 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAFFormer: Adaptive Feature Fusion Transformer for V2X Cooperative Perception under Channel Impairments
May 03, 2026Accurate 3D object detection is essential for ensuring the safety of autonomous vehicles. Cooperative perception, which leverages vehicle-to-everything (V2X) communication to share perceptual data, enhances detection but is vulnerable to channel impairments, such as noise, fading, and interference. To strengthen the reliability of intelligent transportation systems, this work improves the robustness of V2X cooperative perception under communication conditions that reflect common channel impairments. This paper proposes an Adaptive Feature Fusion Transformer (AFFormer), a Transformer-based framework that mitigates the adverse effects of corrupted features by modeling temporal, inter-agent, and spatial correlations. AFFormer introduces three key modules: Multi-Agent and Temporal Aggregation for context-aware fusion across agents and over time, Dual Spatial Attention for efficient modeling of spatial dependencies, and Uncertainty-Guided Fusion for entropy-driven refinement of fused features. A teacher-student knowledge distillation strategy further enhances robustness by aligning fused features with reliable early-collaboration supervision. AFFormer is validated on the V2XSet and DAIR-V2X datasets, where it consistently outperforms existing methods under both ideal and impaired communication conditions, demonstrating improved robustness to communication-induced feature degradation while maintaining a competitive efficiency-accuracy trade-off.
Multi-Agent Systems: From Classical Paradigms to Large Foundation Model-Enabled Futures
Apr 20, 2026With the rapid advancement of artificial intelligence, multi-agent systems (MASs) are evolving from classical paradigms toward architectures built upon large foundation models (LFMs). This survey provides a systematic review and comparative analysis of classical MASs (CMASs) and LFM-based MASs (LMASs). First, within a closed-loop coordination framework, CMASs are reviewed across four fundamental dimensions: perception, communication, decision-making, and control. Beyond this framework, LMASs integrate LFMs to lift collaboration from low-level state exchanges to semantic-level reasoning, enabling more flexible coordination and improved adaptability across diverse scenarios. Then, a comparative analysis is conducted to contrast CMASs and LMASs across architecture, operating mechanism, adaptability, and application. Finally, future perspectives on MASs are presented, summarizing open challenges and potential research opportunities.
MS-Occ: Multi-Stage LiDAR-Camera Fusion for 3D Semantic Occupancy Prediction
Apr 22, 2025Accurate 3D semantic occupancy perception is essential for autonomous driving in complex environments with diverse and irregular objects. While vision-centric methods suffer from geometric inaccuracies, LiDAR-based approaches often lack rich semantic information. To address these limitations, MS-Occ, a novel multi-stage LiDAR-camera fusion framework which includes middle-stage fusion and late-stage fusion, is proposed, integrating LiDAR's geometric fidelity with camera-based semantic richness via hierarchical cross-modal fusion. The framework introduces innovations at two critical stages: (1) In the middle-stage feature fusion, the Gaussian-Geo module leverages Gaussian kernel rendering on sparse LiDAR depth maps to enhance 2D image features with dense geometric priors, and the Semantic-Aware module enriches LiDAR voxels with semantic context via deformable cross-attention; (2) In the late-stage voxel fusion, the Adaptive Fusion (AF) module dynamically balances voxel features across modalities, while the High Classification Confidence Voxel Fusion (HCCVF) module resolves semantic inconsistencies using self-attention-based refinement. Experiments on the nuScenes-OpenOccupancy benchmark show that MS-Occ achieves an Intersection over Union (IoU) of 32.1% and a mean IoU (mIoU) of 25.3%, surpassing the state-of-the-art by +0.7% IoU and +2.4% mIoU. Ablation studies further validate the contribution of each module, with substantial improvements in small-object perception, demonstrating the practical value of MS-Occ for safety-critical autonomous driving scenarios.
On the Federated Learning Framework for Cooperative Perception
Apr 26, 2024


Cooperative perception is essential to enhance the efficiency and safety of future transportation systems, requiring extensive data sharing among vehicles on the road, which raises significant privacy concerns. Federated learning offers a promising solution by enabling data privacy-preserving collaborative enhancements in perception, decision-making, and planning among connected and autonomous vehicles (CAVs). However, federated learning is impeded by significant challenges arising from data heterogeneity across diverse clients, potentially diminishing model accuracy and prolonging convergence periods. This study introduces a specialized federated learning framework for CP, termed the federated dynamic weighted aggregation (FedDWA) algorithm, facilitated by dynamic adjusting loss (DALoss) function. This framework employs dynamic client weighting to direct model convergence and integrates a novel loss function that utilizes Kullback-Leibler divergence (KLD) to counteract the detrimental effects of non-independently and identically distributed (Non-IID) and unbalanced data. Utilizing the BEV transformer as the primary model, our rigorous testing on the OpenV2V dataset, augmented with FedBEVT data, demonstrates significant improvements in the average intersection over union (IoU). These results highlight the substantial potential of our federated learning framework to address data heterogeneity challenges in CP, thereby enhancing the accuracy of environmental perception models and facilitating more robust and efficient collaborative learning solutions in the transportation sector.
V2X Cooperative Perception for Autonomous Driving: Recent Advances and Challenges
Oct 05, 2023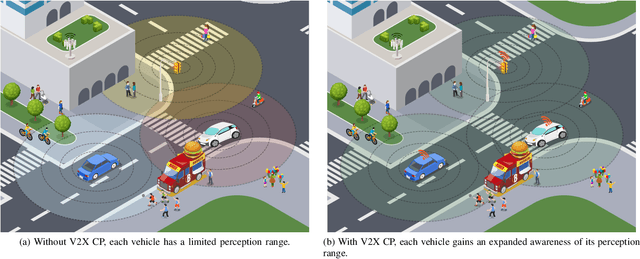
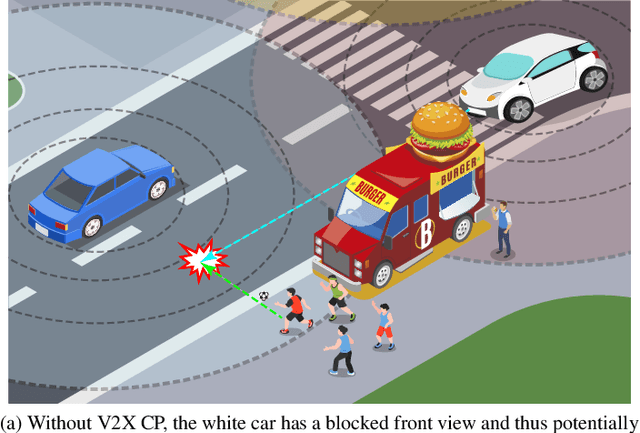
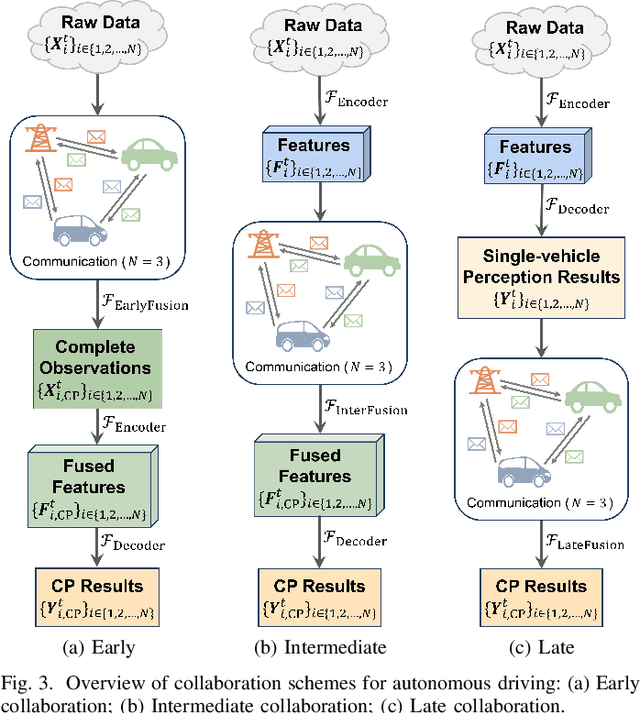
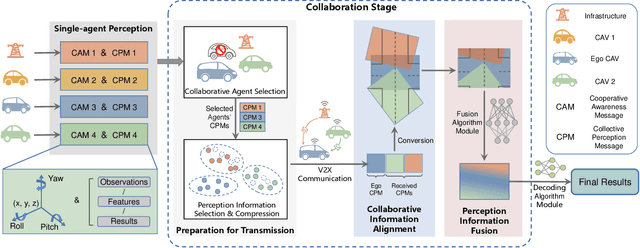
Accurate perception is essential for advancing autonomous driving and addressing safety challenges in modern transportation systems. Despite significant advancements in computer vision for object recognition, current perception methods still face difficulties in complex real-world traffic environments. Challenges such as physical occlusion and limited sensor field of view persist for individual vehicle systems. Cooperative Perception (CP) with Vehicle-to-Everything (V2X) technologies has emerged as a solution to overcome these obstacles and enhance driving automation systems. While some research has explored CP's fundamental architecture and critical components, there remains a lack of comprehensive summaries of the latest innovations, particularly in the context of V2X communication technologies. To address this gap, this paper provides a comprehensive overview of the evolution of CP technologies, spanning from early explorations to recent developments, including advancements in V2X communication technologies. Additionally, a contemporary generic framework is proposed to illustrate the V2X-based CP workflow, aiding in the structured understanding of CP system components. Furthermore, this paper categorizes prevailing V2X-based CP methodologies based on the critical issues they address. An extensive literature review is conducted within this taxonomy, evaluating existing datasets and simulators. Finally, open challenges and future directions in CP for autonomous driving are discussed by considering both perception and V2X communication advancements.
LEGO: Learning and Graph-Optimized Modular Tracker for Online Multi-Object Tracking with Point Clouds
Aug 19, 2023Online multi-object tracking (MOT) plays a pivotal role in autonomous systems. The state-of-the-art approaches usually employ a tracking-by-detection method, and data association plays a critical role. This paper proposes a learning and graph-optimized (LEGO) modular tracker to improve data association performance in the existing literature. The proposed LEGO tracker integrates graph optimization and self-attention mechanisms, which efficiently formulate the association score map, facilitating the accurate and efficient matching of objects across time frames. To further enhance the state update process, the Kalman filter is added to ensure consistent tracking by incorporating temporal coherence in the object states. Our proposed method utilizing LiDAR alone has shown exceptional performance compared to other online tracking approaches, including LiDAR-based and LiDAR-camera fusion-based methods. LEGO ranked 1st at the time of submitting results to KITTI object tracking evaluation ranking board and remains 2nd at the time of submitting this paper, among all online trackers in the KITTI MOT benchmark for cars1
SMURF: Spatial Multi-Representation Fusion for 3D Object Detection with 4D Imaging Radar
Aug 02, 2023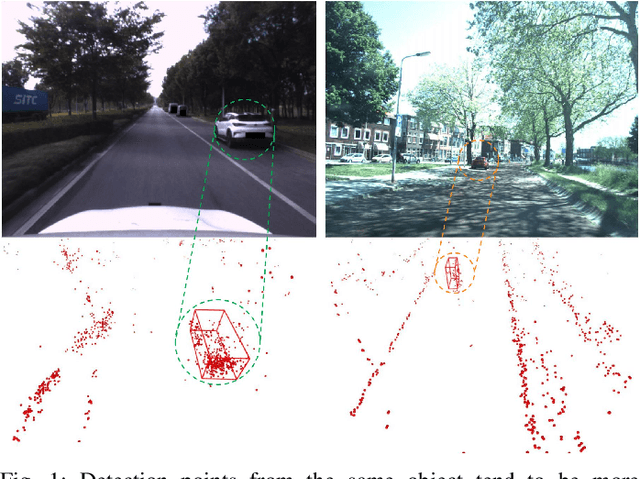
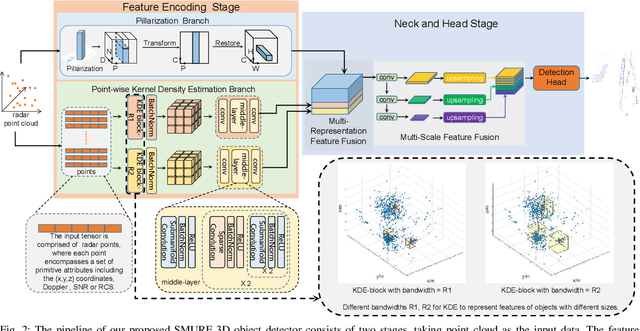

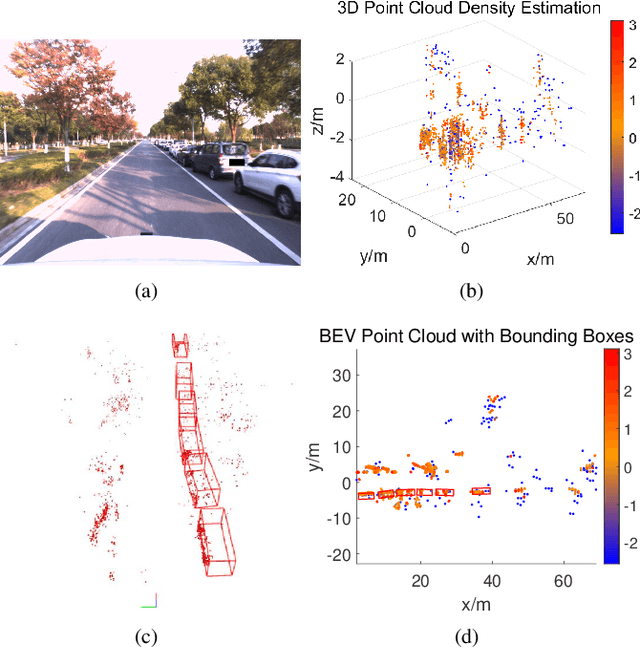
The 4D Millimeter wave (mmWave) radar is a promising technology for vehicle sensing due to its cost-effectiveness and operability in adverse weather conditions. However, the adoption of this technology has been hindered by sparsity and noise issues in radar point cloud data. This paper introduces spatial multi-representation fusion (SMURF), a novel approach to 3D object detection using a single 4D imaging radar. SMURF leverages multiple representations of radar detection points, including pillarization and density features of a multi-dimensional Gaussian mixture distribution through kernel density estimation (KDE). KDE effectively mitigates measurement inaccuracy caused by limited angular resolution and multi-path propagation of radar signals. Additionally, KDE helps alleviate point cloud sparsity by capturing density features. Experimental evaluations on View-of-Delft (VoD) and TJ4DRadSet datasets demonstrate the effectiveness and generalization ability of SMURF, outperforming recently proposed 4D imaging radar-based single-representation models. Moreover, while using 4D imaging radar only, SMURF still achieves comparable performance to the state-of-the-art 4D imaging radar and camera fusion-based method, with an increase of 1.22% in the mean average precision on bird's-eye view of TJ4DRadSet dataset and 1.32% in the 3D mean average precision on the entire annotated area of VoD dataset. Our proposed method demonstrates impressive inference time and addresses the challenges of real-time detection, with the inference time no more than 0.05 seconds for most scans on both datasets. This research highlights the benefits of 4D mmWave radar and is a strong benchmark for subsequent works regarding 3D object detection with 4D imaging radar.
LXL: LiDAR Excluded Lean 3D Object Detection with 4D Imaging Radar and Camera Fusion
Jul 07, 2023



As an emerging technology and a relatively affordable device, the 4D imaging radar has already been confirmed effective in performing 3D object detection in autonomous driving. Nevertheless, the sparsity and noisiness of 4D radar point clouds hinder further performance improvement, and in-depth studies about its fusion with other modalities are lacking. On the other hand, most of the camera-based perception methods transform the extracted image perspective view features into the bird's-eye view geometrically via "depth-based splatting" proposed in Lift-Splat-Shoot (LSS), and some researchers exploit other modals such as LiDARs or ordinary automotive radars for enhancement. Recently, a few works have applied the "sampling" strategy for image view transformation, showing that it outperforms "splatting" even without image depth prediction. However, the potential of "sampling" is not fully unleashed. In this paper, we investigate the "sampling" view transformation strategy on the camera and 4D imaging radar fusion-based 3D object detection. In the proposed model, LXL, predicted image depth distribution maps and radar 3D occupancy grids are utilized to aid image view transformation, called "radar occupancy-assisted depth-based sampling". Experiments on VoD and TJ4DRadSet datasets show that the proposed method outperforms existing 3D object detection methods by a significant margin without bells and whistles. Ablation studies demonstrate that our method performs the best among different enhancement settings.
Visual Semantic Segmentation Based on Few/Zero-Shot Learning: An Overview
Nov 13, 2022Visual semantic segmentation aims at separating a visual sample into diverse blocks with specific semantic attributes and identifying the category for each block, and it plays a crucial role in environmental perception. Conventional learning-based visual semantic segmentation approaches count heavily on large-scale training data with dense annotations and consistently fail to estimate accurate semantic labels for unseen categories. This obstruction spurs a craze for studying visual semantic segmentation with the assistance of few/zero-shot learning. The emergence and rapid progress of few/zero-shot visual semantic segmentation make it possible to learn unseen-category from a few labeled or zero-labeled samples, which advances the extension to practical applications. Therefore, this paper focuses on the recently published few/zero-shot visual semantic segmentation methods varying from 2D to 3D space and explores the commonalities and discrepancies of technical settlements under different segmentation circumstances. Specifically, the preliminaries on few/zero-shot visual semantic segmentation, including the problem definitions, typical datasets, and technical remedies, are briefly reviewed and discussed. Moreover, three typical instantiations are involved to uncover the interactions of few/zero-shot learning with visual semantic segmentation, including image semantic segmentation, video object segmentation, and 3D segmentation. Finally, the future challenges of few/zero-shot visual semantic segmentation are discussed.
RaLiBEV: Radar and LiDAR BEV Fusion Learning for Anchor Box Free Object Detection System
Nov 11, 2022Radar, the only sensor that could provide reliable perception capability in all weather conditions at an affordable cost, has been widely accepted as a key supplement to camera and LiDAR in modern advanced driver assistance systems (ADAS) and autonomous driving systems. Recent state-of-the-art works reveal that fusion of radar and LiDAR can lead to robust detection in adverse weather, such as fog. However, these methods still suffer from low accuracy of bounding box estimations. This paper proposes a bird's-eye view (BEV) fusion learning for an anchor box-free object detection system, which uses the feature derived from the radar range-azimuth heatmap and the LiDAR point cloud to estimate the possible objects. Different label assignment strategies have been designed to facilitate the consistency between the classification of foreground or background anchor points and the corresponding bounding box regressions. Furthermore, the performance of the proposed object detector can be further enhanced by employing a novel interactive transformer module. We demonstrated the superior performance of the proposed methods in this paper using the recently published Oxford Radar RobotCar (ORR) dataset. We showed that the accuracy of our system significantly outperforms the other state-of-the-art methods by a large margin.