 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInspectable AI for Science: A Research Object Approach to Generative AI Governance
Apr 13, 2026This paper introduces AI as a Research Object (AI-RO), a paradigm for governing the use of generative AI in scientific research. Instead of debating whether AI is an author or merely a tool, we propose treating AI interactions as structured, inspectable components of the research process. Under this view, the legitimacy of an AI-assisted scientific paper depends on how model use is integrated into the workflow, documented, and made accountable. Drawing on Research Object theory and FAIR principles, we propose a framework for recording model configuration, prompts, and outputs through interaction logs and metadata packaging. These properties are particularly consequential in security and privacy (S&P) research, where provenance artifacts must satisfy confidentiality constraints, integrity guarantees, and auditability requirements that generic disclosure practices do not address. We implement a lightweight writing pipeline in which a language model synthesizes human-authored structured literature review notes under explicit constraints and produces a verifiable provenance record. We present this work as a position supported by an initial demonstrative workflow, arguing that governance of generative AI in science can be implemented as structured documentation, controlled disclosure, and integrity-preserving provenance capture. Based on this example, we outline and motivate a set of necessary future developments required to make such practices practical and widely adoptable.
Scaling Reasoning Tokens via RL and Parallel Thinking: Evidence From Competitive Programming
Apr 01, 2026We study how to scale reasoning token budgets for competitive programming through two complementary approaches: training-time reinforcement learning (RL) and test-time parallel thinking. During RL training, we observe an approximately log-linear relationship between validation accuracy and the average number of generated reasoning tokens over successive checkpoints, and show two ways to shift this training trajectory: verification RL warmup raises the starting point, while randomized clipping produces a steeper trend in the observed regime. As scaling single-generation reasoning during RL quickly becomes expensive under full attention, we introduce a multi-round parallel thinking pipeline that distributes the token budget across threads and rounds of generation, verification, and refinement. We train the model end-to-end on this pipeline to match the training objective to the test-time structure. Starting from Seed-OSS-36B, the full system with 16 threads and 16 rounds per thread matches the underlying RL model's oracle pass@16 at pass@1 using 7.6 million tokens per problem on average, and surpasses GPT-5-high on 456 hard competitive programming problems from AetherCode.
Memory Retrieval in Transformers: Insights from The Encoding Specificity Principle
Jan 28, 2026While explainable artificial intelligence (XAI) for large language models (LLMs) remains an evolving field with many unresolved questions, increasing regulatory pressures have spurred interest in its role in ensuring transparency, accountability, and privacy-preserving machine unlearning. Despite recent advances in XAI have provided some insights, the specific role of attention layers in transformer based LLMs remains underexplored. This study investigates the memory mechanisms instantiated by attention layers, drawing on prior research in psychology and computational psycholinguistics that links Transformer attention to cue based retrieval in human memory. In this view, queries encode the retrieval context, keys index candidate memory traces, attention weights quantify cue trace similarity, and values carry the encoded content, jointly enabling the construction of a context representation that precedes and facilitates memory retrieval. Guided by the Encoding Specificity Principle, we hypothesize that the cues used in the initial stage of retrieval are instantiated as keywords. We provide converging evidence for this keywords-as-cues hypothesis. In addition, we isolate neurons within attention layers whose activations selectively encode and facilitate the retrieval of context-defining keywords. Consequently, these keywords can be extracted from identified neurons and further contribute to downstream applications such as unlearning.
Federated Customization of Large Models: Approaches, Experiments, and Insights
Jan 02, 2026In this article, we explore federated customization of large models and highlight the key challenges it poses within the federated learning framework. We review several popular large model customization techniques, including full fine-tuning, efficient fine-tuning, prompt engineering, prefix-tuning, knowledge distillation, and retrieval-augmented generation. Then, we discuss how these techniques can be implemented within the federated learning framework. Moreover, we conduct experiments on federated prefix-tuning, which, to the best of our knowledge, is the first trial to apply prefix-tuning in the federated learning setting. The conducted experiments validate its feasibility with performance close to centralized approaches. Further comparison with three other federated customization methods demonstrated its competitive performance, satisfactory efficiency, and consistent robustness.
NL2Repo-Bench: Towards Long-Horizon Repository Generation Evaluation of Coding Agents
Dec 14, 2025Recent advances in coding agents suggest rapid progress toward autonomous software development, yet existing benchmarks fail to rigorously evaluate the long-horizon capabilities required to build complete software systems. Most prior evaluations focus on localized code generation, scaffolded completion, or short-term repair tasks, leaving open the question of whether agents can sustain coherent reasoning, planning, and execution over the extended horizons demanded by real-world repository construction. To address this gap, we present NL2Repo Bench, a benchmark explicitly designed to evaluate the long-horizon repository generation ability of coding agents. Given only a single natural-language requirements document and an empty workspace, agents must autonomously design the architecture, manage dependencies, implement multi-module logic, and produce a fully installable Python library. Our experiments across state-of-the-art open- and closed-source models reveal that long-horizon repository generation remains largely unsolved: even the strongest agents achieve below 40% average test pass rates and rarely complete an entire repository correctly. Detailed analysis uncovers fundamental long-horizon failure modes, including premature termination, loss of global coherence, fragile cross-file dependencies, and inadequate planning over hundreds of interaction steps. NL2Repo Bench establishes a rigorous, verifiable testbed for measuring sustained agentic competence and highlights long-horizon reasoning as a central bottleneck for the next generation of autonomous coding agents.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
Hierarchical Federated Learning for Social Network with Mobility
Sep 18, 2025Federated Learning (FL) offers a decentralized solution that allows collaborative local model training and global aggregation, thereby protecting data privacy. In conventional FL frameworks, data privacy is typically preserved under the assumption that local data remains absolutely private, whereas the mobility of clients is frequently neglected in explicit modeling. In this paper, we propose a hierarchical federated learning framework based on the social network with mobility namely HFL-SNM that considers both data sharing among clients and their mobility patterns. Under the constraints of limited resources, we formulate a joint optimization problem of resource allocation and client scheduling, which objective is to minimize the energy consumption of clients during the FL process. In social network, we introduce the concepts of Effective Data Coverage Rate and Redundant Data Coverage Rate. We analyze the impact of effective data and redundant data on the model performance through preliminary experiments. We decouple the optimization problem into multiple sub-problems, analyze them based on preliminary experimental results, and propose Dynamic Optimization in Social Network with Mobility (DO-SNM) algorithm. Experimental results demonstrate that our algorithm achieves superior model performance while significantly reducing energy consumption, compared to traditional baseline algorithms.
Assessing GPT Performance in a Proof-Based University-Level Course Under Blind Grading
May 19, 2025



As large language models (LLMs) advance, their role in higher education, particularly in free-response problem-solving, requires careful examination. This study assesses the performance of GPT-4o and o1-preview under realistic educational conditions in an undergraduate algorithms course. Anonymous GPT-generated solutions to take-home exams were graded by teaching assistants unaware of their origin. Our analysis examines both coarse-grained performance (scores) and fine-grained reasoning quality (error patterns). Results show that GPT-4o consistently struggles, failing to reach the passing threshold, while o1-preview performs significantly better, surpassing the passing score and even exceeding the student median in certain exercises. However, both models exhibit issues with unjustified claims and misleading arguments. These findings highlight the need for robust assessment strategies and AI-aware grading policies in education.
Privacy Meets Explainability: Managing Confidential Data and Transparency Policies in LLM-Empowered Science
Apr 14, 2025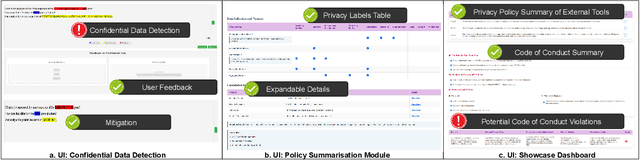


As Large Language Models (LLMs) become integral to scientific workflows, concerns over the confidentiality and ethical handling of confidential data have emerged. This paper explores data exposure risks through LLM-powered scientific tools, which can inadvertently leak confidential information, including intellectual property and proprietary data, from scientists' perspectives. We propose "DataShield", a framework designed to detect confidential data leaks, summarize privacy policies, and visualize data flow, ensuring alignment with organizational policies and procedures. Our approach aims to inform scientists about data handling practices, enabling them to make informed decisions and protect sensitive information. Ongoing user studies with scientists are underway to evaluate the framework's usability, trustworthiness, and effectiveness in tackling real-world privacy challenges.
Adaptive Clipping for Privacy-Preserving Few-Shot Learning: Enhancing Generalization with Limited Data
Mar 27, 2025In the era of data-driven machine-learning applications, privacy concerns and the scarcity of labeled data have become paramount challenges. These challenges are particularly pronounced in the domain of few-shot learning, where the ability to learn from limited labeled data is crucial. Privacy-preserving few-shot learning algorithms have emerged as a promising solution to address such pronounced challenges. However, it is well-known that privacy-preserving techniques often lead to a drop in utility due to the fundamental trade-off between data privacy and model performance. To enhance the utility of privacy-preserving few-shot learning methods, we introduce a novel approach called Meta-Clip. This technique is specifically designed for meta-learning algorithms, including Differentially Private (DP) model-agnostic meta-learning, DP-Reptile, and DP-MetaSGD algorithms, with the objective of balancing data privacy preservation with learning capacity maximization. By dynamically adjusting clipping thresholds during the training process, our Adaptive Clipping method provides fine-grained control over the disclosure of sensitive information, mitigating overfitting on small datasets and significantly improving the generalization performance of meta-learning models. Through comprehensive experiments on diverse benchmark datasets, we demonstrate the effectiveness of our approach in minimizing utility degradation, showcasing a superior privacy-utility trade-off compared to existing privacy-preserving techniques. The adoption of Adaptive Clipping represents a substantial step forward in the field of privacy-preserving few-shot learning, empowering the development of secure and accurate models for real-world applications, especially in scenarios where there are limited data availability.