 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Prompt vs. Image Enhancement: Boosting Object Detection With CLIP in Hazy Environments
Apr 12, 2026Object detection in hazy environments is challenging because degraded objects are nearly invisible and their semantics are weakened by environmental noise, making it difficult for detectors to identify. Common approaches involve image enhancement to boost weakened semantics, but these methods are limited by the instability of enhanced modules. This paper proposes a novel solution by employing language prompts to enhance weakened semantics without image enhancement. Specifically, we design Approximation of Mutual Exclusion (AME) to provide credible weights for Cross-Entropy Loss, resulting in CLIP-guided Cross-Entropy Loss (CLIP-CE). The provided weights assess the semantic weakening of objects. Through the backpropagation of CLIP-CE, weakened semantics are enhanced, making degraded objects easier to detect. In addition, we present Fine-tuned AME (FAME) which adaptively fine-tunes the weight of AME based on the predicted confidence. The proposed FAME compensates for the imbalanced optimization in AME. Furthermore, we present HazyCOCO, a large-scale synthetic hazy dataset comprising 61258 images. Experimental results demonstrate that our method achieves state-of-the-art performance. The code and dataset will be released.
TF-SSD: A Strong Pipeline via Synergic Mask Filter for Training-free Co-salient Object Detection
Apr 01, 2026Co-salient Object Detection (CoSOD) aims to segment salient objects that consistently appear across a group of related images. Despite the notable progress achieved by recent training-based approaches, they still remain constrained by the closed-set datasets and exhibit limited generalization. However, few studies explore the potential of Vision Foundation Models (VFMs) to address CoSOD, which demonstrate a strong generalized ability and robust saliency understanding. In this paper, we investigate and leverage VFMs for CoSOD, and further propose a novel training-free method, TF-SSD, through the synergy between SAM and DINO. Specifically, we first utilize SAM to generate comprehensive raw proposals, which serve as a candidate mask pool. Then, we introduce a quality mask generator to filter out redundant masks, thereby acquiring a refined mask set. Since this generator is built upon SAM, it inherently lacks semantic understanding of saliency. To this end, we adopt an intra-image saliency filter that employs DINO's attention maps to identify visually salient masks within individual images. Moreover, to extend saliency understanding across group images, we propose an inter-image prototype selector, which computes similarity scores among cross-image prototypes to select masks with the highest score. These selected masks serve as final predictions for CoSOD. Extensive experiments show that our TF-SSD outperforms existing methods (e.g., 13.7\% gains over the recent training-free method). Codes are available at https://github.com/hzz-yy/TF-SSD.
TALENT: Target-aware Efficient Tuning for Referring Image Segmentation
Apr 01, 2026Referring image segmentation aims to segment specific targets based on a natural text expression. Recently, parameter-efficient tuning (PET) has emerged as a promising paradigm. However, existing PET-based methods often suffer from the fact that visual features can't emphasize the text-referred target instance but activate co-category yet unrelated objects. We analyze and quantify this problem, terming it the `non-target activation' (NTA) issue. To address this, we propose a novel framework, TALENT, which utilizes target-aware efficient tuning for PET-based RIS. Specifically, we first propose a Rectified Cost Aggregator (RCA) to efficiently aggregate text-referred features. Then, to calibrate `NTA' into accurate target activation, we adopt a Target-aware Learning Mechanism (TLM), including contextual pairwise consistency learning and target-centric contrastive learning. The former uses the sentence-level text feature to achieve a holistic understanding of the referent and constructs a text-referred affinity map to optimize the semantic association of visual features. The latter further enhances target localization to discover the distinct instance while suppressing associations with other unrelated ones. The two objectives work in concert and address `NTA' effectively. Extensive evaluations show that TALENT outperforms existing methods across various metrics (e.g., 2.5\% mIoU gains on G-Ref val set). Our codes will be released at: https://github.com/Kimsure/TALENT.
Unbiased Semantic Decoding with Vision Foundation Models for Few-shot Segmentation
Nov 19, 2025Few-shot segmentation has garnered significant attention. Many recent approaches attempt to introduce the Segment Anything Model (SAM) to handle this task. With the strong generalization ability and rich object-specific extraction ability of the SAM model, such a solution shows great potential in few-shot segmentation. However, the decoding process of SAM highly relies on accurate and explicit prompts, making previous approaches mainly focus on extracting prompts from the support set, which is insufficient to activate the generalization ability of SAM, and this design is easy to result in a biased decoding process when adapting to the unknown classes. In this work, we propose an Unbiased Semantic Decoding (USD) strategy integrated with SAM, which extracts target information from both the support and query set simultaneously to perform consistent predictions guided by the semantics of the Contrastive Language-Image Pre-training (CLIP) model. Specifically, to enhance the unbiased semantic discrimination of SAM, we design two feature enhancement strategies that leverage the semantic alignment capability of CLIP to enrich the original SAM features, mainly including a global supplement at the image level to provide a generalize category indicate with support image and a local guidance at the pixel level to provide a useful target location with query image. Besides, to generate target-focused prompt embeddings, a learnable visual-text target prompt generator is proposed by interacting target text embeddings and clip visual features. Without requiring re-training of the vision foundation models, the features with semantic discrimination draw attention to the target region through the guidance of prompt with rich target information.
HCC-3D: Hierarchical Compensatory Compression for 98% 3D Token Reduction in Vision-Language Models
Nov 13, 20253D understanding has drawn significant attention recently, leveraging Vision-Language Models (VLMs) to enable multi-modal reasoning between point cloud and text data. Current 3D-VLMs directly embed the 3D point clouds into 3D tokens, following large 2D-VLMs with powerful reasoning capabilities. However, this framework has a great computational cost limiting its application, where we identify that the bottleneck lies in processing all 3D tokens in the Large Language Model (LLM) part. This raises the question: how can we reduce the computational overhead introduced by 3D tokens while preserving the integrity of their essential information? To address this question, we introduce Hierarchical Compensatory Compression (HCC-3D) to efficiently compress 3D tokens while maintaining critical detail retention. Specifically, we first propose a global structure compression (GSC), in which we design global queries to compress all 3D tokens into a few key tokens while keeping overall structural information. Then, to compensate for the information loss in GSC, we further propose an adaptive detail mining (ADM) module that selectively recompresses salient but under-attended features through complementary scoring. Extensive experiments demonstrate that HCC-3D not only achieves extreme compression ratios (approximately 98%) compared to previous 3D-VLMs, but also achieves new state-of-the-art performance, showing the great improvements on both efficiency and performance.
Fine-Grained Customized Fashion Design with Image-into-Prompt benchmark and dataset from LMM
Sep 11, 2025Generative AI evolves the execution of complex workflows in industry, where the large multimodal model empowers fashion design in the garment industry. Current generation AI models magically transform brainstorming into fancy designs easily, but the fine-grained customization still suffers from text uncertainty without professional background knowledge from end-users. Thus, we propose the Better Understanding Generation (BUG) workflow with LMM to automatically create and fine-grain customize the cloth designs from chat with image-into-prompt. Our framework unleashes users' creative potential beyond words and also lowers the barriers of clothing design/editing without further human involvement. To prove the effectiveness of our model, we propose a new FashionEdit dataset that simulates the real-world clothing design workflow, evaluated from generation similarity, user satisfaction, and quality. The code and dataset: https://github.com/detectiveli/FashionEdit.
A Training-free Synthetic Data Selection Method for Semantic Segmentation
Jan 25, 2025



Training semantic segmenter with synthetic data has been attracting great attention due to its easy accessibility and huge quantities. Most previous methods focused on producing large-scale synthetic image-annotation samples and then training the segmenter with all of them. However, such a solution remains a main challenge in that the poor-quality samples are unavoidable, and using them to train the model will damage the training process. In this paper, we propose a training-free Synthetic Data Selection (SDS) strategy with CLIP to select high-quality samples for building a reliable synthetic dataset. Specifically, given massive synthetic image-annotation pairs, we first design a Perturbation-based CLIP Similarity (PCS) to measure the reliability of synthetic image, thus removing samples with low-quality images. Then we propose a class-balance Annotation Similarity Filter (ASF) by comparing the synthetic annotation with the response of CLIP to remove the samples related to low-quality annotations. The experimental results show that using our method significantly reduces the data size by half, while the trained segmenter achieves higher performance. The code is released at https://github.com/tanghao2000/SDS.
Frozen CLIP: A Strong Backbone for Weakly Supervised Semantic Segmentation
Jun 17, 2024Weakly supervised semantic segmentation has witnessed great achievements with image-level labels. Several recent approaches use the CLIP model to generate pseudo labels for training an individual segmentation model, while there is no attempt to apply the CLIP model as the backbone to directly segment objects with image-level labels. In this paper, we propose WeCLIP, a CLIP-based single-stage pipeline, for weakly supervised semantic segmentation. Specifically, the frozen CLIP model is applied as the backbone for semantic feature extraction, and a new decoder is designed to interpret extracted semantic features for final prediction. Meanwhile, we utilize the above frozen backbone to generate pseudo labels for training the decoder. Such labels cannot be optimized during training. We then propose a refinement module (RFM) to rectify them dynamically. Our architecture enforces the proposed decoder and RFM to benefit from each other to boost the final performance. Extensive experiments show that our approach significantly outperforms other approaches with less training cost. Additionally, our WeCLIP also obtains promising results for fully supervised settings. The code is available at https://github.com/zbf1991/WeCLIP.
* CVPR 2024 Highlight
Rethinking Prior Information Generation with CLIP for Few-Shot Segmentation
May 14, 2024Few-shot segmentation remains challenging due to the limitations of its labeling information for unseen classes. Most previous approaches rely on extracting high-level feature maps from the frozen visual encoder to compute the pixel-wise similarity as a key prior guidance for the decoder. However, such a prior representation suffers from coarse granularity and poor generalization to new classes since these high-level feature maps have obvious category bias. In this work, we propose to replace the visual prior representation with the visual-text alignment capacity to capture more reliable guidance and enhance the model generalization. Specifically, we design two kinds of training-free prior information generation strategy that attempts to utilize the semantic alignment capability of the Contrastive Language-Image Pre-training model (CLIP) to locate the target class. Besides, to acquire more accurate prior guidance, we build a high-order relationship of attention maps and utilize it to refine the initial prior information. Experiments on both the PASCAL-5{i} and COCO-20{i} datasets show that our method obtains a clearly substantial improvement and reaches the new state-of-the-art performance.
Adaptive Bidirectional Displacement for Semi-Supervised Medical Image Segmentation
May 01, 2024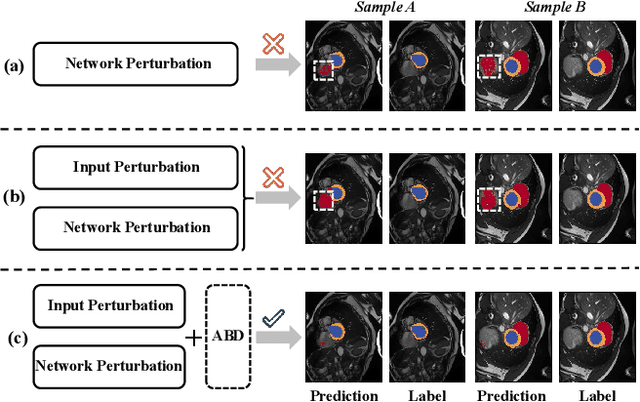
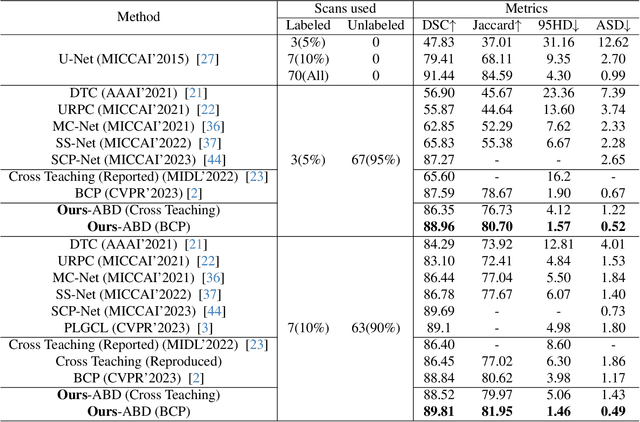
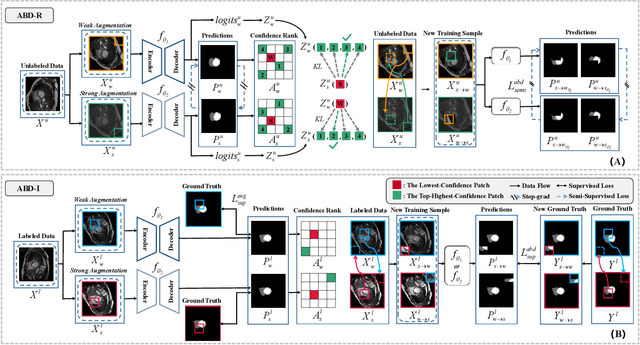
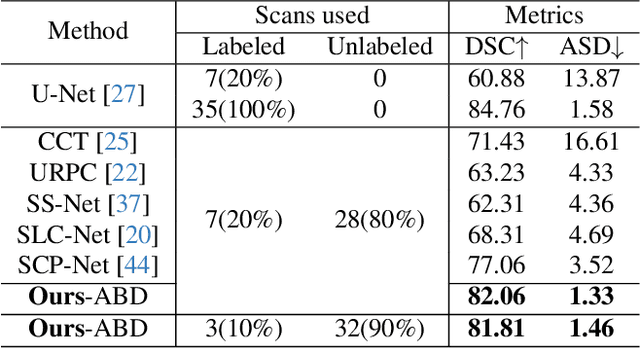
Consistency learning is a central strategy to tackle unlabeled data in semi-supervised medical image segmentation (SSMIS), which enforces the model to produce consistent predictions under the perturbation. However, most current approaches solely focus on utilizing a specific single perturbation, which can only cope with limited cases, while employing multiple perturbations simultaneously is hard to guarantee the quality of consistency learning. In this paper, we propose an Adaptive Bidirectional Displacement (ABD) approach to solve the above challenge. Specifically, we first design a bidirectional patch displacement based on reliable prediction confidence for unlabeled data to generate new samples, which can effectively suppress uncontrollable regions and still retain the influence of input perturbations. Meanwhile, to enforce the model to learn the potentially uncontrollable content, a bidirectional displacement operation with inverse confidence is proposed for the labeled images, which generates samples with more unreliable information to facilitate model learning. Extensive experiments show that ABD achieves new state-of-the-art performances for SSMIS, significantly improving different baselines. Source code is available at https://github.com/chy-upc/ABD.