 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Principles to Practice: A Deep Dive into AI Ethics and Regulations
Dec 06, 2024
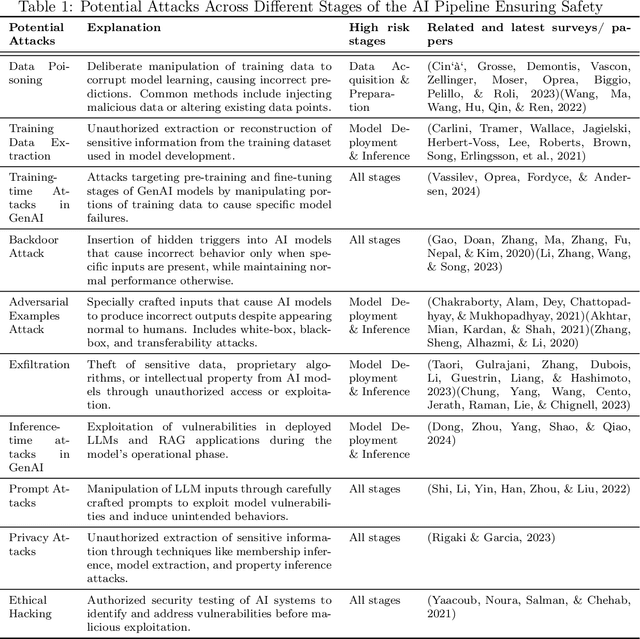
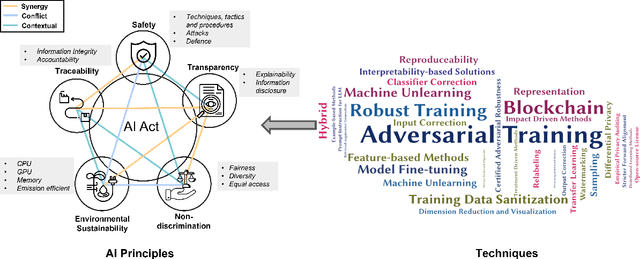

In the rapidly evolving domain of Artificial Intelligence (AI), the complex interaction between innovation and regulation has become an emerging focus of our society. Despite tremendous advancements in AI's capabilities to excel in specific tasks and contribute to diverse sectors, establishing a high degree of trust in AI-generated outputs and decisions necessitates meticulous caution and continuous oversight. A broad spectrum of stakeholders, including governmental bodies, private sector corporations, academic institutions, and individuals, have launched significant initiatives. These efforts include developing ethical guidelines for AI and engaging in vibrant discussions on AI ethics, both among AI practitioners and within the broader society. This article thoroughly analyzes the ground-breaking AI regulatory framework proposed by the European Union. It delves into the fundamental ethical principles of safety, transparency, non-discrimination, traceability, and environmental sustainability for AI developments and deployments. Considering the technical efforts and strategies undertaken by academics and industry to uphold these principles, we explore the synergies and conflicts among the five ethical principles. Through this lens, work presents a forward-looking perspective on the future of AI regulations, advocating for a harmonized approach that safeguards societal values while encouraging technological advancement.
OptLLM: Optimal Assignment of Queries to Large Language Models
May 24, 2024Large Language Models (LLMs) have garnered considerable attention owing to their remarkable capabilities, leading to an increasing number of companies offering LLMs as services. Different LLMs achieve different performance at different costs. A challenge for users lies in choosing the LLMs that best fit their needs, balancing cost and performance. In this paper, we propose a framework for addressing the cost-effective query allocation problem for LLMs. Given a set of input queries and candidate LLMs, our framework, named OptLLM, provides users with a range of optimal solutions to choose from, aligning with their budget constraints and performance preferences, including options for maximizing accuracy and minimizing cost. OptLLM predicts the performance of candidate LLMs on each query using a multi-label classification model with uncertainty estimation and then iteratively generates a set of non-dominated solutions by destructing and reconstructing the current solution. To evaluate the effectiveness of OptLLM, we conduct extensive experiments on various types of tasks, including text classification, question answering, sentiment analysis, reasoning, and log parsing. Our experimental results demonstrate that OptLLM substantially reduces costs by 2.40% to 49.18% while achieving the same accuracy as the best LLM. Compared to other multi-objective optimization algorithms, OptLLM improves accuracy by 2.94% to 69.05% at the same cost or saves costs by 8.79% and 95.87% while maintaining the highest attainable accuracy.
FAAG: Fast Adversarial Audio Generation through Interactive Attack Optimisation
Feb 11, 2022



Automatic Speech Recognition services (ASRs) inherit deep neural networks' vulnerabilities like crafted adversarial examples. Existing methods often suffer from low efficiency because the target phases are added to the entire audio sample, resulting in high demand for computational resources. This paper proposes a novel scheme named FAAG as an iterative optimization-based method to generate targeted adversarial examples quickly. By injecting the noise over the beginning part of the audio, FAAG generates adversarial audio in high quality with a high success rate timely. Specifically, we use audio's logits output to map each character in the transcription to an approximate position of the audio's frame. Thus, an adversarial example can be generated by FAAG in approximately two minutes using CPUs only and around ten seconds with one GPU while maintaining an average success rate over 85%. Specifically, the FAAG method can speed up around 60% compared with the baseline method during the adversarial example generation process. Furthermore, we found that appending benign audio to any suspicious examples can effectively defend against the targeted adversarial attack. We hope that this work paves the way for inventing new adversarial attacks against speech recognition with computational constraints.
Machine Learning Based Cyber Attacks Targeting on Controlled Information: A Survey
Feb 16, 2021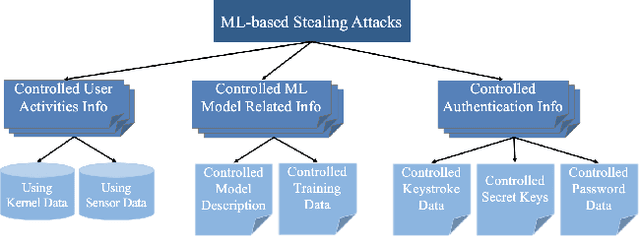

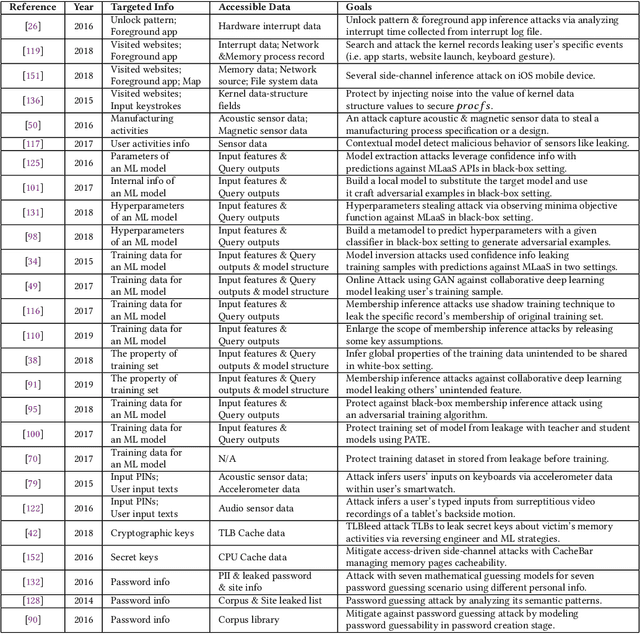
Stealing attack against controlled information, along with the increasing number of information leakage incidents, has become an emerging cyber security threat in recent years. Due to the booming development and deployment of advanced analytics solutions, novel stealing attacks utilize machine learning (ML) algorithms to achieve high success rate and cause a lot of damage. Detecting and defending against such attacks is challenging and urgent so that governments, organizations, and individuals should attach great importance to the ML-based stealing attacks. This survey presents the recent advances in this new type of attack and corresponding countermeasures. The ML-based stealing attack is reviewed in perspectives of three categories of targeted controlled information, including controlled user activities, controlled ML model-related information, and controlled authentication information. Recent publications are summarized to generalize an overarching attack methodology and to derive the limitations and future directions of ML-based stealing attacks. Furthermore, countermeasures are proposed towards developing effective protections from three aspects -- detection, disruption, and isolation.