 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Asynchronous Two-Speed Kalman Filter for Real-Time UUV Cooperative Navigation Under Acoustic Delays
Apr 03, 2026In GNSS-denied underwater environments, individual unmanned underwater vehicles (UUVs) suffer from unbounded dead-reckoning drift, making collaborative navigation crucial for accurate state estimation. However, the severe communication delay inherent in underwater acoustic channels poses serious challenges to real-time state estimation. Traditional filters, such as Extended Kalman Filters (EKF) or Unscented Kalman Filters (UKF), usually block the main control loop while waiting for delayed data, or completely discard Out-of-Sequence Measurements (OOSM), resulting in serious drift. To address this, we propose an Asynchronous Two-Speed Kalman Filter (TSKF) enhanced by a novel projection mechanism, which we term Variational History Distillation (VHD). The proposed architecture decouples the estimation process into two parallel threads: a fast-rate thread that utilizes Gaussian Process (GP) compensated dead reckoning to guarantee high-frequency real-time control, and a slow-rate thread dedicated to processing asynchronously delayed collaborative information. By introducing a finite-length State Buffer, the algorithm applies delayed measurements (t-T) to their corresponding historical states, and utilizes a VHD-based projection to fast-forward the correction to the current time without computationally heavy recalculations. Simulation results demonstrate that the proposed TSKF maintains trajectory Root Mean Square Error (RMSE) comparable to computationally intensive batch-optimization methods under severe delays (up to 30 s). Executing in sub-millisecond time, it significantly outperforms standard EKF/UKF. The results demonstrate an effective control, communication, and computing (3C) co-design that significantly enhances the resilience of autonomous marine automation systems.
Communication Outage-Resistant UUV State Estimation: A Variational History Distillation Approach
Mar 31, 2026The reliable operation of Unmanned Underwater Vehicle (UUV) clusters is highly dependent on continuous acoustic communication. However, this communication method is highly susceptible to intermittent interruptions. When communication outages occur, standard state estimators such as the Unscented Kalman Filter (UKF) will be forced to make open-loop predictions. If the environment contains unmodeled dynamic factors, such as unknown ocean currents, this estimation error will grow rapidly, which may eventually lead to mission failure. To address this critical issue, this paper proposes a Variational History Distillation (VHD) approach. VHD regards trajectory prediction as an approximate Bayesian reasoning process, which links a standard motion model based on physics with a pattern extracted directly from the past trajectory of the UUV. This is achieved by synthesizing ``virtual measurements'' distilled from historical trajectories. Recognizing that the reliability of extrapolated historical trends degrades over extended prediction horizons, an adaptive confidence mechanism is introduced. This mechanism allows the filter to gradually reduce the trust of virtual measurements as the communication outage time is extended. Extensive Monte Carlo simulations in a high-fidelity environment demonstrate that the proposed method achieves a 91\% reduction in prediction Root Mean Square Error (RMSE), reducing the error from approximately 170 m to 15 m during a 40-second communication outage. These results demonstrate that VHD can maintain robust state estimation performance even under complete communication loss.
From High-SNR Radar Signal to ECG: A Transfer Learning Model with Cardio-Focusing Algorithm for Scenarios with Limited Data
Jun 24, 2025Electrocardiogram (ECG), as a crucial find-grained cardiac feature, has been successfully recovered from radar signals in the literature, but the performance heavily relies on the high-quality radar signal and numerous radar-ECG pairs for training, restricting the applications in new scenarios due to data scarcity. Therefore, this work will focus on radar-based ECG recovery in new scenarios with limited data and propose a cardio-focusing and -tracking (CFT) algorithm to precisely track the cardiac location to ensure an efficient acquisition of high-quality radar signals. Furthermore, a transfer learning model (RFcardi) is proposed to extract cardio-related information from the radar signal without ECG ground truth based on the intrinsic sparsity of cardiac features, and only a few synchronous radar-ECG pairs are required to fine-tune the pre-trained model for the ECG recovery. The experimental results reveal that the proposed CFT can dynamically identify the cardiac location, and the RFcardi model can effectively generate faithful ECG recoveries after using a small number of radar-ECG pairs for training. The code and dataset are available after the publication.
HiGarment: Cross-modal Harmony Based Diffusion Model for Flat Sketch to Realistic Garment Image
May 29, 2025

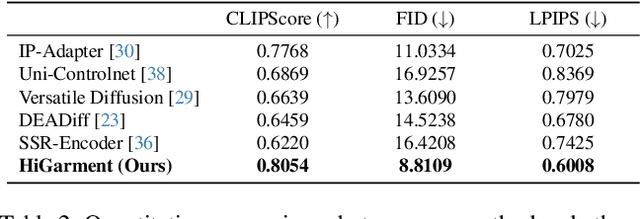

Diffusion-based garment synthesis tasks primarily focus on the design phase in the fashion domain, while the garment production process remains largely underexplored. To bridge this gap, we introduce a new task: Flat Sketch to Realistic Garment Image (FS2RG), which generates realistic garment images by integrating flat sketches and textual guidance. FS2RG presents two key challenges: 1) fabric characteristics are solely guided by textual prompts, providing insufficient visual supervision for diffusion-based models, which limits their ability to capture fine-grained fabric details; 2) flat sketches and textual guidance may provide conflicting information, requiring the model to selectively preserve or modify garment attributes while maintaining structural coherence. To tackle this task, we propose HiGarment, a novel framework that comprises two core components: i) a multi-modal semantic enhancement mechanism that enhances fabric representation across textual and visual modalities, and ii) a harmonized cross-attention mechanism that dynamically balances information from flat sketches and text prompts, allowing controllable synthesis by generating either sketch-aligned (image-biased) or text-guided (text-biased) outputs. Furthermore, we collect Multi-modal Detailed Garment, the largest open-source dataset for garment generation. Experimental results and user studies demonstrate the effectiveness of HiGarment in garment synthesis. The code and dataset will be released.
Supervised Visual Docking Network for Unmanned Surface Vehicles Using Auto-labeling in Real-world Water Environments
Mar 05, 2025Unmanned Surface Vehicles (USVs) are increasingly applied to water operations such as environmental monitoring and river-map modeling. It faces a significant challenge in achieving precise autonomous docking at ports or stations, still relying on remote human control or external positioning systems for accuracy and safety which limits the full potential of human-out-of-loop deployment for USVs.This paper introduces a novel supervised learning pipeline with the auto-labeling technique for USVs autonomous visual docking. Firstly, we designed an auto-labeling data collection pipeline that appends relative pose and image pair to the dataset. This step does not require conventional manual labeling for supervised learning. Secondly, the Neural Dock Pose Estimator (NDPE) is proposed to achieve relative dock pose prediction without the need for hand-crafted feature engineering, camera calibration, and peripheral markers. Moreover, The NDPE can accurately predict the relative dock pose in real-world water environments, facilitating the implementation of Position-Based Visual Servo (PBVS) and low-level motion controllers for efficient and autonomous docking.Experiments show that the NDPE is robust to the disturbance of the distance and the USV velocity. The effectiveness of our proposed solution is tested and validated in real-world water environments, reflecting its capability to handle real-world autonomous docking tasks.
Communication Strategy on Macro-and-Micro Traffic State in Cooperative Deep Reinforcement Learning for Regional Traffic Signal Control
Feb 18, 2025Adaptive Traffic Signal Control (ATSC) has become a popular research topic in intelligent transportation systems. Regional Traffic Signal Control (RTSC) using the Multi-agent Deep Reinforcement Learning (MADRL) technique has become a promising approach for ATSC due to its ability to achieve the optimum trade-off between scalability and optimality. Most existing RTSC approaches partition a traffic network into several disjoint regions, followed by applying centralized reinforcement learning techniques to each region. However, the pursuit of cooperation among RTSC agents still remains an open issue and no communication strategy for RTSC agents has been investigated. In this paper, we propose communication strategies to capture the correlation of micro-traffic states among lanes and the correlation of macro-traffic states among intersections. We first justify the evolution equation of the RTSC process is Markovian via a system of store-and-forward queues. Next, based on the evolution equation, we propose two GAT-Aggregated (GA2) communication modules--GA2-Naive and GA2-Aug to extract both intra-region and inter-region correlations between macro and micro traffic states. While GA2-Naive only considers the movements at each intersection, GA2-Aug also considers the lane-changing behavior of vehicles. Two proposed communication modules are then aggregated into two existing novel RTSC frameworks--RegionLight and Regional-DRL. Experimental results demonstrate that both GA2-Naive and GA2-Aug effectively improve the performance of existing RTSC frameworks under both real and synthetic scenarios. Hyperparameter testing also reveals the robustness and potential of our communication modules in large-scale traffic networks.
CNC: Cross-modal Normality Constraint for Unsupervised Multi-class Anomaly Detection
Dec 31, 2024



Existing unsupervised distillation-based methods rely on the differences between encoded and decoded features to locate abnormal regions in test images. However, the decoder trained only on normal samples still reconstructs abnormal patch features well, degrading performance. This issue is particularly pronounced in unsupervised multi-class anomaly detection tasks. We attribute this behavior to over-generalization(OG) of decoder: the significantly increasing diversity of patch patterns in multi-class training enhances the model generalization on normal patches, but also inadvertently broadens its generalization to abnormal patches. To mitigate OG, we propose a novel approach that leverages class-agnostic learnable prompts to capture common textual normality across various visual patterns, and then apply them to guide the decoded features towards a normal textual representation, suppressing over-generalization of the decoder on abnormal patterns. To further improve performance, we also introduce a gated mixture-of-experts module to specialize in handling diverse patch patterns and reduce mutual interference between them in multi-class training. Our method achieves competitive performance on the MVTec AD and VisA datasets, demonstrating its effectiveness.
VMGNet: A Low Computational Complexity Robotic Grasping Network Based on VMamba with Multi-Scale Feature Fusion
Nov 19, 2024



While deep learning-based robotic grasping technology has demonstrated strong adaptability, its computational complexity has also significantly increased, making it unsuitable for scenarios with high real-time requirements. Therefore, we propose a low computational complexity and high accuracy model named VMGNet for robotic grasping. For the first time, we introduce the Visual State Space into the robotic grasping field to achieve linear computational complexity, thereby greatly reducing the model's computational cost. Meanwhile, to improve the accuracy of the model, we propose an efficient and lightweight multi-scale feature fusion module, named Fusion Bridge Module, to extract and fuse information at different scales. We also present a new loss function calculation method to enhance the importance differences between subtasks, improving the model's fitting ability. Experiments show that VMGNet has only 8.7G Floating Point Operations and an inference time of 8.1 ms on our devices. VMGNet also achieved state-of-the-art performance on the Cornell and Jacquard public datasets. To validate VMGNet's effectiveness in practical applications, we conducted real grasping experiments in multi-object scenarios, and VMGNet achieved an excellent performance with a 94.4% success rate in real-world grasping tasks. The video for the real-world robotic grasping experiments is available at https://youtu.be/S-QHBtbmLc4.
A Novel Approach to Grasping Control of Soft Robotic Grippers based on Digital Twin
Oct 19, 2024



This paper has proposed a Digital Twin (DT) framework for real-time motion and pose control of soft robotic grippers. The developed DT is based on an industrial robot workstation, integrated with our newly proposed approach for soft gripper control, primarily based on computer vision, for setting the driving pressure for desired gripper status in real-time. Knowing the gripper motion, the gripper parameters (e.g. curvatures and bending angles, etc.) are simulated by kinematics modelling in Unity 3D, which is based on four-piecewise constant curvature kinematics. The mapping in between the driving pressure and gripper parameters is achieved by implementing OpenCV based image processing algorithms and data fitting. Results show that our DT-based approach can achieve satisfactory performance in real-time control of soft gripper manipulation, which can satisfy a wide range of industrial applications.
radarODE-MTL: A Multi-Task Learning Framework with Eccentric Gradient Alignment for Robust Radar-Based ECG Reconstruction
Oct 11, 2024



Millimeter-wave radar is promising to provide robust and accurate vital sign monitoring in an unobtrusive manner. However, the radar signal might be distorted in propagation by ambient noise or random body movement, ruining the subtle cardiac activities and destroying the vital sign recovery. In particular, the recovery of electrocardiogram (ECG) signal heavily relies on the deep-learning model and is sensitive to noise. Therefore, this work creatively deconstructs the radar-based ECG recovery into three individual tasks and proposes a multi-task learning (MTL) framework, radarODE-MTL, to increase the robustness against consistent and abrupt noises. In addition, to alleviate the potential conflicts in optimizing individual tasks, a novel multi-task optimization strategy, eccentric gradient alignment (EGA), is proposed to dynamically trim the task-specific gradients based on task difficulties in orthogonal space. The proposed radarODE-MTL with EGA is evaluated on the public dataset with prominent improvements in accuracy, and the performance remains consistent under noises. The experimental results indicate that radarODE-MTL could reconstruct accurate ECG signals robustly from radar signals and imply the application prospect in real-life situations. The code is available at: http://github.com/ZYY0844/radarODE-MTL.