 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustworthy DNN Partition for Blockchain-enabled Digital Twin in Wireless IIoT Networks
May 28, 2024



Digital twin (DT) has emerged as a promising solution to enhance manufacturing efficiency in industrial Internet of Things (IIoT) networks. To promote the efficiency and trustworthiness of DT for wireless IIoT networks, we propose a blockchain-enabled DT (B-DT) framework that employs deep neural network (DNN) partitioning technique and reputation-based consensus mechanism, wherein the DTs maintained at the gateway side execute DNN inference tasks using the data collected from their associated IIoT devices. First, we employ DNN partitioning technique to offload the top-layer DNN inference tasks to the access point (AP) side, which alleviates the computation burden at the gateway side and thereby improves the efficiency of DNN inference. Second, we propose a reputation-based consensus mechanism that integrates Proof of Work (PoW) and Proof of Stake (PoS). Specifically, the proposed consensus mechanism evaluates the off-chain reputation of each AP according to its computation resource contributions to the DNN inference tasks, and utilizes the off-chain reputation as a stake to adjust the block generation difficulty. Third, we formulate a stochastic optimization problem of communication resource (i.e., partition point) and computation resource allocation (i.e., computation frequency of APs for top-layer DNN inference and block generation) to minimize system latency under the time-varying channel state and long-term constraints of off-chain reputation, and solve the problem using Lyapunov optimization method. Experimental results show that the proposed dynamic DNN partitioning and resource allocation (DPRA) algorithm outperforms the baselines in terms of reducing the overall latency while guaranteeing the trustworthiness of the B-DT system.
Robust Model Aggregation for Heterogeneous Federated Learning: Analysis and Optimizations
May 11, 2024



Conventional synchronous federated learning (SFL) frameworks suffer from performance degradation in heterogeneous systems due to imbalanced local data size and diverse computing power on the client side. To address this problem, asynchronous FL (AFL) and semi-asynchronous FL have been proposed to recover the performance loss by allowing asynchronous aggregation. However, asynchronous aggregation incurs a new problem of inconsistency between local updates and global updates. Motivated by the issues of conventional SFL and AFL, we first propose a time-driven SFL (T-SFL) framework for heterogeneous systems. The core idea of T-SFL is that the server aggregates the models from different clients, each with varying numbers of iterations, at regular time intervals. To evaluate the learning performance of T-SFL, we provide an upper bound on the global loss function. Further, we optimize the aggregation weights to minimize the developed upper bound. Then, we develop a discriminative model selection (DMS) algorithm that removes local models from clients whose number of iterations falls below a predetermined threshold. In particular, this algorithm ensures that each client's aggregation weight accurately reflects its true contribution to the global model update, thereby improving the efficiency and robustness of the system. To validate the effectiveness of T-SFL with the DMS algorithm, we conduct extensive experiments using several popular datasets including MNIST, Cifar-10, Fashion-MNIST, and SVHN. The experimental results demonstrate that T-SFL with the DMS algorithm can reduce the latency of conventional SFL by 50\%, while achieving an average 3\% improvement in learning accuracy over state-of-the-art AFL algorithms.
Blockchain Assisted Decentralized Federated Learning (BLADE-FL): Performance Analysis and Resource Allocation
Jan 18, 2021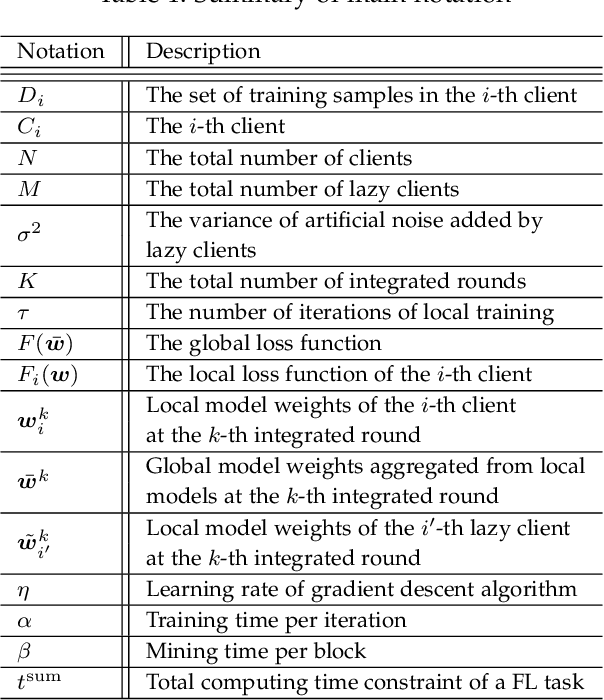
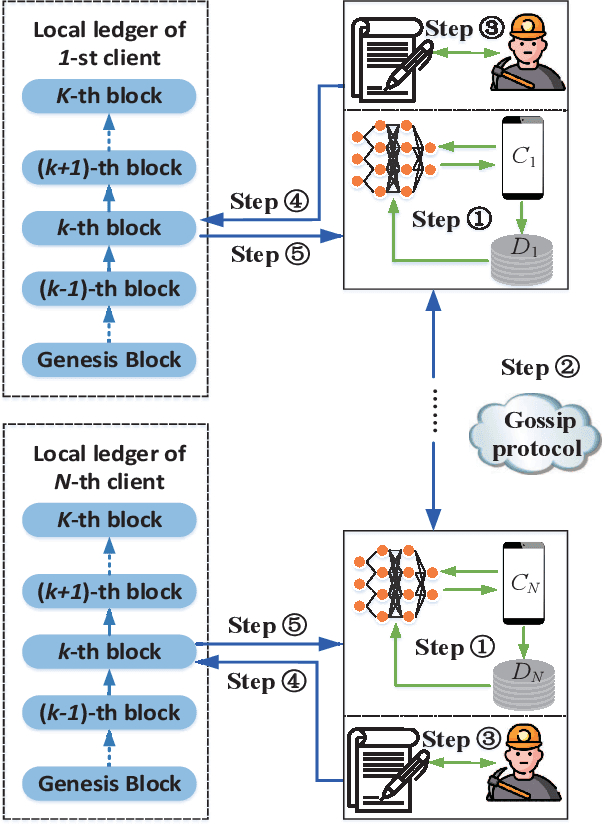
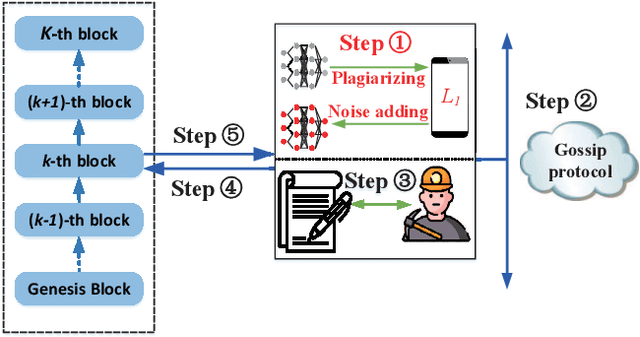
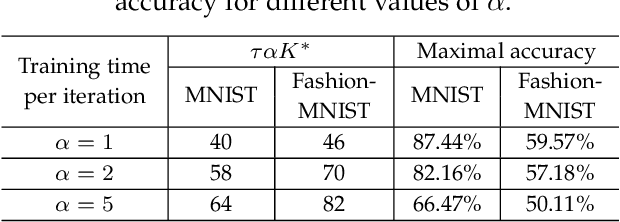
Federated learning (FL), as a distributed machine learning paradigm, promotes personal privacy by clients' processing raw data locally. However, relying on a centralized server for model aggregation, standard FL is vulnerable to server malfunctions, untrustworthy server, and external attacks. To address this issue, we propose a decentralized FL framework by integrating blockchain into FL, namely, blockchain assisted decentralized federated learning (BLADE-FL). In a round of the proposed BLADE-FL, each client broadcasts its trained model to other clients, competes to generate a block based on the received models, and then aggregates the models from the generated block before its local training of the next round. We evaluate the learning performance of BLADE-FL, and develop an upper bound on the global loss function. Then we verify that this bound is convex with respect to the number of overall rounds K, and optimize the computing resource allocation for minimizing the upper bound. We also note that there is a critical problem of training deficiency, caused by lazy clients who plagiarize others' trained models and add artificial noises to disguise their cheating behaviors. Focusing on this problem, we explore the impact of lazy clients on the learning performance of BLADE-FL, and characterize the relationship among the optimal K, the learning parameters, and the proportion of lazy clients. Based on the MNIST and Fashion-MNIST datasets, we show that the experimental results are consistent with the analytical ones. To be specific, the gap between the developed upper bound and experimental results is lower than 5%, and the optimized K based on the upper bound can effectively minimize the loss function.
Blockchain Assisted Decentralized Federated Learning with Lazy Clients
Dec 02, 2020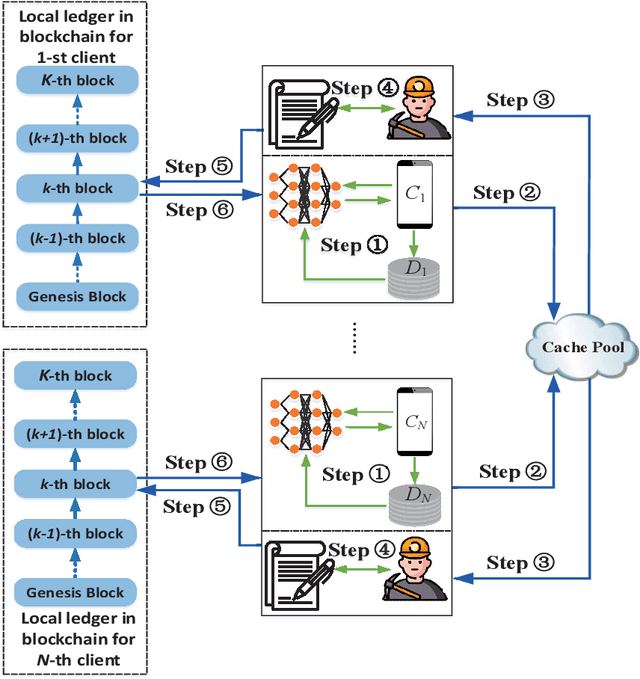
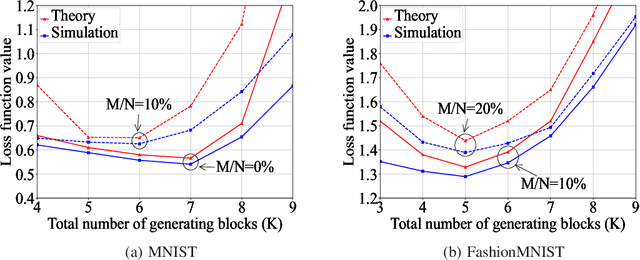
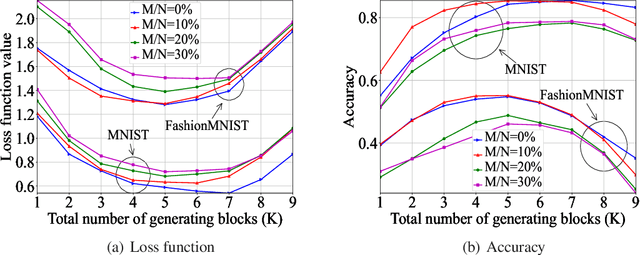
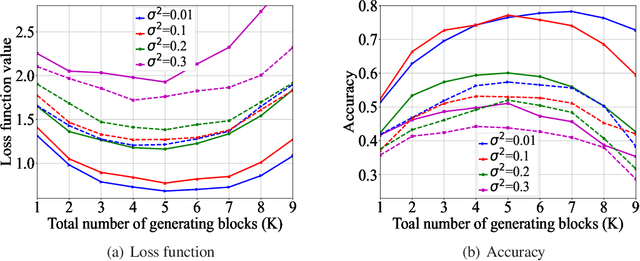
Federated learning (FL), as a distributed machine learning approach, has drawn a great amount of attention in recent years. FL shows an inherent advantage in privacy preservation, since users' raw data are processed locally. However, it relies on a centralized server to perform model aggregation. Therefore, FL is vulnerable to server malfunctions and external attacks. In this paper, we propose a novel framework by integrating blockchain into FL, namely, blockchain assisted decentralized federated learning (BLADE-FL), to enhance the security of FL. The proposed BLADE-FL has a good performance in terms of privacy preservation, tamper resistance, and effective cooperation of learning. However, it gives rise to a new problem of training deficiency, caused by lazy clients who plagiarize others' trained models and add artificial noises to conceal their cheating behaviors. To be specific, we first develop a convergence bound of the loss function with the presence of lazy clients and prove that it is convex with respect to the total number of generated blocks $K$. Then, we solve the convex problem by optimizing $K$ to minimize the loss function. Furthermore, we discover the relationship between the optimal $K$, the number of lazy clients, and the power of artificial noises used by lazy clients. We conduct extensive experiments to evaluate the performance of the proposed framework using the MNIST and Fashion-MNIST datasets. Our analytical results are shown to be consistent with the experimental results. In addition, the derived optimal $K$ achieves the minimum value of loss function, and in turn the optimal accuracy performance.