 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Customized Fashion Design with Image-into-Prompt benchmark and dataset from LMM
Sep 11, 2025Generative AI evolves the execution of complex workflows in industry, where the large multimodal model empowers fashion design in the garment industry. Current generation AI models magically transform brainstorming into fancy designs easily, but the fine-grained customization still suffers from text uncertainty without professional background knowledge from end-users. Thus, we propose the Better Understanding Generation (BUG) workflow with LMM to automatically create and fine-grain customize the cloth designs from chat with image-into-prompt. Our framework unleashes users' creative potential beyond words and also lowers the barriers of clothing design/editing without further human involvement. To prove the effectiveness of our model, we propose a new FashionEdit dataset that simulates the real-world clothing design workflow, evaluated from generation similarity, user satisfaction, and quality. The code and dataset: https://github.com/detectiveli/FashionEdit.
A model and package for German ColBERT
Apr 25, 2025In this work, we introduce a German version for ColBERT, a late interaction multi-dense vector retrieval method, with a focus on RAG applications. We also present the main features of our package for ColBERT models, supporting both retrieval and fine-tuning workflows.
Understanding When Tree of Thoughts Succeeds: Larger Models Excel in Generation, Not Discrimination
Oct 24, 2024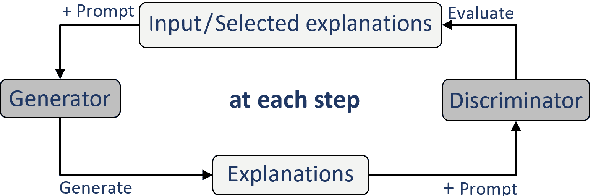
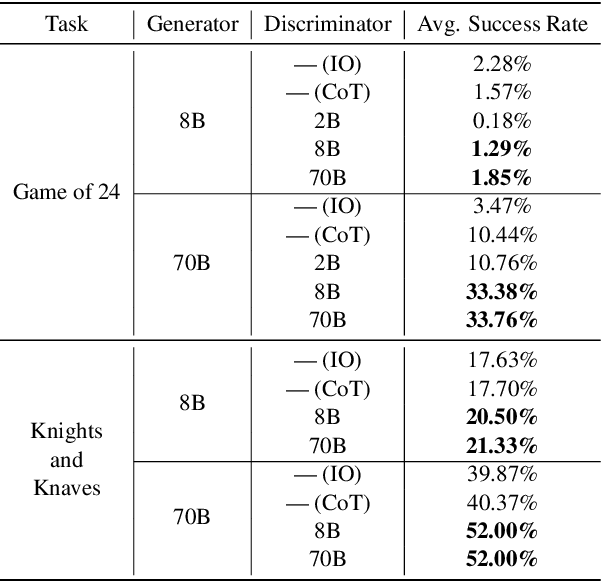

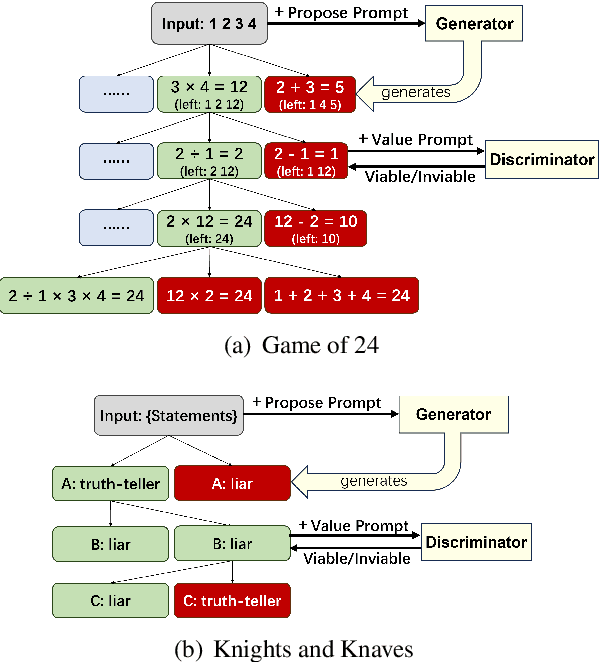
Tree of Thoughts (ToT) is a reasoning strategy for Large Language Models (LLMs) that employs a generator to suggest reasoning steps and a discriminator to decide which steps to implement. ToT demonstrates strong performance on reasoning tasks, often surpassing simple methods such as Input-Output (IO) prompting and Chain-of-Thought (CoT) reasoning. However, ToT does not consistently outperform such simpler methods across all models, leaving large knowledge gaps on the conditions under which ToT is most beneficial. In this paper, we analyze the roles of the generator and discriminator separately to better understand the conditions when ToT is beneficial. We find that the generator plays a more critical role than the discriminator in driving the success of ToT. Scaling the generator leads to notable improvements in ToT performance, even when using a smaller model as the discriminator, whereas scaling the discriminator with a fixed generator yields only marginal gains. Our results show that models across different scales exhibit comparable discrimination capabilities, yet differ significantly in their generative performance for ToT.
The MIT Supercloud Workload Classification Challenge
Apr 13, 2022

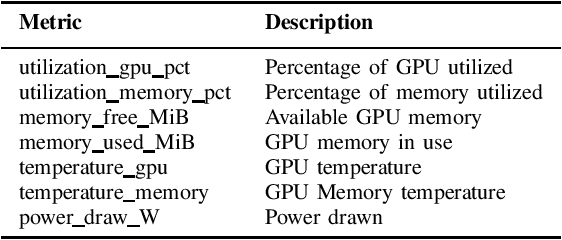
High-Performance Computing (HPC) centers and cloud providers support an increasingly diverse set of applications on heterogenous hardware. As Artificial Intelligence (AI) and Machine Learning (ML) workloads have become an increasingly larger share of the compute workloads, new approaches to optimized resource usage, allocation, and deployment of new AI frameworks are needed. By identifying compute workloads and their utilization characteristics, HPC systems may be able to better match available resources with the application demand. By leveraging datacenter instrumentation, it may be possible to develop AI-based approaches that can identify workloads and provide feedback to researchers and datacenter operators for improving operational efficiency. To enable this research, we released the MIT Supercloud Dataset, which provides detailed monitoring logs from the MIT Supercloud cluster. This dataset includes CPU and GPU usage by jobs, memory usage, and file system logs. In this paper, we present a workload classification challenge based on this dataset. We introduce a labelled dataset that can be used to develop new approaches to workload classification and present initial results based on existing approaches. The goal of this challenge is to foster algorithmic innovations in the analysis of compute workloads that can achieve higher accuracy than existing methods. Data and code will be made publicly available via the Datacenter Challenge website : https://dcc.mit.edu.