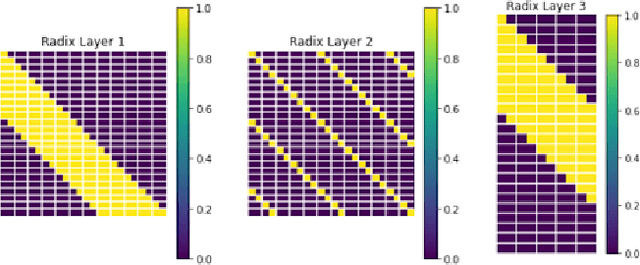
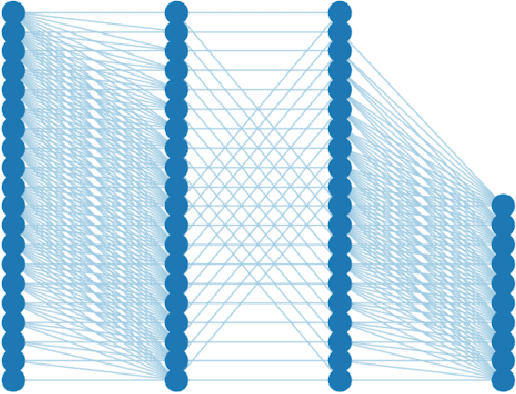
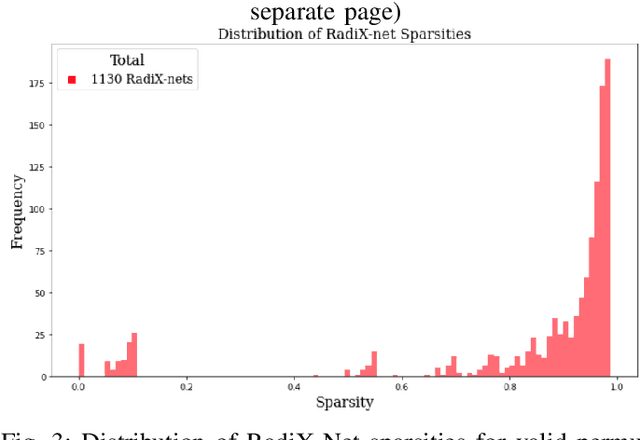
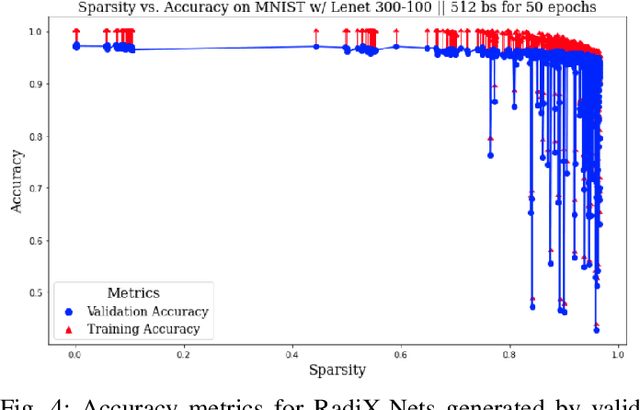
The exponential growth of data has sparked computational demands on ML research and industry use. Sparsification of hyper-parametrized deep neural networks (DNNs) creates simpler representations of complex data. Past research has shown that some sparse networks achieve similar performance as dense ones, reducing runtime and storage. RadiX-Nets, a subgroup of sparse DNNs, maintain uniformity which counteracts their lack of neural connections. Generation, independent of a dense network, yields faster asymptotic training and removes the need for costly pruning. However, little work has been done on RadiX-Nets, making testing challenging. This paper presents a testing suite for RadiX-Nets in TensorFlow. We test RadiX-Net performance to streamline processing in scalable models, revealing relationships between network topology, initialization, and training behavior. We also encounter "strange models" that train inconsistently and to lower accuracy while models of similar sparsity train well.