 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadarGaussianDet3D: An Efficient and Effective Gaussian-based 3D Detector with 4D Automotive Radars
Sep 19, 20254D automotive radars have gained increasing attention for autonomous driving due to their low cost, robustness, and inherent velocity measurement capability. However, existing 4D radar-based 3D detectors rely heavily on pillar encoders for BEV feature extraction, where each point contributes to only a single BEV grid, resulting in sparse feature maps and degraded representation quality. In addition, they also optimize bounding box attributes independently, leading to sub-optimal detection accuracy. Moreover, their inference speed, while sufficient for high-end GPUs, may fail to meet the real-time requirement on vehicle-mounted embedded devices. To overcome these limitations, an efficient and effective Gaussian-based 3D detector, namely RadarGaussianDet3D is introduced, leveraging Gaussian primitives and distributions as intermediate representations for radar points and bounding boxes. In RadarGaussianDet3D, a novel Point Gaussian Encoder (PGE) is designed to transform each point into a Gaussian primitive after feature aggregation and employs the 3D Gaussian Splatting (3DGS) technique for BEV rasterization, yielding denser feature maps. PGE exhibits exceptionally low latency, owing to the optimized algorithm for point feature aggregation and fast rendering of 3DGS. In addition, a new Box Gaussian Loss (BGL) is proposed, which converts bounding boxes into 3D Gaussian distributions and measures their distance to enable more comprehensive and consistent optimization. Extensive experiments on TJ4DRadSet and View-of-Delft demonstrate that RadarGaussianDet3D achieves state-of-the-art detection accuracy while delivering substantially faster inference, highlighting its potential for real-time deployment in autonomous driving.
LXLv2: Enhanced LiDAR Excluded Lean 3D Object Detection with Fusion of 4D Radar and Camera
Feb 20, 2025As the previous state-of-the-art 4D radar-camera fusion-based 3D object detection method, LXL utilizes the predicted image depth distribution maps and radar 3D occupancy grids to assist the sampling-based image view transformation. However, the depth prediction lacks accuracy and consistency, and the concatenation-based fusion in LXL impedes the model robustness. In this work, we propose LXLv2, where modifications are made to overcome the limitations and improve the performance. Specifically, considering the position error in radar measurements, we devise a one-to-many depth supervision strategy via radar points, where the radar cross section (RCS) value is further exploited to adjust the supervision area for object-level depth consistency. Additionally, a channel and spatial attention-based fusion module named CSAFusion is introduced to improve feature adaptiveness. Experimental results on the View-of-Delft and TJ4DRadSet datasets show that the proposed LXLv2 can outperform LXL in detection accuracy, inference speed and robustness, demonstrating the effectiveness of the model.
ProbRadarM3F: mmWave Radar based Human Skeletal Pose Estimation with Probability Map Guided Multi-Format Feature Fusion
May 08, 2024



Millimetre wave (mmWave) radar is a non-intrusive privacy and relatively convenient and inexpensive device, which has been demonstrated to be applicable in place of RGB cameras in human indoor pose estimation tasks. However, mmWave radar relies on the collection of reflected signals from the target, and the radar signals containing information is difficult to be fully applied. This has been a long-standing hindrance to the improvement of pose estimation accuracy. To address this major challenge, this paper introduces a probability map guided multi-format feature fusion model, ProbRadarM3F. This is a novel radar feature extraction framework using a traditional FFT method in parallel with a probability map based positional encoding method. ProbRadarM3F fuses the traditional heatmap features and the positional features, then effectively achieves the estimation of 14 keypoints of the human body. Experimental evaluation on the HuPR dataset proves the effectiveness of the model proposed in this paper, outperforming other methods experimented on this dataset with an AP of 69.9 %. The emphasis of our study is focusing on the position information that is not exploited before in radar singal. This provides direction to investigate other potential non-redundant information from mmWave rader.
SMURF: Spatial Multi-Representation Fusion for 3D Object Detection with 4D Imaging Radar
Aug 02, 2023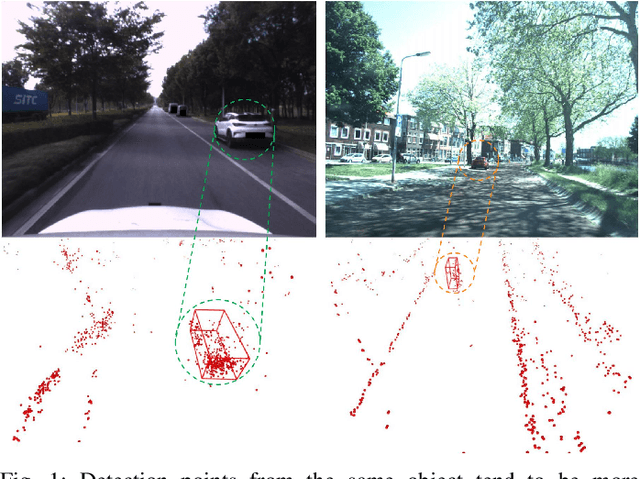
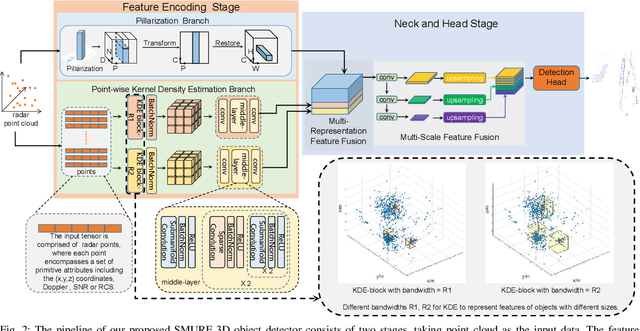

The 4D Millimeter wave (mmWave) radar is a promising technology for vehicle sensing due to its cost-effectiveness and operability in adverse weather conditions. However, the adoption of this technology has been hindered by sparsity and noise issues in radar point cloud data. This paper introduces spatial multi-representation fusion (SMURF), a novel approach to 3D object detection using a single 4D imaging radar. SMURF leverages multiple representations of radar detection points, including pillarization and density features of a multi-dimensional Gaussian mixture distribution through kernel density estimation (KDE). KDE effectively mitigates measurement inaccuracy caused by limited angular resolution and multi-path propagation of radar signals. Additionally, KDE helps alleviate point cloud sparsity by capturing density features. Experimental evaluations on View-of-Delft (VoD) and TJ4DRadSet datasets demonstrate the effectiveness and generalization ability of SMURF, outperforming recently proposed 4D imaging radar-based single-representation models. Moreover, while using 4D imaging radar only, SMURF still achieves comparable performance to the state-of-the-art 4D imaging radar and camera fusion-based method, with an increase of 1.22% in the mean average precision on bird's-eye view of TJ4DRadSet dataset and 1.32% in the 3D mean average precision on the entire annotated area of VoD dataset. Our proposed method demonstrates impressive inference time and addresses the challenges of real-time detection, with the inference time no more than 0.05 seconds for most scans on both datasets. This research highlights the benefits of 4D mmWave radar and is a strong benchmark for subsequent works regarding 3D object detection with 4D imaging radar.
LXL: LiDAR Excluded Lean 3D Object Detection with 4D Imaging Radar and Camera Fusion
Jul 07, 2023



As an emerging technology and a relatively affordable device, the 4D imaging radar has already been confirmed effective in performing 3D object detection in autonomous driving. Nevertheless, the sparsity and noisiness of 4D radar point clouds hinder further performance improvement, and in-depth studies about its fusion with other modalities are lacking. On the other hand, most of the camera-based perception methods transform the extracted image perspective view features into the bird's-eye view geometrically via "depth-based splatting" proposed in Lift-Splat-Shoot (LSS), and some researchers exploit other modals such as LiDARs or ordinary automotive radars for enhancement. Recently, a few works have applied the "sampling" strategy for image view transformation, showing that it outperforms "splatting" even without image depth prediction. However, the potential of "sampling" is not fully unleashed. In this paper, we investigate the "sampling" view transformation strategy on the camera and 4D imaging radar fusion-based 3D object detection. In the proposed model, LXL, predicted image depth distribution maps and radar 3D occupancy grids are utilized to aid image view transformation, called "radar occupancy-assisted depth-based sampling". Experiments on VoD and TJ4DRadSet datasets show that the proposed method outperforms existing 3D object detection methods by a significant margin without bells and whistles. Ablation studies demonstrate that our method performs the best among different enhancement settings.
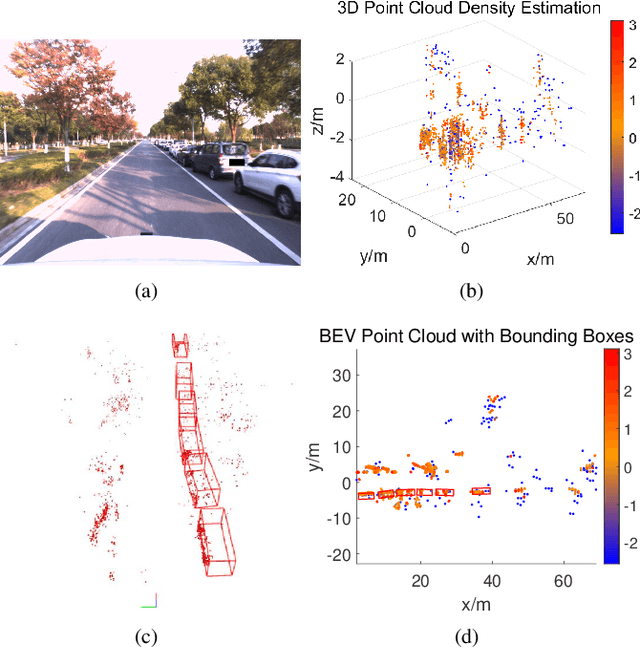
Contrastive Learning for Automotive mmWave Radar Detection Points Based Instance Segmentation
Mar 13, 2022

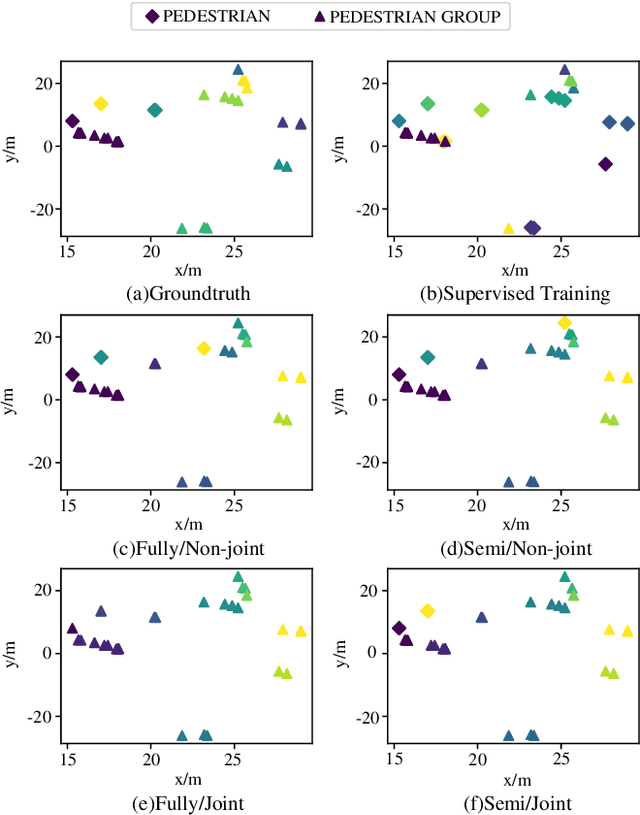
The automotive mmWave radar plays a key role in advanced driver assistance systems (ADAS) and autonomous driving. Deep learning-based instance segmentation enables real-time object identification from the radar detection points. In the conventional training process, accurate annotation is the key. However, high-quality annotations of radar detection points are challenging to achieve due to their ambiguity and sparsity. To address this issue, we propose a contrastive learning approach for implementing radar detection points-based instance segmentation. We define the positive and negative samples according to the ground-truth label, apply the contrastive loss to train the model first, and then perform training for the following downstream task. In addition, these two steps can be merged into one, and pseudo labels can be generated for the unlabeled data to improve the performance further. Thus, there are four different training settings for our method. Experiments show that when the ground-truth information is only available for 5% of the training data, our method still achieves a comparable performance to the approach trained in a supervised manner with 100% ground-truth information.
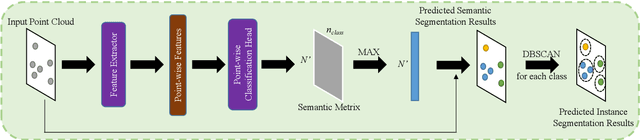
Deep Instance Segmentation with High-Resolution Automotive Radar
Oct 05, 2021
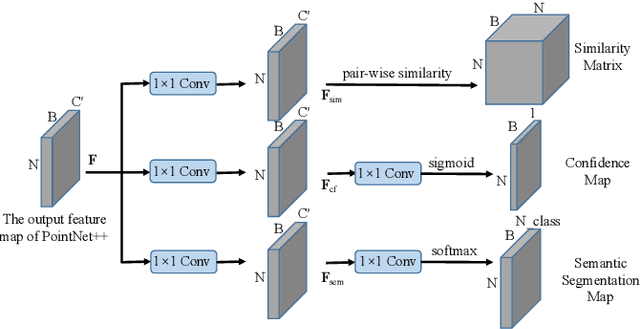
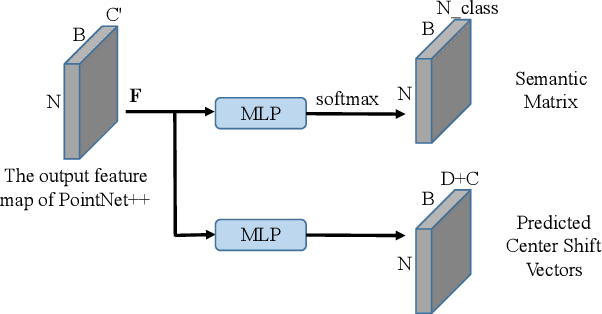
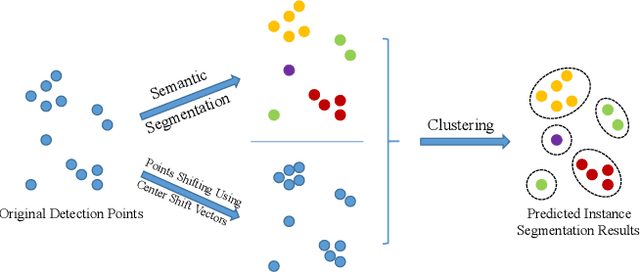
Automotive radar has been widely used in the modern advanced driver assistance systems (ADAS) and autonomous driving system as it provides reliable environmental perception in all-weather conditions with affordable cost. However, automotive radar usually only plays as an auxiliary sensor since it hardly supplies semantic and geometry information due to the sparsity of radar detection points. Nonetheless, as development of high-resolution automotive radar in recent years, more advanced perception functionality like instance segmentation which has only been well explored using Lidar point clouds, becomes possible by using automotive radar. Its data comes with rich contexts such as Radar Cross Section (RCS) and micro-doppler effects which may potentially be pertinent, and sometimes can even provide detection when the field of view is completely obscured. Therefore, the effective utilization of radar detection points data is an integral part of automotive perception. The outcome from instance segmentation could be seen as comparable result of clustering, and could be potentially used as the input of tracker for tracking the targets. In this paper, we propose two efficient methods for instance segmentation with radar detection points, one is implemented in an end-to-end deep learning driven fashion using PointNet++ framework, and the other is based on clustering of the radar detection points with semantic information. Both approaches can be further improved by implementing visual multi-layer perceptron (MLP). The effectiveness of the proposed methods is verified using experimental results on the recent RadarScenes dataset.