 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Safety Report on GPT-5.2, Gemini 3 Pro, Qwen3-VL, Grok 4.1 Fast, Nano Banana Pro, and Seedream 4.5
Jan 16, 2026The rapid evolution of Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) has driven major gains in reasoning, perception, and generation across language and vision, yet whether these advances translate into comparable improvements in safety remains unclear, partly due to fragmented evaluations that focus on isolated modalities or threat models. In this report, we present an integrated safety evaluation of six frontier models--GPT-5.2, Gemini 3 Pro, Qwen3-VL, Grok 4.1 Fast, Nano Banana Pro, and Seedream 4.5--assessing each across language, vision-language, and image generation using a unified protocol that combines benchmark, adversarial, multilingual, and compliance evaluations. By aggregating results into safety leaderboards and model profiles, we reveal a highly uneven safety landscape: while GPT-5.2 demonstrates consistently strong and balanced performance, other models exhibit clear trade-offs across benchmark safety, adversarial robustness, multilingual generalization, and regulatory compliance. Despite strong results under standard benchmarks, all models remain highly vulnerable under adversarial testing, with worst-case safety rates dropping below 6%. Text-to-image models show slightly stronger alignment in regulated visual risk categories, yet remain fragile when faced with adversarial or semantically ambiguous prompts. Overall, these findings highlight that safety in frontier models is inherently multidimensional--shaped by modality, language, and evaluation design--underscoring the need for standardized, holistic safety assessments to better reflect real-world risk and guide responsible deployment.
Wavelet-based Multi-View Fusion of 4D Radar Tensor and Camera for Robust 3D Object Detection
Dec 28, 20254D millimeter-wave (mmWave) radar has been widely adopted in autonomous driving and robot perception due to its low cost and all-weather robustness. However, its inherent sparsity and limited semantic richness significantly constrain perception capability. Recently, fusing camera data with 4D radar has emerged as a promising cost effective solution, by exploiting the complementary strengths of the two modalities. Nevertheless, point-cloud-based radar often suffer from information loss introduced by multi-stage signal processing, while directly utilizing raw 4D radar data incurs prohibitive computational costs. To address these challenges, we propose WRCFormer, a novel 3D object detection framework that fuses raw radar cubes with camera inputs via multi-view representations of the decoupled radar cube. Specifically, we design a Wavelet Attention Module as the basic module of wavelet-based Feature Pyramid Network (FPN) to enhance the representation of sparse radar signals and image data. We further introduce a two-stage query-based, modality-agnostic fusion mechanism termed Geometry-guided Progressive Fusion to efficiently integrate multi-view features from both modalities. Extensive experiments demonstrate that WRCFormer achieves state-of-the-art performance on the K-Radar benchmarks, surpassing the best model by approximately 2.4% in all scenarios and 1.6% in the sleet scenario, highlighting its robustness under adverse weather conditions.
Unsupervised Radar Point Cloud Enhancement via Arbitrary LiDAR Guided Diffusion Prior
May 15, 2025In industrial automation, radar is a critical sensor in machine perception. However, the angular resolution of radar is inherently limited by the Rayleigh criterion, which depends on both the radar's operating wavelength and the effective aperture of its antenna array.To overcome these hardware-imposed limitations, recent neural network-based methods have leveraged high-resolution LiDAR data, paired with radar measurements, during training to enhance radar point cloud resolution. While effective, these approaches require extensive paired datasets, which are costly to acquire and prone to calibration error. These challenges motivate the need for methods that can improve radar resolution without relying on paired high-resolution ground-truth data. Here, we introduce an unsupervised radar points enhancement algorithm that employs an arbitrary LiDAR-guided diffusion model as a prior without the need for paired training data. Specifically, our approach formulates radar angle estimation recovery as an inverse problem and incorporates prior knowledge through a diffusion model with arbitrary LiDAR domain knowledge. Experimental results demonstrate that our method attains high fidelity and low noise performance compared to traditional regularization techniques. Additionally, compared to paired training methods, it not only achieves comparable performance but also offers improved generalization capability. To our knowledge, this is the first approach that enhances radar points output by integrating prior knowledge via a diffusion model rather than relying on paired training data. Our code is available at https://github.com/yyxr75/RadarINV.
MS-Occ: Multi-Stage LiDAR-Camera Fusion for 3D Semantic Occupancy Prediction
Apr 22, 2025Accurate 3D semantic occupancy perception is essential for autonomous driving in complex environments with diverse and irregular objects. While vision-centric methods suffer from geometric inaccuracies, LiDAR-based approaches often lack rich semantic information. To address these limitations, MS-Occ, a novel multi-stage LiDAR-camera fusion framework which includes middle-stage fusion and late-stage fusion, is proposed, integrating LiDAR's geometric fidelity with camera-based semantic richness via hierarchical cross-modal fusion. The framework introduces innovations at two critical stages: (1) In the middle-stage feature fusion, the Gaussian-Geo module leverages Gaussian kernel rendering on sparse LiDAR depth maps to enhance 2D image features with dense geometric priors, and the Semantic-Aware module enriches LiDAR voxels with semantic context via deformable cross-attention; (2) In the late-stage voxel fusion, the Adaptive Fusion (AF) module dynamically balances voxel features across modalities, while the High Classification Confidence Voxel Fusion (HCCVF) module resolves semantic inconsistencies using self-attention-based refinement. Experiments on the nuScenes-OpenOccupancy benchmark show that MS-Occ achieves an Intersection over Union (IoU) of 32.1% and a mean IoU (mIoU) of 25.3%, surpassing the state-of-the-art by +0.7% IoU and +2.4% mIoU. Ablation studies further validate the contribution of each module, with substantial improvements in small-object perception, demonstrating the practical value of MS-Occ for safety-critical autonomous driving scenarios.
Talk2PC: Enhancing 3D Visual Grounding through LiDAR and Radar Point Clouds Fusion for Autonomous Driving
Mar 11, 2025Embodied outdoor scene understanding forms the foundation for autonomous agents to perceive, analyze, and react to dynamic driving environments. However, existing 3D understanding is predominantly based on 2D Vision-Language Models (VLMs), collecting and processing limited scene-aware contexts. Instead, compared to the 2D planar visual information, point cloud sensors like LiDAR offer rich depth information and fine-grained 3D representations of objects. Meanwhile, the emerging 4D millimeter-wave (mmWave) radar is capable of detecting the motion trend, velocity, and reflection intensity of each object. Therefore, the integration of these two modalities provides more flexible querying conditions for natural language, enabling more accurate 3D visual grounding. To this end, in this paper, we exploratively propose a novel method called TPCNet, the first outdoor 3D visual grounding model upon the paradigm of prompt-guided point cloud sensor combination, including both LiDAR and radar contexts. To adaptively balance the features of these two sensors required by the prompt, we have designed a multi-fusion paradigm called Two-Stage Heterogeneous Modal Adaptive Fusion. Specifically, this paradigm initially employs Bidirectional Agent Cross-Attention (BACA), which feeds dual-sensor features, characterized by global receptive fields, to the text features for querying. Additionally, we have designed a Dynamic Gated Graph Fusion (DGGF) module to locate the regions of interest identified by the queries. To further enhance accuracy, we innovatively devise an C3D-RECHead, based on the nearest object edge. Our experiments have demonstrated that our TPCNet, along with its individual modules, achieves the state-of-the-art performance on both the Talk2Radar and Talk2Car datasets.
Doracamom: Joint 3D Detection and Occupancy Prediction with Multi-view 4D Radars and Cameras for Omnidirectional Perception
Jan 26, 2025



3D object detection and occupancy prediction are critical tasks in autonomous driving, attracting significant attention. Despite the potential of recent vision-based methods, they encounter challenges under adverse conditions. Thus, integrating cameras with next-generation 4D imaging radar to achieve unified multi-task perception is highly significant, though research in this domain remains limited. In this paper, we propose Doracamom, the first framework that fuses multi-view cameras and 4D radar for joint 3D object detection and semantic occupancy prediction, enabling comprehensive environmental perception. Specifically, we introduce a novel Coarse Voxel Queries Generator that integrates geometric priors from 4D radar with semantic features from images to initialize voxel queries, establishing a robust foundation for subsequent Transformer-based refinement. To leverage temporal information, we design a Dual-Branch Temporal Encoder that processes multi-modal temporal features in parallel across BEV and voxel spaces, enabling comprehensive spatio-temporal representation learning. Furthermore, we propose a Cross-Modal BEV-Voxel Fusion module that adaptively fuses complementary features through attention mechanisms while employing auxiliary tasks to enhance feature quality. Extensive experiments on the OmniHD-Scenes, View-of-Delft (VoD), and TJ4DRadSet datasets demonstrate that Doracamom achieves state-of-the-art performance in both tasks, establishing new benchmarks for multi-modal 3D perception. Code and models will be publicly available.
OmniHD-Scenes: A Next-Generation Multimodal Dataset for Autonomous Driving
Dec 14, 2024

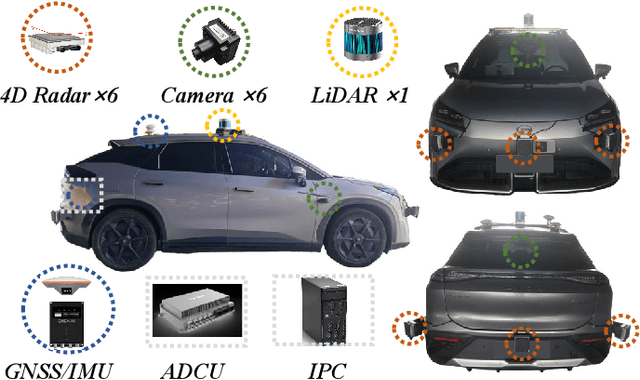

The rapid advancement of deep learning has intensified the need for comprehensive data for use by autonomous driving algorithms. High-quality datasets are crucial for the development of effective data-driven autonomous driving solutions. Next-generation autonomous driving datasets must be multimodal, incorporating data from advanced sensors that feature extensive data coverage, detailed annotations, and diverse scene representation. To address this need, we present OmniHD-Scenes, a large-scale multimodal dataset that provides comprehensive omnidirectional high-definition data. The OmniHD-Scenes dataset combines data from 128-beam LiDAR, six cameras, and six 4D imaging radar systems to achieve full environmental perception. The dataset comprises 1501 clips, each approximately 30-s long, totaling more than 450K synchronized frames and more than 5.85 million synchronized sensor data points. We also propose a novel 4D annotation pipeline. To date, we have annotated 200 clips with more than 514K precise 3D bounding boxes. These clips also include semantic segmentation annotations for static scene elements. Additionally, we introduce a novel automated pipeline for generation of the dense occupancy ground truth, which effectively leverages information from non-key frames. Alongside the proposed dataset, we establish comprehensive evaluation metrics, baseline models, and benchmarks for 3D detection and semantic occupancy prediction. These benchmarks utilize surround-view cameras and 4D imaging radar to explore cost-effective sensor solutions for autonomous driving applications. Extensive experiments demonstrate the effectiveness of our low-cost sensor configuration and its robustness under adverse conditions. Data will be released at https://www.2077ai.com/OmniHD-Scenes.
NanoMVG: USV-Centric Low-Power Multi-Task Visual Grounding based on Prompt-Guided Camera and 4D mmWave Radar
Aug 30, 2024



Recently, visual grounding and multi-sensors setting have been incorporated into perception system for terrestrial autonomous driving systems and Unmanned Surface Vehicles (USVs), yet the high complexity of modern learning-based visual grounding model using multi-sensors prevents such model to be deployed on USVs in the real-life. To this end, we design a low-power multi-task model named NanoMVG for waterway embodied perception, guiding both camera and 4D millimeter-wave radar to locate specific object(s) through natural language. NanoMVG can perform both box-level and mask-level visual grounding tasks simultaneously. Compared to other visual grounding models, NanoMVG achieves highly competitive performance on the WaterVG dataset, particularly in harsh environments and boasts ultra-low power consumption for long endurance.
Talk2Radar: Bridging Natural Language with 4D mmWave Radar for 3D Referring Expression Comprehension
May 21, 2024



Embodied perception is essential for intelligent vehicles and robots, enabling more natural interaction and task execution. However, these advancements currently embrace vision level, rarely focusing on using 3D modeling sensors, which limits the full understanding of surrounding objects with multi-granular characteristics. Recently, as a promising automotive sensor with affordable cost, 4D Millimeter-Wave radar provides denser point clouds than conventional radar and perceives both semantic and physical characteristics of objects, thus enhancing the reliability of perception system. To foster the development of natural language-driven context understanding in radar scenes for 3D grounding, we construct the first dataset, Talk2Radar, which bridges these two modalities for 3D Referring Expression Comprehension. Talk2Radar contains 8,682 referring prompt samples with 20,558 referred objects. Moreover, we propose a novel model, T-RadarNet for 3D REC upon point clouds, achieving state-of-the-art performances on Talk2Radar dataset compared with counterparts, where Deformable-FPN and Gated Graph Fusion are meticulously designed for efficient point cloud feature modeling and cross-modal fusion between radar and text features, respectively. Further, comprehensive experiments are conducted to give a deep insight into radar-based 3D REC. We release our project at https://github.com/GuanRunwei/Talk2Radar.
ProbRadarM3F: mmWave Radar based Human Skeletal Pose Estimation with Probability Map Guided Multi-Format Feature Fusion
May 08, 2024



Millimetre wave (mmWave) radar is a non-intrusive privacy and relatively convenient and inexpensive device, which has been demonstrated to be applicable in place of RGB cameras in human indoor pose estimation tasks. However, mmWave radar relies on the collection of reflected signals from the target, and the radar signals containing information is difficult to be fully applied. This has been a long-standing hindrance to the improvement of pose estimation accuracy. To address this major challenge, this paper introduces a probability map guided multi-format feature fusion model, ProbRadarM3F. This is a novel radar feature extraction framework using a traditional FFT method in parallel with a probability map based positional encoding method. ProbRadarM3F fuses the traditional heatmap features and the positional features, then effectively achieves the estimation of 14 keypoints of the human body. Experimental evaluation on the HuPR dataset proves the effectiveness of the model proposed in this paper, outperforming other methods experimented on this dataset with an AP of 69.9 %. The emphasis of our study is focusing on the position information that is not exploited before in radar singal. This provides direction to investigate other potential non-redundant information from mmWave rader.