 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Federated Learning for Social Network with Mobility
Sep 18, 2025Federated Learning (FL) offers a decentralized solution that allows collaborative local model training and global aggregation, thereby protecting data privacy. In conventional FL frameworks, data privacy is typically preserved under the assumption that local data remains absolutely private, whereas the mobility of clients is frequently neglected in explicit modeling. In this paper, we propose a hierarchical federated learning framework based on the social network with mobility namely HFL-SNM that considers both data sharing among clients and their mobility patterns. Under the constraints of limited resources, we formulate a joint optimization problem of resource allocation and client scheduling, which objective is to minimize the energy consumption of clients during the FL process. In social network, we introduce the concepts of Effective Data Coverage Rate and Redundant Data Coverage Rate. We analyze the impact of effective data and redundant data on the model performance through preliminary experiments. We decouple the optimization problem into multiple sub-problems, analyze them based on preliminary experimental results, and propose Dynamic Optimization in Social Network with Mobility (DO-SNM) algorithm. Experimental results demonstrate that our algorithm achieves superior model performance while significantly reducing energy consumption, compared to traditional baseline algorithms.
Towards Communication-efficient Federated Learning via Sparse and Aligned Adaptive Optimization
May 28, 2024



Adaptive moment estimation (Adam), as a Stochastic Gradient Descent (SGD) variant, has gained widespread popularity in federated learning (FL) due to its fast convergence. However, federated Adam (FedAdam) algorithms suffer from a threefold increase in uplink communication overhead compared to federated SGD (FedSGD) algorithms, which arises from the necessity to transmit both local model updates and first and second moment estimates from distributed devices to the centralized server for aggregation. Driven by this issue, we propose a novel sparse FedAdam algorithm called FedAdam-SSM, wherein distributed devices sparsify the updates of local model parameters and moment estimates and subsequently upload the sparse representations to the centralized server. To further reduce the communication overhead, the updates of local model parameters and moment estimates incorporate a shared sparse mask (SSM) into the sparsification process, eliminating the need for three separate sparse masks. Theoretically, we develop an upper bound on the divergence between the local model trained by FedAdam-SSM and the desired model trained by centralized Adam, which is related to sparsification error and imbalanced data distribution. By minimizing the divergence bound between the model trained by FedAdam-SSM and centralized Adam, we optimize the SSM to mitigate the learning performance degradation caused by sparsification error. Additionally, we provide convergence bounds for FedAdam-SSM in both convex and non-convex objective function settings, and investigate the impact of local epoch, learning rate and sparsification ratio on the convergence rate of FedAdam-SSM. Experimental results show that FedAdam-SSM outperforms baselines in terms of convergence rate (over 1.1$\times$ faster than the sparse FedAdam baselines) and test accuracy (over 14.5\% ahead of the quantized FedAdam baselines).
Trustworthy DNN Partition for Blockchain-enabled Digital Twin in Wireless IIoT Networks
May 28, 2024



Digital twin (DT) has emerged as a promising solution to enhance manufacturing efficiency in industrial Internet of Things (IIoT) networks. To promote the efficiency and trustworthiness of DT for wireless IIoT networks, we propose a blockchain-enabled DT (B-DT) framework that employs deep neural network (DNN) partitioning technique and reputation-based consensus mechanism, wherein the DTs maintained at the gateway side execute DNN inference tasks using the data collected from their associated IIoT devices. First, we employ DNN partitioning technique to offload the top-layer DNN inference tasks to the access point (AP) side, which alleviates the computation burden at the gateway side and thereby improves the efficiency of DNN inference. Second, we propose a reputation-based consensus mechanism that integrates Proof of Work (PoW) and Proof of Stake (PoS). Specifically, the proposed consensus mechanism evaluates the off-chain reputation of each AP according to its computation resource contributions to the DNN inference tasks, and utilizes the off-chain reputation as a stake to adjust the block generation difficulty. Third, we formulate a stochastic optimization problem of communication resource (i.e., partition point) and computation resource allocation (i.e., computation frequency of APs for top-layer DNN inference and block generation) to minimize system latency under the time-varying channel state and long-term constraints of off-chain reputation, and solve the problem using Lyapunov optimization method. Experimental results show that the proposed dynamic DNN partitioning and resource allocation (DPRA) algorithm outperforms the baselines in terms of reducing the overall latency while guaranteeing the trustworthiness of the B-DT system.
Mobility-Aware Joint User Scheduling and Resource Allocation for Low Latency Federated Learning
Jul 18, 2023


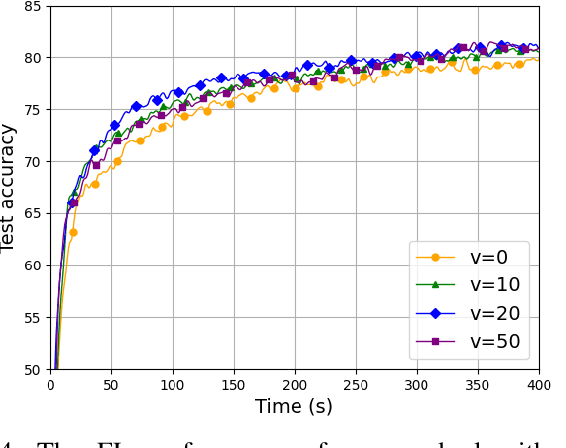
As an efficient distributed machine learning approach, Federated learning (FL) can obtain a shared model by iterative local model training at the user side and global model aggregating at the central server side, thereby protecting privacy of users. Mobile users in FL systems typically communicate with base stations (BSs) via wireless channels, where training performance could be degraded due to unreliable access caused by user mobility. However, existing work only investigates a static scenario or random initialization of user locations, which fail to capture mobility in real-world networks. To tackle this issue, we propose a practical model for user mobility in FL across multiple BSs, and develop a user scheduling and resource allocation method to minimize the training delay with constrained communication resources. Specifically, we first formulate an optimization problem with user mobility that jointly considers user selection, BS assignment to users, and bandwidth allocation to minimize the latency in each communication round. This optimization problem turned out to be NP-hard and we proposed a delay-aware greedy search algorithm (DAGSA) to solve it. Simulation results show that the proposed algorithm achieves better performance than the state-of-the-art baselines and a certain level of user mobility could improve training performance.